作者:閑魚技術-楚豐
背景
在網際網路産品中,使用者行為分析,通常是指通過統計、分析使用者在産品上的各種行為事件,挖掘、發現出有用的資訊,為産品的設計,營運政策提供有意義的依據。
通常,使用者行為分析包含以下流程:
- 資料埋點
- 資料采集
- 資料清洗
- 資料展現
在閑魚中,我們有海量使用者埋點資料,這些資料資訊量豐富,但是卻很少有效地利用起來:
- 使用率低:埋點資料量大并且非常雜亂,通常都隻是某個特定場景下,會統計某些特定埋點資料
- 資料太“原始”:通常埋點都是某個頁面曝光、某個點選事件等等,這些事件次元“低”,單用這些埋點不能表達某些“高緯”的事件,比如“點選搜尋框->輸入文字->進入搜尋結果頁->點選搜尋結果”為一次完整搜尋商品行為。
那麼針對這些原始埋點,我們是否能夠通過算法處理,抽象出更高緯的使用者行為資料,并且利用這些資料,挖掘出有用的資訊呢?
本文我們将分享閑魚在使用者行為分析中,利用“序列模式挖掘”所做的的一些嘗試和應用。
1.什麼是“使用者行為”
一般我們将使用者行為定義為:由一系列的行為事件所串聯成的序列。這個定義在不同的“粒度”上有不同的解釋,比如粗粒度上來看,“搜尋商品”->"聊天“->“下單”為一個使用者行為,其中“搜尋商品”是一個行為事件。
但是從細粒度上來看,“搜尋商品”包含了多個更小的事件,比如“點選搜尋框->輸入文本->點選搜尋按鈕->檢視搜尋結果”等,從細粒度上這幾個事件同樣可以定義為行為事件,此時“搜尋商品”就變成了一個使用者行為。
是以,分析使用者行為,要先看我們從哪個次元上進行分析。
在這篇文章,我們将行為事件定義為“頁面跳轉”和“按鈕點選”兩類事件,而使用者行為則是“多個行為事件”根據時間順序串聯起來的序列。
對應到到資料形式上,每一個“頁面跳轉”都對應一個埋點,每一個“按鈕點選”也都對應一個埋點,
是以,使用者行為分析,實際上也就變成了:埋點序列分析。
2.什麼是“序列模式挖掘”
序列模式挖掘,是資料挖掘裡關聯分析算法的一種,用直白的話來了解,就是:
從大量的序列資料中,挖掘出頻繁出現的“子序列”。
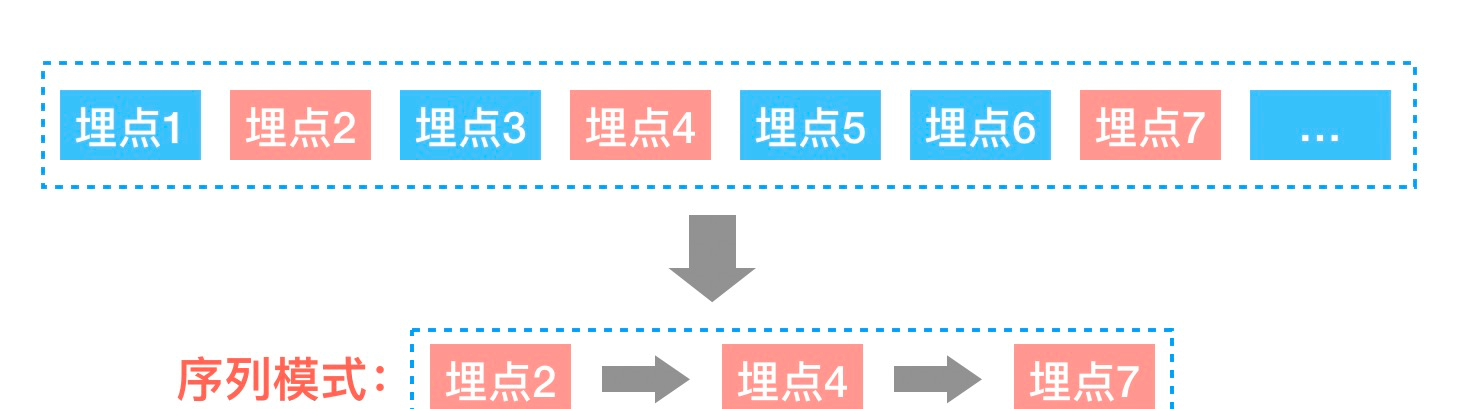
以我們埋點資料為例,使用者産生的埋點資料,根據時間排列可以得到一串埋點序列(上圖中埋點1到埋點7), 而序列模式挖掘的作用,就是可以從大量使用者的埋點序列中,找到其中隐藏着的模式:
埋點2->埋點4->埋點7(即大量使用者都出現了“埋點2->埋點4->埋點7”這種行為模式,中間可能有其它埋點)。
利用序列模式挖掘,我們可以從使用者埋點資料中,發現一些可能有價值的使用者行為模式。
3.如何應用
3.1 發現未知行為

利用序列模式挖掘,可以“歸納”和“總結”人群的行為共性,那麼如果我們先根據行為資料對人群進行無監督聚類,然後再對聚類出的人群進行行為序列模式挖掘,就可以“歸納”出該人群的“行為特點”。
行為聚類的流程大緻如下,有興趣的朋友可以查閱相關資料,這裡不再展開:
這裡無監督聚類可以根據人群内在的行為特性,得到不同人群。因為沒有事先進行行為定義,是以可以發現一些以前未知的人群,但是同時也産生了一個弊端,就是聚類結果可解釋性差,聚類出的人群為什麼被聚到一起不得而知。
而行為序列挖掘恰恰可以“解釋”一個人群的公共行為序列,是以結合聚類和序列模式挖掘,既可以發現不同的人群,又可以解釋這些人群被分類的“原因”。
