作者:張俊
整理:張友亮(Apache Flink 社群志願者)
本文共 4745字,預計閱讀時間 15min。
本文根據 Apache Flink 系列直播整理而成,由 Apache Flink Contributor、OPPO 大資料平台研發負責人張俊老師分享。主要内容如下:
- 網絡流控的概念與背景
- TCP的流控機制
- Flink TCP-based 反壓機制(before V1.5)
- Flink Credit-based 反壓機制 (since V1.5)
- 總結與思考
為什麼需要網絡流控
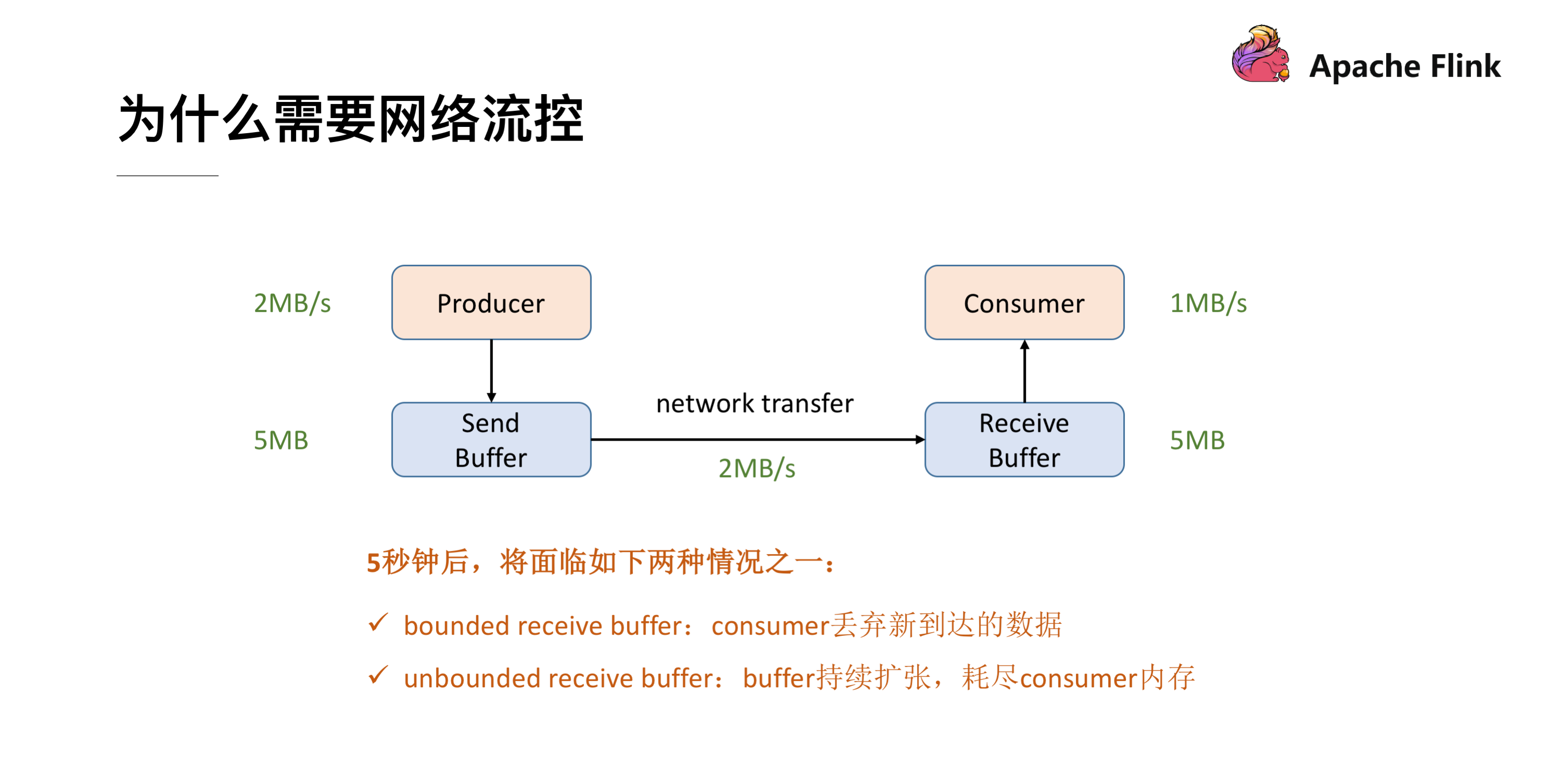
首先我們可以看下這張最精簡的網絡流控的圖,Producer 的吞吐率是 2MB/s,Consumer 是 1MB/s,這個時候我們就會發現在網絡通信的時候我們的 Producer 的速度是比 Consumer 要快的,有 1MB/s 的這樣的速度差,假定我們兩端都有一個 Buffer,Producer 端有一個發送用的 Send Buffer,Consumer 端有一個接收用的 Receive Buffer,在網絡端的吞吐率是 2MB/s,過了 5s 後我們的 Receive Buffer 可能就撐不住了,這時候會面臨兩種情況:
- 1.如果 Receive Buffer 是有界的,這時候新到達的資料就隻能被丢棄掉了。
- 2.如果 Receive Buffer 是無界的,Receive Buffer 會持續的擴張,最終會導緻 Consumer 的記憶體耗盡。
網絡流控的實作:靜态限速

為了解決這個問題,我們就需要網絡流控來解決上下遊速度差的問題,傳統的做法可以在 Producer 端實作一個類似 Rate Limiter 這樣的靜态限流,Producer 的發送速率是 2MB/s,但是經過限流這一層後,往 Send Buffer 去傳資料的時候就會降到 1MB/s 了,這樣的話 Producer 端的發送速率跟 Consumer 端的處理速率就可以比對起來了,就不會導緻上述問題。但是這個解決方案有兩點限制:
