一、背景
面對訂單資料紙質檔案或圖檔,僅靠人眼識别的話效率很低,需引入機器學習來識别和解析圖檔以提高效率。目前市面上已有收費的圖檔識别服務,包括阿裡、百度等,識别效果較好,但針對訂單類圖檔,不僅要關注圖檔上的文字,還要關注文字所在的行列,來分出每條資料和資料詳細字段。
本文主要介紹一種針對訂單類圖檔識别結果進行行列解析的抽象流程和方案,幫助提高開發效率。
注:本文隻提供思路,不提供源碼。另外,本文不介紹人工智能圖檔識别,感興趣的同學可以上網查詢相關資料。
二、解析流程
對于圖像處理,opencv算是比較優秀的工具,是以将其選做本文圖像處理首選軟體。
- 為了使圖檔識别率更高,需要先做圖檔矯正,這裡采用較為簡單的霍夫變換加去噪聲點算法矯正圖檔。
- 圖檔矯正後,調用圖檔識别服務擷取結果,一般結果格式包括響應碼、錯誤描述、文字塊清單(文字和四點坐标)等。
- 然後使用抽象的俄羅斯方塊法根據識别結果擷取行列資訊。
- 最後根據行列資訊組裝每一行資料并顯示。
三、細節處理
3.1 opencv安裝概要
opencv安裝,本文隻做簡單提示,不展開介紹,以後有時間單獨發文。
1)windows
- 下載下傳編譯好的包, https://opencv.org/releases/
- 解壓縮到自定義檔案夾。
2)linux
- 推薦使用ubuntu,并且最好是全新的系統,因為opencv會依賴很多包,對版本要求也高,解決沖突會很麻煩。
- 下載下傳源碼
- 安裝依賴包
- 編譯安裝
我們使用java調用opencv,這裡需要安裝擷取到開發包,windows為opencv_javaxxx.dll,linux為libopencv_javaxxx.so,程式初始化時需要加載到jvm。詳細代碼如下:
System.load(PropertieUtil.getPropertie("這裡是dll或so的完整路徑"); 3.2 圖檔矯正
3.2.1 矯正探索
圖檔矯正探索之路較為艱辛,起初我們想了一個比較簡單的方案:
- 先調用圖檔識别服務,擷取到結果。
- 然後根據每一個字塊的四角坐标判斷出每個字塊的傾斜角。
- 再根據去燥算法算出平均的傾斜角。
理論上這個方案是可行的,但實踐證明我們錯了,因為圖檔識别服務傳回的坐标圖檔不準确,多數圖檔算出的結果都是錯誤的。
經查發現霍夫變換有可能解決這個問題,于是開始嘗試學習霍夫變換和去燥算法,最終發現可行,并抽象出公共方法,僅需簡單配置一些參數就能完成矯正。
圖檔矯正分為兩步:
- 第一步:正反矯正,判斷圖檔傾斜角度是90°、180°、270°、0°,這個通過數學方法是無法判斷的,需要引用機器學習。
- 第二步:角度微調,一般為确定圖檔是正的,且傾斜角度在+-30°左右。
需要注意的是,上面說的辦法不可能通過一套參數來對所有圖檔進行微調,但線上資料證明,針對一類圖檔,一套參數基本能讓大多數圖檔都矯正正确。
3.2.2 霍夫變換概要
霍夫變換是數學界經典空間變換算法,用于檢測直線,通過大量檢測到的直線的斜率就能計算出圖檔傾斜角度。先進行二值化和邊緣檢測再進行霍夫變換效果更佳,詳細算法内容請自行搜尋,本文不展開。
3.2.3 去噪聲點算法
基本公式:
上限=均值+n*标準差
下限=均值-n*标準差
其中n取值一般為1-4,數值越大表示篩選率越高。
最後再将符合的資料求均值。
核心代碼如下:
/**
* 利用标準差篩選
* @param values
* @return
*/
private static double[] calcBestCornList(double[] values) {
// 計算标準差
StandardDeviation variance = new StandardDeviation();
double evaluate = variance.evaluate(values);
Mean mean = new Mean();
double meanValue = mean.evaluate(values);
double biggerValue = meanValue + CHOOSE_POWER * evaluate;
double smallerValue = meanValue - CHOOSE_POWER * evaluate;
List<Double> selected = Lists.newArrayList();
for (double value : values) {
if (value >= smallerValue && value <= biggerValue) {
selected.add(value);
}
}
double[] selectedValue = new double[selected.size()];
for (int i = 0; i < selected.size(); i++) {