案例:發現未知黑産人群
用上述方案,我們對閑魚的使用者埋點進行分析,發現聚類出的人群裡,有一個人群的行為序列是:
“商品搜尋結果頁->打開某個商品->點選聊天->發送檔案->傳回商品搜尋結果頁->打開某個商品->點選聊天->發送檔案”
抽樣檢視這群人發送的檔案發現,全部都是廣告視訊,也就是說,這些都是黑産賬号,不斷的在發送廣告視訊給别的使用者,而這些黑産行為,是我們原先“未知”的(不需要提前知道這種行為的存在)。
這種方式相比原來的“補漏”型黑産防控有以下優勢:
- 沒有經驗預設,可以快速從資料中發現新型的黑産行為模式,而不必等到大面積使用者回報以後做補漏。
- 算法抽象出來的行為模式相比人工“總結”會更加準确。(原來的防控大多數是根據使用者回報,然後人工觀察這些人的行為,并用規則去識别比對這些行為)
3.2 發現更多同類人群
假設我們已有一個特定人群樣本(比如一批黑産賬号),那麼如何通過這批小樣本,去找到更大的一批同類樣本呢?
我們可以通過序列模式挖掘,挖掘出這些人群行為的序列模式,然後再用這些序列模式比對所有人群,這樣就可以得到一個更大範圍的,滿足這個行為模式的人群。
案例:發現更多騷擾使用者的黑産賬号
在閑魚中,針對黑産的防控,有很多已有的成熟方案,這些方案會輸出很多黑産人群。
其中一個人群,是将廣告放在個人簡介裡,然後頭像換成帶有“看我簡介”文字的圖檔,最後不斷發送表情給别的使用者,吸引使用者去看簡介裡的廣告。
這個人群是根據原來的政策産出的,平均每天能夠發現大約 1800 個左右的黑産賬号。
我們利用上述方案,挖掘這個人群的公共行為:
“搜尋商品-點選商品-發起聊天-發送消息-點選個人首頁-關注使用者”
通過這個行為模式,我們再去比對了所有使用者,得到了更大的一個人群。這些人群經過驗證,都是黑産賬号。
經過交叉比對和人工驗證,用行為模式比對的方式:
- 比原來的政策多産生了 57% 的黑産賬号。
- 産出的黑産賬号準确率達到 99%
3.3 提供新的資料視角
通過挖掘所有使用者的公共行為序列,我們可以得到一個行為序清單,有了這個表,我們就可以通過統計每個使用者發生這些行為資料的次數,得到一份全新的資料,即“使用者行為次數表”。這樣,我們可以從不同行為的次數這個視角上,挖掘更多資訊。
(挖掘出的行為表,因為行為組合的多樣性,是以會有很多實際意義上重複的行為序列,可以用 PCA 主成分分析法來過濾掉重複的行為序列)
比如,可以比對不同使用者群,在這些行為次數上的差異(一個id為一個行為序列,如 4633):
當然,這種這樣的資料還需要進一步挖掘才能得到實際可利用的資訊,針對不同業務和問題,也有不同的利用方式,這裡我們也還隻是一個思路,我們也在繼續嘗試,希望能從這個新的資料視角挖掘到對業務有用的資訊。
4. 更多應用
當然,上述隻是分享了我們利用序列模式挖掘在使用者行為分析上的嘗試,除了 這些方法,還有更多可以應用的場景。
比如除了上述這些較大粒度的使用者行為分析,序列模式挖掘還可以用在更小粒度的場景上。比如分析單個頁面内,使用者行為是否有一些特定的模式(此時的行為可以定義為更細緻的操作,如點選、滑動,長按等),進而進一步幫助優化使用者體驗,發現異常等。
對于使用者行為分析和序列模式挖掘,本文的案例隻是冰山一角,希望這裡能夠起到抛磚引玉的作用。