本文翻譯自 https://labs.spotify.com/2015/01/09/personalization-at-spotify-using-cassandra/
在Spotify我們有超過6000萬的活躍使用者,他們可以通路超過3000萬首歌曲的龐大曲庫。使用者可以關注成千上萬的藝術家和上百個好友,并建立自己的音樂圖表。在我們的廣告平台上,使用者還可以通過體驗各種音樂宣傳活動(專輯發行,藝人推廣)發現新的和現有的内容。這些選項增加了使用者的自主權和參與度。目前,使用者在平台上已建立了超過15億播放清單,并且,僅去年一年就播放了超過70億小時的音樂。
但有時豐富的選擇也讓我們的使用者感到些許困惑。如何從超過10億個播放清單中找到适合鍛煉時聽的播放清單?如何發現與自己品味契合的新專輯?通過在平台上提供個性化的使用者體驗,我們幫助使用者發現和體驗相關内容。
個性化的使用者體驗包括在不同的場景中學習使用者的喜好和厭惡。一個喜歡金屬類音樂的人在給孩子播放睡前音樂時,可能不想收到金屬類型專輯的公告。這時,給他們推薦一張兒童音樂專輯可能更為貼切。但是這個經驗對另一個不介意在任何情況下接受金屬類型專輯推薦的金屬類型聽衆可能毫無意義。這兩個使用者有相似的聽音樂習慣,但可能有不同偏好。根據他們在不同場景下的偏好,提供在Spotify上的個性化體驗,可以讓他們更加投入。
基于以上對産品的了解,我們着手建立了一個個性化系統,它可以分析實時和曆史資料,分别了解使用者的場景和行為。随着時間的推移和規模的擴大,我們基于一套靈活的架建構立了自己的個性化技術棧,并且确信我們使用了正确的工具來解決問題。
整體架構
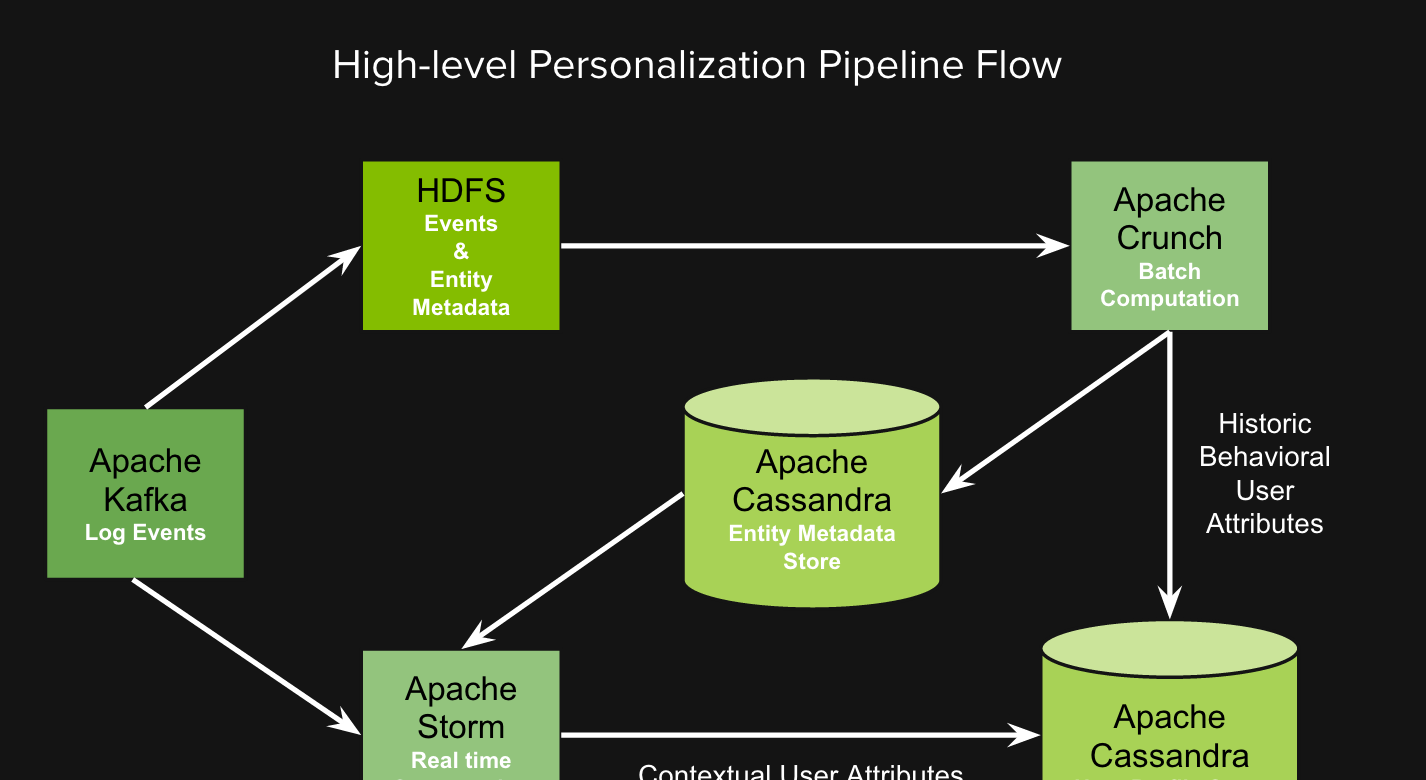
在我們的系統中,使用Kafka收集日志,使用Storm做實時事件處理,使用Crunch在Hadoop上運作批量map-reduce任務,使用Cassandra存儲使用者畫像(user profile)屬性和關于播放清單、藝人等實體的中繼資料。
下圖中,日志由Kafka producer發出後,運作在不同的服務上,并且把不同類型的事件(例如歌曲完成、廣告展示的投遞)發送到Kafka broker。系統中有兩組Kafka consumer,分别訂閱不同的topic,消費事件:
- Hadoop Consumer将事件寫入HDFS。之後HDFS上的原始日志會在Crunch中進行處理,去除重複事件,過濾掉不需要的字段,并将記錄轉化為Avro格式。
- 運作于Storm topology中的Spouts Consumer對事件流做實時計算。
系統中也有其他的Crunch pipeline接收和生成不同實體的中繼資料(類型、節奏等)。這些記錄存儲在HDFS中,并使用Crunch導出到Cassandra,以便在Storm pipeline中進行實時查找。我們将存儲實體中繼資料的Cassandra叢集稱為實體中繼資料存儲(EMS)。
Storm pipeline處理來自Kafka的原始日志事件,過濾掉不需要的事件,用從EMS擷取的中繼資料裝飾實體,按使用者分組,并通過某種聚合和派生的算法組合來确定使用者級屬性。合并後的這些使用者屬性描述了使用者畫像,它們存儲在Cassandra叢集中,我們稱之為使用者畫像存儲(UPS)。
為何Cassandra适合?
由于UPS是我們個性化系統的核心,在本文中,我們将詳細說明為什麼選擇Cassandra作為存儲。當我們開始為UPS購買不同的存儲解決方案時,我們希望有一個解決方案可以:
- 水準擴充
- 支援複制—最好跨站點
- 低延遲。可以為此犧牲一緻性,因為我們不執行事務
- 能夠支援Crunch的批量資料寫入和Storm的流資料寫入