selectedValue[i] = selected.get(i);
}
logger.info("占比:{}%,篩選後角度數組:{}", (selectedValue.length / (float)values.length) * 100F, selected);
return selectedValue;
} 3.2.4 霍夫變化抽象封裝
基本流程:
- 定義相關參數
- 讀取圖檔
- 灰階二值化處理
- 使用opencv畫出輪廓
- 根據參數要求多次畫霍夫變換線,直到線數量滿足參數為止
- 周遊畫出的線,分出橫線和豎線,根據配置計算出每條線的角度
- 使用去噪聲算法(需要根據非0數自動重複計算)算出平均傾斜角度
- 使用opencv旋轉圖檔
核心代碼如下:
/**
* 矯正圖檔,通過霍夫變換矯正
* @param oldImg 原始圖檔
* @param rotateParam 旋轉參數
* @return
*/
public static String rotateHoughLines(File oldFile, String oldImg, RotateParam rotateParam, String cid, String bankCode) throws Exception {
Mat src= Imgcodecs.imread(oldFile.getAbsolutePath());
//讀取圖像到矩陣中
if(src.empty()){
throw new Exception("no file " + oldFile.getAbsolutePath());
}
// 用于計算的圖檔矩陣
Mat mathImg = src.clone();
// 灰階化
Imgproc.cvtColor(src, mathImg, Imgproc.COLOR_BGR2GRAY);
logger.info("二值化完成");
// 擷取輪廓
Imgproc.Canny(src, mathImg, rotateParam.getCvtThreshould1(), rotateParam.getCvtThreshould2());
logger.info("輪廓完成");
// 霍夫變換擷取角度,詳細代碼略
double corn = houghLines(mathImg, rotateParam, cid);
logger.info("霍夫變換完成,角度:{}", corn);
if(corn == 0) {
return oldImg;
}
return rotateOpenv(oldFile, corn, cid, bankCode);
} 3.3 常用圖檔識别方案
阿裡、百度都有提供圖檔識别服務,如果有實力也可以自己實作,不過不建議自研,因為樣本需求量巨大,時間成本過高。
3.4 識别結果解析
3.4.1 探索之路
本章節為本文重點内容,因為前文所提到的都是較為基礎的服務和算法,大量開發内容都在本章。前期要開發的訂單圖檔類型巨量(大于100種),每一類圖檔差別很大,我們有幾個人分類型開發,但每個人所用的方法都不同,且張三開發出來的李四看不懂,不過畢竟面對的是圖檔,比較抽象,這是可以了解的。
開發一段時間後我們發現了問題:每種類型最快也要一周才能開發完成,而且解析成功率極低。開發出一套抽象的方法來把行列資料提取出來迫在眉睫。
通過調研發現,大家常用兩種方法來提取行列資料,分别為坐标法和标題法,但這兩種方法解析率都不高。經過幾周思考,終于想出了一套較好的方法,命名為俄羅斯方塊法,最終解決了問題。
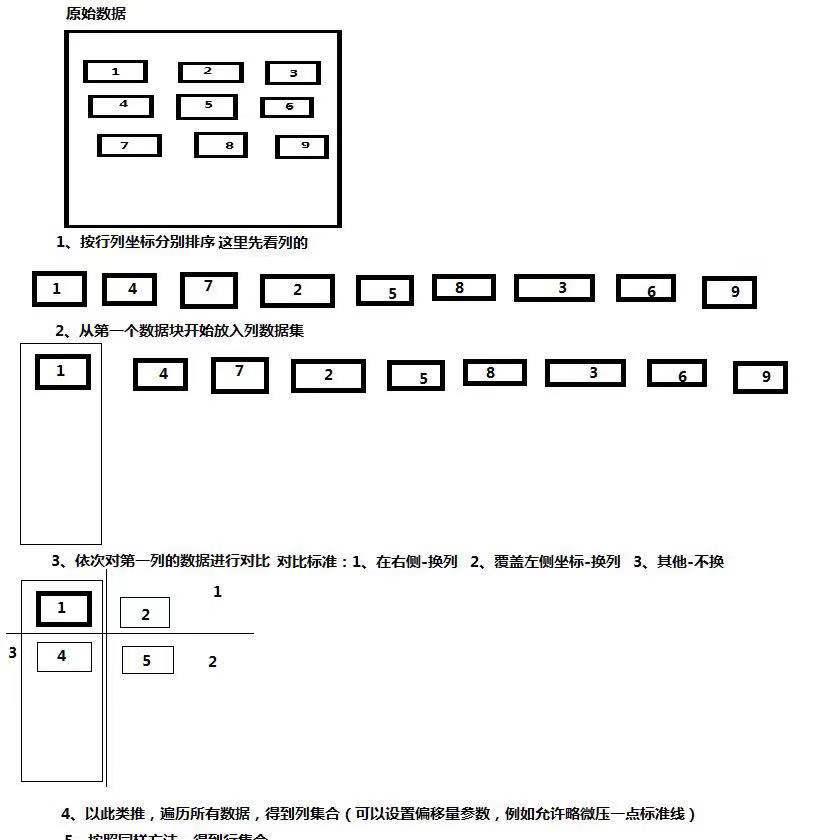
3.4.2 俄羅斯方塊法
思路概要:
- 拿到識别結果資料。
- 先把所有資料的y坐标進行排序。
- 周遊排序結果,先把第一條放入第一列結果集中。
- 從第二條開始和第一列結果集對比。
- 對比方法:如果在第一列結果集其中一條資料的右側,則認為是新列;如果在y軸方法和第一列結果集中某些資料重疊了,則認為是新列。
- 如果以上兩條都不是,則認為本條資料還在目前列中,放入第一列結果集。
- 以此類推,繼續對比,直到對比到最後一列最後一條資料。
- 按照上述方法,反過來,以x軸為标準,能夠得到行結果集。
思路圖如下:
概要代碼如下:
// 按照最左上角的x坐标排序
OcrWordInfo[] sortL = NoTableParseResult.ParseUtil.bubbleSortX(ocrResponse.getPrism_wordsInfo(), false);
NoTableParseResult ntpr = new NoTableParseResult(param);
ntpr.setHeight(converImg.height());
ntpr.setWight(converImg.width());
for (int i = 0; i < sortL.length; i++) {
// 目前要比較的資料
OcrWordInfo ocrWordInfo = sortL[i];
// 處理目前列資料
ntpr.getUtil().testCurColData(ocrWordInfo);
}
// 處理最後一列
ntpr.lastCol();
/**
* 判斷是否為下一列,并處理
* @param ocrWordInfo
* @return
*/
public void testCurColData(OcrWordInfo ocrWordInfo) {
// 周遊目前列已存在的所有資料
int size = this.test.getCol().size();
if(size == 0) {
this.test.addCol(ocrWordInfo);
return;
}
for (int i = 0; i < size; i++) {
OcrWordInfo temp = this.test.getCol().get(i);
// 最右邊的資料
int x1 = temp.getPos().get(1).getX();
int x2 = temp.getPos().get(2).getX();
// 目前資料最左邊
int xx0 = ocrWordInfo.getPos().get(0).getX();
int xx3 = ocrWordInfo.getPos().get(3).getX();
int threholdx = this.test.param == null ? 0 : this.test.param.getCoverColXThrehold();
if(xx0 >= (x1 - threholdx) && xx0 >= (x2 - threholdx) && xx3 >= (x1 - threholdx) && xx3 >= (x2 - threholdx)) {
// 目前資料在右邊,說明換列了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
this.test.colAdd();
this.test.addCol(ocrWordInfo);
return;
} else {
// 判斷是否覆寫坐标
int y0 = temp.getPos().get(0).getY();
int y3 = temp.getPos().get(3).getY();
int yy0 = ocrWordInfo.getPos().get(0).getY();
int yy3 = ocrWordInfo.getPos().get(3).getY();
int threhold = (int)Math.round((y3 - y0) * (this.test.param == null ? 0.25 : this.test.param.getCoverThrehold()));
if(!(yy3 <= (y0 + threhold) || yy0 >= (y3 - threhold))) {
// 目前清單資料重疊,說明換列了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
this.test.colAdd();
this.test.addCol(ocrWordInfo);
return;
}
}
}
// 執行到這說明沒覆寫
this.test.addCol(ocrWordInfo);
} 3.4.3 解析行資料技巧
技巧總結:
1)俄羅斯方塊法提供去除幹擾項的參數,可以根據圖檔特點去除上下左右幹擾資料來減少串行列現象。
2)解析資料大緻有兩種方法
- 根據标題列号來判斷資料,這種方法不通用,簡單、規範的圖檔識别率高,但無法适配亂的圖。
- 把每一行資料以間隔符号分割拼到一起,使用正規表達式來‘扣’資料。因為一般同類型訂單圖檔,關鍵字段的位置是有特點的,例如金額格式、借貸方向、日期等,這種方法通用,但識别率不高。
具體使用哪種方法,還需要根據圖檔特點進行取舍。
3)俄羅斯方塊法提供一些微調參數,用于适配一些特殊場景,例如換行列閥值之類的。
4)中間需要儲存一些過程圖檔,例如矯正過程的若幹張圖、俄羅斯方塊法識别結果的連線圖等。畢竟這種項目在查問題時靠日志是沒用的,還得靠這些中間圖才能更快查到問題。
四、總結
本文提到的方案不能完全解決所有訂單類圖檔解析問題,可以做到新手快速入門快速開發,如果您有更好思路歡迎交流。
作者:劉鵬飛
來源:宜信技術學院
![查找算法之二分查找查找算法之二分查找[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)