- 1、事先無法預估 Consumer 到底能承受多大的速率
- 2、 Consumer 的承受能力通常會動态地波動
網絡流控的實作:動态回報/自動反壓
針對靜态限速的問題我們就演進到了動态回報(自動反壓)的機制,我們需要 Consumer 能夠及時的給 Producer 做一個 feedback,即告知 Producer 能夠承受的速率是多少。動态回報分為兩種:
- 1、負回報:接受速率小于發送速率時發生,告知 Producer 降低發送速率
- 2、正回報:發送速率小于接收速率時發生,告知 Producer 可以把發送速率提上來
讓我們來看幾個經典案例
案例一:Storm 反壓實作
上圖就是 Storm 裡實作的反壓機制,可以看到 Storm 在每一個 Bolt 都會有一個監測反壓的線程(Backpressure Thread),這個線程一但檢測到 Bolt 裡的接收隊列(recv queue)出現了嚴重阻塞就會把這個情況寫到 ZooKeeper 裡,ZooKeeper 會一直被 Spout 監聽,監聽到有反壓的情況就會停止發送,通過這樣的方式比對上下遊的發送接收速率。
案例二:Spark Streaming 反壓實作
Spark Streaming 裡也有做類似這樣的 feedback 機制,上圖 Fecher 會實時的從 Buffer、Processing 這樣的節點收集一些名額然後通過 Controller 把速度接收的情況再回報到 Receiver,實作速率的比對。
疑問:為什麼 Flink(before V1.5)裡沒有用類似的方式實作 feedback 機制?