- 能為實體中繼資料的不同用例模組化不同的資料模式,因為我們不想為EMS開發另一個解決方案,這會增加我們的營運成本。
我們考慮了在Spotify常用到的各種解決方案,如Memcached、Sparkey和Cassandra。隻有Cassandra符合所有這些要求。
Cassandra随着叢集中節點數量的增加而擴充的能力得到了高度的宣傳,并且有很好的文檔支援,是以我們相信它對于我們的場景來說是一個很好的選擇。我們的項目從相對較小的資料量開始,但現在已經從幾GB增長到100 GB以上(譯者注:原文如此,可能是筆誤?歡迎有了解内情的讀者釋疑)。在這一過程中,我們很容易通過增加叢集中的節點數量來擴充存儲容量;例如,我們最近将叢集的規模增加了一倍,并觀察到延遲(中位數和99分位)幾乎減少了一半。
此外,Cassandra的複制和可用性特性也提供了巨大的幫助。雖然我們不幸遇到了一些由于GC或硬體問題導緻節點崩潰的情況,但是我們通路Cassandra叢集的服務幾乎沒有受到影響,因為所有資料都在其他節點上可用,而且用戶端驅動程式足夠智能,可以透明地進行failover。
跨節點複制
Spotify在全球近60個國家提供服務。我們的後端服務運作在北美的兩個資料中心和歐洲的兩個資料中心。為了確定在任何一個資料中心發生故障時,我們的個性化系統仍能為使用者提供服務,我們必須能夠在至少兩個資料中心存儲資料。
我們目前在個性化叢集中使用NetworkReplicationStrategy在歐盟資料中心和北美資料中心之間複制資料。這允許使用者通路離自己最近的Spotify資料中心中的資料,并提供如上所述的備援功能。
雖然我們還沒有發生任何導緻整個資料中心中的整個叢集當機的事件,但我們已經執行了從一個資料中心到另一個資料中心的使用者流量遷移測試,Cassandra完美地處理了從一個站點處理來自兩個站點的請求所帶來的流量增長。
低延遲 可調一緻性
考慮到Spotify的使用者基數,實時計算使用者聽音樂的個性化資料會産生大量資料存儲到資料庫中。除了希望查詢能夠快速讀取這些資料外,存儲資料寫入路徑的低延遲對我們來說也是很重要的。
由于Cassandra中的寫入會存儲在append-only的結構中,是以寫操作通常非常快。實際上,在我們個性化推薦中使用的Cassandra,寫操作通常比讀操作快一個數量級。
由于實時計算的個性化資料本質上不是事務性的,并且丢失的資料很容易在幾分鐘内從使用者的聽音樂流中替換為新資料,我們可以調整寫和讀操作的一緻性級别,以犧牲一緻性,進而降低延遲(在操作成功之前不要等待所有副本響應)。
Bulkload資料寫入
在Spotify,我們對Hadoop和HDFS進行了大量投入,幾乎所有關于使用者的見解都來自于在曆史資料上運作作業。
Cassandra提供了從其他資料源(如HDFS)批量導入資料的方式,可以建構整個SSTable,然後将SSTable通過streaming傳輸到叢集中。比起發送數百萬條或更多條INSERT語句,這種方式要簡單得多,速度更快,效率更高。
針對從HDFS讀取資料并bulkload寫入SSTable,Spotify開源了一個名為hdfs2cass的工具。
雖然此功能的可用性并不影響我們使用Cassandra進行個性化推薦的決定,但它使我們将HDFS中的資料內建到Cassandra中變得非常簡單和易于維護。
Cassandra資料模型
自開始這個項目以來,我們在Cassandra中個性化資料的資料模型經曆了一些演變。
最初,我們認為我們應該有兩個表——一個用于使用者屬性(鍵值對),一個用于“實體”(如藝術家、曲目、播放清單等)的類似屬性集。前者隻包含帶有TTL的短期資料,而後者則是寫入不頻繁的相對靜态的資料。