首先在解決這個疑問之前我們需要先了解一下 Flink 的網絡傳輸是一個什麼樣的架構。
這張圖就展現了 Flink 在做網絡傳輸的時候基本的資料的流向,發送端在發送網絡資料前要經曆自己内部的一個流程,會有一個自己的 Network Buffer,在底層用 Netty 去做通信,Netty 這一層又有屬于自己的 ChannelOutbound Buffer,因為最終是要通過 Socket 做網絡請求的發送,是以在 Socket 也有自己的 Send Buffer,同樣在接收端也有對應的三級 Buffer。學過計算機網絡的時候我們應該了解到,TCP 是自帶流量控制的。實際上 Flink (before V1.5)就是通過 TCP 的流控機制來實作 feedback 的。
TCP 流控機制
根據下圖我們來簡單的回顧一下 TCP 包的格式結構。首先,他有 Sequence number 這樣一個機制給每個資料包做一個編号,還有 ACK number 這樣一個機制來確定 TCP 的資料傳輸是可靠的,除此之外還有一個很重要的部分就是 Window Size,接收端在回複消息的時候會通過 Window Size 告訴發送端還可以發送多少資料。
接下來我們來簡單看一下這個過程。
TCP 流控:滑動視窗
TCP 的流控就是基于滑動視窗的機制,現在我們有一個 Socket 的發送端和一個 Socket 的接收端,目前我們的發送端的速率是我們接收端的 3 倍,這樣會發生什麼樣的一個情況呢?假定初始的時候我們發送的 window 大小是 3,然後我們接收端的 window 大小是固定的,就是接收端的 Buffer 大小為 5。
首先,發送端會一次性發 3 個 packets,将 1,2,3 發送給接收端,接收端接收到後會将這 3 個 packets 放到 Buffer 裡去。
接收端一次消費 1 個 packet,這時候 1 就已經被消費了,然後我們看到接收端的滑動視窗會往前滑動一格,這時候 2,3 還在 Buffer 當中 而 4,5,6 是空出來的,是以接收端會給發送端發送 ACK = 4 ,代表發送端可以從 4 開始發送,同時會将 window 設定為 3 (Buffer 的大小 5 減去已經存下的 2 和 3),發送端接收到回應後也會将他的滑動視窗向前移動到 4,5,6。
這時候發送端将 4,5,6 發送,接收端也能成功的接收到 Buffer 中去。
到這一階段後,接收端就消費到 2 了,同樣他的視窗也會向前滑動一個,這時候他的 Buffer 就隻剩一個了,于是向發送端發送 ACK = 7、window = 1。發送端收到之後滑動視窗也向前移,但是這個時候就不能移動 3 格了,雖然發送端的速度允許發 3 個 packets 但是 window 傳值已經告知隻能接收一個,是以他的滑動視窗就隻能往前移一格到 7 ,這樣就達到了限流的效果,發送端的發送速度從 3 降到 1。
我們再看一下這種情況,這時候發送端将 7 發送後,接收端接收到,但是由于接收端的消費出現問題,一直沒有從 Buffer 中去取,這時候接收端向發送端發送 ACK = 8、window = 0 ,由于這個時候 window = 0,發送端是不能發送任何資料,也就會使發送端的發送速度降為 0。這個時候發送端不發送任何資料了,接收端也不進行任何的回報了,那麼如何知道消費端又開始消費了呢?
TCP 當中有一個 ZeroWindowProbe 的機制,發送端會定期的發送 1 個位元組的探測消息,這時候接收端就會把 window 的大小進行回報。當接收端的消費恢複了之後,接收到探測消息就可以将 window 回報給發送端端了進而恢複整個流程。TCP 就是通過這樣一個滑動視窗的機制實作 feedback。
示例:WindowWordCount
大體的邏輯就是從 Socket 裡去接收資料,每 5s 去進行一次 WordCount,将這個代碼送出後就進入到了編譯階段。
編譯階段:生成 JobGraph
這時候還沒有向叢集去送出任務,在 Client 端會将 StreamGraph 生成 JobGraph,JobGraph 就是做為向叢集送出的最基本的單元。在生成 JobGrap 的時候會做一些優化,将一些沒有 Shuffle 機制的節點進行合并。有了 JobGraph 後就會向叢集進行送出,進入運作階段。
運作階段:排程 ExecutionGraph
JobGraph 送出到叢集後會生成 ExecutionGraph ,這時候就已經具備基本的執行任務的雛形了,把每個任務拆解成了不同的 SubTask,上圖 ExecutionGraph 中的 Intermediate Result Partition 就是用于發送資料的子產品,最終會将 ExecutionGraph 交給 JobManager 的排程器,将整個 ExecutionGraph 排程起來。然後我們概念化這樣一張實體執行圖,可以看到每個 Task 在接收資料時都會通過這樣一個 InputGate 可以認為是負責接收資料的,再往前有這樣一個 ResultPartition 負責發送資料,在 ResultPartition 又會去做分區跟下遊的 Task 保持一緻,就形成了 ResultSubPartition 和 InputChannel 的對應關系。這就是從邏輯層上來看的網絡傳輸的通道,基于這麼一個概念我們可以将反壓的問題進行拆解。
問題拆解:反壓傳播兩個階段
反壓的傳播實際上是分為兩個階段的,對應着上面的執行圖,我們一共涉及 3 個 TaskManager,在每個 TaskManager 裡面都有相應的 Task 在執行,還有負責接收資料的 InputGate,發送資料的 ResultPartition,這就是一個最基本的資料傳輸的通道。在這時候假設最下遊的 Task (Sink)出現了問題,處理速度降了下來這時候是如何将這個壓力反向傳播回去呢?這時候就分為兩種情況:
- 跨 TaskManager ,反壓如何從 InputGate 傳播到 ResultPartition
- TaskManager 内,反壓如何從 ResultPartition 傳播到 InputGate
跨 TaskManager 資料傳輸
前面提到,發送資料需要 ResultPartition,在每個 ResultPartition 裡面會有分區 ResultSubPartition,中間還會有一些關于記憶體管理的 Buffer。
對于一個 TaskManager 來說會有一個統一的 Network BufferPool 被所有的 Task 共享,在初始化時會從 Off-heap Memory 中申請記憶體,申請到記憶體的後續記憶體管理就是同步 Network BufferPool 來進行的,不需要依賴 JVM GC 的機制去釋放。有了 Network BufferPool 之後可以為每一個 ResultSubPartition 建立 Local BufferPool 。
如上圖左邊的 TaskManager 的 Record Writer 寫了 <1,2> 這個兩個資料進來,因為 ResultSubPartition 初始化的時候為空,沒有 Buffer 用來接收,就會向 Local BufferPool 申請記憶體,這時 Local BufferPool 也沒有足夠的記憶體于是将請求轉到 Network BufferPool,最終将申請到的 Buffer 按原鍊路返還給 ResultSubPartition,<1,2> 這個兩個資料就可以被寫入了。之後會将 ResultSubPartition 的 Buffer 拷貝到 Netty 的 Buffer 當中最終拷貝到 Socket 的 Buffer 将消息發送出去。然後接收端按照類似的機制去處理将消息消費掉。
接下來我們來模拟上下遊處理速度不比對的場景,發送端的速率為 2,接收端的速率為 1,看一下反壓的過程是怎樣的。
跨 TaskManager 反壓過程
因為速度不比對就會導緻一段時間後 InputChannel 的 Buffer 被用盡,于是他會向 Local BufferPool 申請新的 Buffer ,這時候可以看到 Local BufferPool 中的一個 Buffer 就會被标記為 Used。
發送端還在持續以不比對的速度發送資料,然後就會導緻 InputChannel 向 Local BufferPool 申請 Buffer 的時候發現沒有可用的 Buffer 了,這時候就隻能向 Network BufferPool 去申請,當然每個 Local BufferPool 都有最大的可用的 Buffer,防止一個 Local BufferPool 把 Network BufferPool 耗盡。這時候看到 Network BufferPool 還是有可用的 Buffer 可以向其申請。
一段時間後,發現 Network BufferPool 沒有可用的 Buffer,或是 Local BufferPool 的最大可用 Buffer 到了上限無法向 Network BufferPool 申請,沒有辦法去讀取新的資料,這時 Netty AutoRead 就會被禁掉,Netty 就不會從 Socket 的 Buffer 中讀取資料了。
顯然,再過不久 Socket 的 Buffer 也被用盡,這時就會将 Window = 0 發送給發送端(前文提到的 TCP 滑動視窗的機制)。這時發送端的 Socket 就會停止發送。
很快發送端的 Socket 的 Buffer 也被用盡,Netty 檢測到 Socket 無法寫了之後就會停止向 Socket 寫資料。
Netty 停止寫了之後,所有的資料就會阻塞在 Netty 的 Buffer 當中了,但是 Netty 的 Buffer 是無界的,可以通過 Netty 的水位機制中的 high watermark 控制他的上界。當超過了 high watermark,Netty 就會将其 channel 置為不可寫,ResultSubPartition 在寫之前都會檢測 Netty 是否可寫,發現不可寫就會停止向 Netty 寫資料。
這時候所有的壓力都來到了 ResultSubPartition,和接收端一樣他會不斷的向 Local BufferPool 和 Network BufferPool 申請記憶體。
Local BufferPool 和 Network BufferPool 都用盡後整個 Operator 就會停止寫資料,達到跨 TaskManager 的反壓。
TaskManager 内反壓過程
了解了跨 TaskManager 反壓過程後再來看 TaskManager 内反壓過程就更好了解了,下遊的 TaskManager 反壓導緻本 TaskManager 的 ResultSubPartition 無法繼續寫入資料,于是 Record Writer 的寫也被阻塞住了,因為 Operator 需要有輸入才能有計算後的輸出,輸入跟輸出都是在同一線程執行, Record Writer 阻塞了,Record Reader 也停止從 InputChannel 讀資料,這時上遊的 TaskManager 還在不斷地發送資料,最終将這個 TaskManager 的 Buffer 耗盡。具體流程可以參考下圖,這就是 TaskManager 内的反壓過程。
Flink Credit-based 反壓機制(since V1.5)
TCP-based 反壓的弊端
在介紹 Credit-based 反壓機制之前,先分析下 TCP 反壓有哪些弊端。
- 在一個 TaskManager 中可能要執行多個 Task,如果多個 Task 的資料最終都要傳輸到下遊的同一個 TaskManager 就會複用同一個 Socket 進行傳輸,這個時候如果單個 Task 産生反壓,就會導緻複用的 Socket 阻塞,其餘的 Task 也無法使用傳輸,checkpoint barrier 也無法發出導緻下遊執行 checkpoint 的延遲增大。
- 依賴最底層的 TCP 去做流控,會導緻反壓傳播路徑太長,導緻生效的延遲比較大。
引入 Credit-based 反壓
這個機制簡單的了解起來就是在 Flink 層面實作類似 TCP 流控的反壓機制來解決上述的弊端,Credit 可以類比為 TCP 的 Window 機制。
Credit-based 反壓過程
如圖所示在 Flink 層面實作反壓機制,就是每一次 ResultSubPartition 向 InputChannel 發送消息的時候都會發送一個 backlog size 告訴下遊準備發送多少消息,下遊就會去計算有多少的 Buffer 去接收消息,算完之後如果有充足的 Buffer 就會返還給上遊一個 Credit 告知他可以發送消息(圖上兩個 ResultSubPartition 和 InputChannel 之間是虛線是因為最終還是要通過 Netty 和 Socket 去通信),下面我們看一個具體示例。
假設我們上下遊的速度不比對,上遊發送速率為 2,下遊接收速率為 1,可以看到圖上在 ResultSubPartition 中累積了兩條消息,10 和 11, backlog 就為 2,這時就會将發送的資料 <8,9> 和 backlog = 2 一同發送給下遊。下遊收到了之後就會去計算是否有 2 個 Buffer 去接收,可以看到 InputChannel 中已經不足了這時就會從 Local BufferPool 和 Network BufferPool 申請,好在這個時候 Buffer 還是可以申請到的。
過了一段時間後由于上遊的發送速率要大于下遊的接受速率,下遊的 TaskManager 的 Buffer 已經到達了申請上限,這時候下遊就會向上遊傳回 Credit = 0,ResultSubPartition 接收到之後就不會向 Netty 去傳輸資料,上遊 TaskManager 的 Buffer 也很快耗盡,達到反壓的效果,這樣在 ResultSubPartition 層就能感覺到反壓,不用通過 Socket 和 Netty 一層層地向上回報,降低了反壓生效的延遲。同時也不會将 Socket 去阻塞,解決了由于一個 Task 反壓導緻 TaskManager 和 TaskManager 之間的 Socket 阻塞的問題。
總結
- 網絡流控是為了在上下遊速度不比對的情況下,防止下遊出現過載
- 網絡流控有靜态限速和動态反壓兩種手段
- Flink 1.5 之前是基于 TCP 流控 + bounded buffer 實作反壓
- Flink 1.5 之後實作了自己托管的 credit - based 流控機制,在應用層模拟 TCP 的流控機制
思考
有了動态反壓,靜态限速是不是完全沒有作用了?
實際上動态反壓不是萬能的,我們流計算的結果最終是要輸出到一個外部的存儲(Storage),外部資料存儲到 Sink 端的反壓是不一定會觸發的,這要取決于外部存儲的實作,像 Kafka 這樣是實作了限流限速的消息中間件可以通過協定将反壓回報給 Sink 端,但是像 ES 無法将反壓進行傳播回報給 Sink 端,這種情況下為了防止外部存儲在大的資料量下被打爆,我們就可以通過靜态限速的方式在 Source 端去做限流。是以說動态反壓并不能完全替代靜态限速的,需要根據合适的場景去選擇處理方案。
▼ Apache Flink 社群推薦 ▼
Apache Flink 及大資料領域頂級盛會 Flink Forward Asia 2019 大會議程重磅釋出,參與
問卷調研就有機會免費擷取門票!
https://developer.aliyun.com/special/ffa2019