将鍵值對存儲為單獨的CQL行而不是試圖為每個“屬性”建立一個CQL列(并且每個使用者有一個CQL行)的動機是允許生成此資料的服務和批處理作業獨立于使用資料的服務。使用這種方法,當資料的生産者需要增加一個新的“屬性”時,消費服務不需要做任何改動,因為這個服務隻是查詢給定使用者的所有鍵值對。
這些表的結構如下:
CREATE TABLE entitymetadata (
entityid text,
featurename text,
featurevalue text,
PRIMARY KEY (entityid, featurekey)
)
CREATE TABLE userprofilelatest (
userid text,
featurename text,
featurevalue text,
PRIMARY KEY (userid, featurename)
) 在最初的原型階段,這種結構工作得很好,但是我們很快遇到了一些問題,這就需要重新考慮關于“實體”的中繼資料的結構:
- entitymetadata列的結構意味着我們可以很容易地添加新類型的entitymetadata,但是如果我們嘗試了一種新類型的資料後發現它沒有用,不再需要時,這些featurename沒法删除。
- 一些實體中繼資料類型不能自然地表示為字元串,相反,使用CQL的某個集合類型更容易存儲。例如,在某些情況下,将值表示為list更為自然,因為這個值是有順序的事物清單;或者另一些情況下使用map來存儲實體值的排序。
我們放棄了使用一個表來存儲以(entityid,featurename)為鍵的所有值的做法,改為采用了為每個“featurename”建立一個表的方法,這些值使用适當的CQL類型。例如:
CREATE TABLE playlisttag (
entityid text,
featurevalue list<text>,
PRIMARY KEY (entityid)
) 用适當的CQL類型而不是全部用字元串表示,意味着我們不再需要對如何将非文本的資料表示為文本(上面提到的第2點)做出任何笨拙的決定,并且我們可以很容易地删除那些實驗之後決定不再用的表。從操作性的角度來看,這也允許我們檢查每個“特性”的讀寫操作的數量。
截至2014年底,我們有近12個此類資料的表,并且發現比起把所有資料塊塞進一個表,使用這些表要容易得多。
在Cassandra中有了DateTieredCompactionStrategy之後(我們自豪地說,這是Spotify同僚對Cassandra項目的貢獻),使用者資料表也經曆了類似的演變。
我們對userprofilelatency表(譯者注:原文如此,猜測可能是userprofilelatest的筆誤)的讀寫延遲不滿意,認為DTCS可能非常适合我們的用例,因為所有這些資料都是面向時間戳的,并且具有較短的ttl,是以我們嘗試将“userprofilelatest”表的STCS改為DTCS以改善延遲。
在開始進行更改之前,我們使用nodetool記錄了SSTablesPerRead的直方圖,來作為我們更改前的狀态,以便和修改後的效果做比較。當時記錄的一個直方圖如下:
SSTables per Read
1 sstables: 126733
2 sstables: 111414
3 sstables: 141385
4 sstables: 181974
5 sstables: 222921
6 sstables: 220581
7 sstables: 217314
8 sstables: 216296
10 sstables: 380294 注意,直方圖相對平坦,這意味着大量的讀取請求都需要通路多個sstable,而且往下看會發現這些數字實際上也在增加。

在檢查了直方圖之後,我們知道延遲很可能是由每次讀操作所通路的sstable絕對數量引起的,減少延遲的關鍵在于減少每次讀取必須檢查的sstable數量。
最初,啟用DTCS後的結果并不樂觀,但這并不是因為compaction政策本身的任何問題,而是因為我們把短期TTL資料和沒有TTL的使用者長期“靜态”資料混合在一個表裡面。
為了測試如果表中的所有行都有TTL,DTCS是否能夠更好地處理TTL行,我們把這個表分成了兩個表,一個表用于沒有TTL的“靜态”行,一個表用于帶有TTL的行。
在小心遷移使用這個資料的後端服務(首先将服務更改為同時從新舊表讀取資料,然後在資料遷移到新表完成後僅從新表讀取)後,我們的實驗是成功的:對隻有TTL行的表開啟DTCS後生成了SSTablesPerRead直方圖,其中隻需通路1個SSTable的讀操作與通路2個SSTable的讀操作的比例大約在6:1到12:1之間(取決于主機)。
下面是這次改動之後nodetool cfhistograms輸出的一個例子:
SSTables per Read
1 sstables: 4178514
2 sstables: 302549
3 sstables: 254760
4 sstables: 197695
5 sstables: 154961
... 或者如下圖:
在解決userprofileLatest表延遲問題的過程中,我們學到了一些關于Cassandra的寶貴經驗:
- DTCS非常适合時間序列,特别是當所有行都有TTL時(SizeTieredCompactionStrategy不适合這種類型的資料)
- 但是,如果把有TTL的行和沒有TTL的行混在一個表裡面,DTCS表現不是很好,是以不要以這種方式混合資料
- 對于帶有DTCS/TTL資料的表,我們将gc_grace_period設定為0,并有效地禁用讀修複,因為我們不需要它們:TTL比gc grace period要短。
- nodetool cfhistograms和每次讀取所通路的SSTables數量可能是了解表延遲背後原因的最佳資源,是以請確定經常測量它,并将其導入圖形系統以觀察随時間的變化。
通過對我們的資料模型和Cassandra配置進行一些調整,我們成功地建構了一個健壯的存儲層,用于向多個後端服務提供個性化資料。在對配置進行微調之後,在Cassandra叢集的後續運作中我們幾乎沒做過任何其他運維操作。我們在儀表闆中展示了一組叢集和資料集的名額,并配置了警報,當名額開始朝錯誤方向發展時會觸發。這有助于我們被動地跟蹤叢集的健康狀況。除了把叢集的大小增加一倍以适應新增的負載之外,我們還沒做過太多的叢集維護。而即使是叢集倍增這部分也相當簡單和無縫,值得再發一篇文章來解釋所有細節。
總的來說,我們非常滿意Cassandra作為滿足我們所有個性化推薦需求的解決方案,并相信Cassandra可以随着我們不斷增長的使用者基數持續擴充,提供個性化體驗。
感謝PlanetCassandra鼓勵我們在blog上分享Cassandra的經驗。
入群邀約
為了營造一個開放的 Cassandra 技術交流,我們建立了微信群公衆号和釘釘群,為廣大使用者提供專業的技術分享及問答,定期開展專家技術直播,歡迎大家加入。
阿裡雲為廣大開發者提供雲上Cassandra資源,可用于動手實踐:9.9元可使用三月(限首購)。
直達連結:
https://www.aliyun.com/product/cds 釘釘群入群連結:
https://c.tb.cn/F3.ZRTY0o微信群公衆号: