作者:嶽猛
整理:毛鶴
本文根據 Apache Flink 系列直播課程整理而成,由 Apache Flink Contributor、網易雲音樂實時計算平台研發工程師嶽猛分享。主要分享内容為 Flink Job 執行作業的流程,文章将從兩個方面進行分享:一是如何從 Program 到實體執行計劃,二是生成實體執行計劃後該如何排程和執行。
Flink 四層轉化流程
Flink 有四層轉換流程,第一層為 Program 到 StreamGraph;第二層為 StreamGraph 到 JobGraph;第三層為 JobGraph 到 ExecutionGraph;第四層為 ExecutionGraph 到實體執行計劃。通過對 Program 的執行,能夠生成一個 DAG 執行圖,即邏輯執行圖。如下:
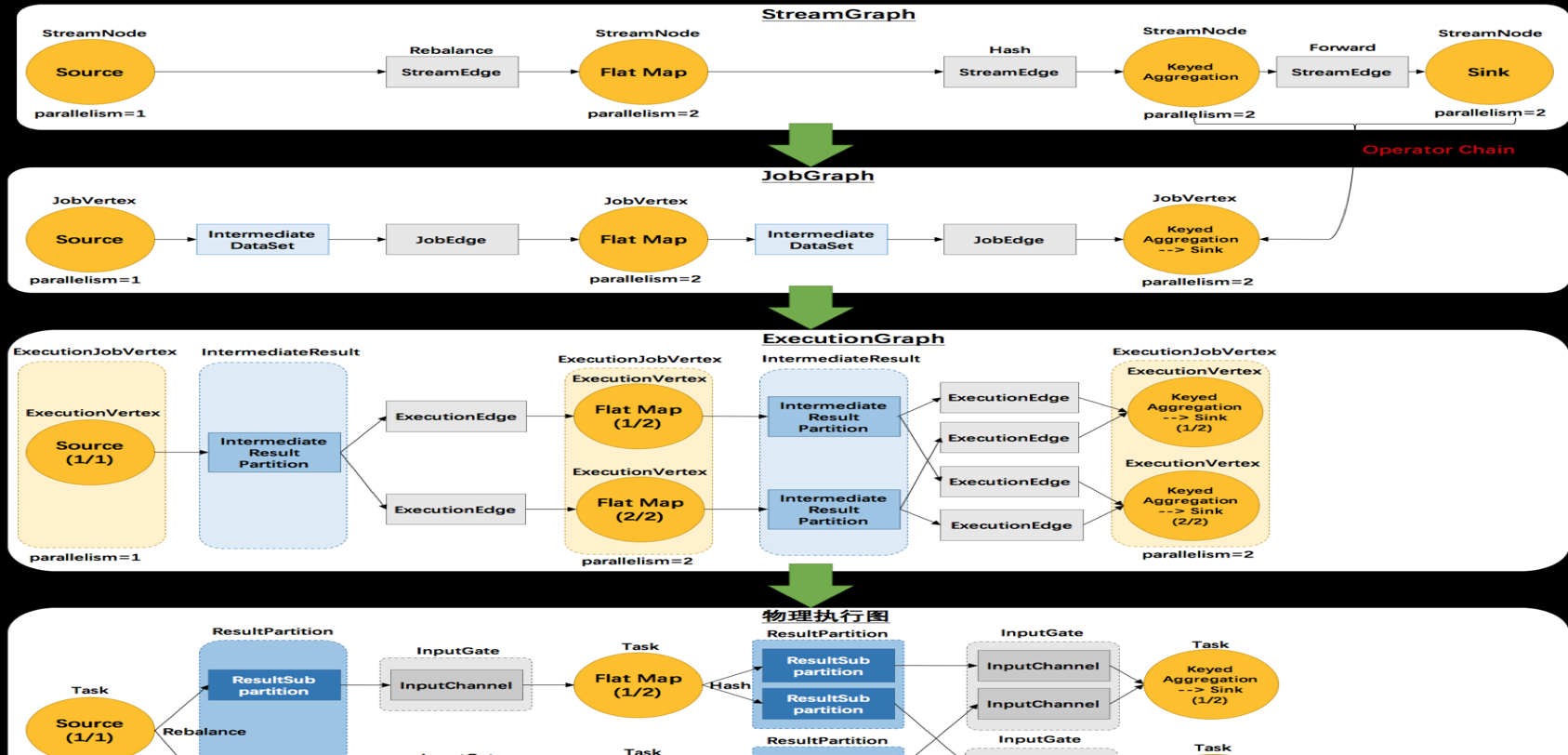
第一部分将先講解四層轉化的流程,然後将以詳細案例講解四層的具體轉化。
- 第一層 StreamGraph 從 Source 節點開始,每一次 transform 生成一個 StreamNode,兩個 StreamNode 通過 StreamEdge 連接配接在一起,形成 StreamNode 和 StreamEdge 構成的DAG。
- 第二層 JobGraph,依舊從 Source 節點開始,然後去周遊尋找能夠嵌到一起的 operator,如果能夠嵌到一起則嵌到一起,不能嵌到一起的單獨生成 jobVertex,通過 JobEdge 連結上下遊 JobVertex,最終形成 JobVertex 層面的 DAG。
- JobVertex DAG 送出到任務以後,從 Source 節點開始排序,根據 JobVertex 生成ExecutionJobVertex,根據 jobVertex的IntermediateDataSet 建構IntermediateResult,然後 IntermediateResult 建構上下遊的依賴關系,形成 ExecutionJobVertex 層面的 DAG 即 ExecutionGraph。
- 最後通過 ExecutionGraph 層到實體執行層。
Program 到 StreamGraph 的轉化
Program 轉換成 StreamGraph 具體分為三步:
- 從 StreamExecutionEnvironment.execute 開始執行程式,将 transform 添加到 StreamExecutionEnvironment 的 transformations。
- 調用 StreamGraphGenerator 的 generateInternal 方法,周遊 transformations 建構 StreamNode 及 StreamEage。
- 通過 StreamEdge 連接配接 StreamNode。

通過 WindowWordCount 來看代碼到 StreamGraph 的轉化,在 flatMap transform 設定 slot 共享組為 flatMap_sg,并發設定為 4,在聚合的操作中設定 slot 共享組為 sum_sg, sum() 和 counts() 并發設定為 3,這樣設定主要是為了示範後面如何嵌到一起的,跟上下遊節點的并發以及上遊的共享組有關。
WindowWordCount 代碼中可以看到,在 readTextFile() 中會生成一個 transform,且 transform 的 ID 是 1;然後到 flatMap() 會生成一個 transform, transform 的 ID 是 2;接着到 keyBy() 生成一個 transform 的 ID 是 3;再到 sum() 生成一個 transform 的 ID 是 4;最後到 counts()生成 transform 的 ID 是 5。
transform 的結構如圖所示,第一個是 flatMap 的 transform,第二個是 window 的 transform,第三個是 SinkTransform 的 transform。除此之外,還能在 transform 的結構中看到每個 transform 的 input 是什麼。
接下來介紹一下 StreamNode 和 StreamEdge。
- StreamNode 是用來描述 operator 的邏輯節點,其關鍵成員變量有 slotSharingGroup、jobVertexClass、inEdges、outEdges以及transformationUID;
- StreamEdge 是用來描述兩個 operator 邏輯的連結邊,其關鍵變量有 sourceVertex、targetVertex。
WindowWordCount transform 到 StreamGraph 轉化如圖所示,StreamExecutionEnvironment 的 transformations 存在 3 個 transform,分别是 Flat Map(Id 2)、Window(Id 4)、Sink(Id 5)。
transform 的時候首先遞歸處理 transform 的 input,生成 StreamNode,然後通過 StreamEdge 連結上下遊 StreamNode。需要注意的是,有些 transform 操作并不會生成StreamNode 如 PartitionTransformtion,而是生成個虛拟節點。
在轉換完成後可以看到,streamNodes 有四種 transform 形式,分别為 Source、Flat Map、Window、Sink。
每個 streamNode 對象都攜帶并發個數、slotSharingGroup、執行類等運作資訊。
StreamGraph 到 JobGraph 的轉化
StreamGraph 到 JobGraph 的轉化步驟:
- 設定排程模式,Eager 所有節點立即啟動。
- 廣度優先周遊 StreamGraph,為每個 streamNode 生成 byte 數組類型的 hash 值。
- 從 source 節點開始遞歸尋找嵌到一起的 operator,不能嵌到一起的節點單獨生成 jobVertex,能夠嵌到一起的開始節點生成 jobVertex,其他節點以序列化的形式寫入到 StreamConfig,然後 merge 到 CHAINED_TASK_CONFIG,再通過 JobEdge 連結上下遊 JobVertex。
- 将每個 JobVertex 的入邊(StreamEdge)序列化到該 StreamConfig。
- 根據 group name 為每個 JobVertext 指定 SlotSharingGroup。
- 配置 checkpoint。
- 将緩存檔案存檔案的配置添加到 configuration 中。
- 設定 ExecutionConfig。
從 source 節點遞歸尋找嵌到一起的 operator 中,嵌到一起需要滿足一定的條件,具體條件介紹如下:
- 下遊節點隻有一個輸入。
- 下遊節點的操作符不為 null。
- 上遊節點的操作符不為 null。
- 上下遊節點在一個槽位共享組内。
- 下遊節點的連接配接政策是 ALWAYS。
- 上遊節點的連接配接政策是 HEAD 或者 ALWAYS。
- edge 的分區函數是 ForwardPartitioner 的執行個體。
- 上下遊節點的并行度相等。
- 可以進行節點連接配接操作。
JobGraph 對象結構如上圖所示,taskVertices 中隻存在 Window、Flat Map、Source 三個 TaskVertex,Sink operator 被嵌到 window operator 中去了。
為什麼要為每個 operator 生成 hash 值?
Flink 任務失敗的時候,各個 operator 是能夠從 checkpoint 中恢複到失敗之前的狀态的,恢複的時候是依據 JobVertexID(hash 值)進行狀态恢複的。相同的任務在恢複的時候要求 operator 的 hash 值不變,是以能夠擷取對應的狀态。
每個 operator 是怎樣生成 hash 值的?
如果使用者對節點指定了一個散列值,則基于使用者指定的值能夠産生一個長度為 16 的位元組數組。如果使用者沒有指定,則根據目前節點所處的位置,産生一個散列值。
考慮的因素主要有三點:
- 一是在目前 StreamNode 之前已經處理過的節點的個數,作為目前 StreamNode 的 id,添加到 hasher 中;
- 二是周遊目前 StreamNode 輸出的每個 StreamEdge,并判斷目前 StreamNode 與這個 StreamEdge 的目标 StreamNode 是否可以進行連結,如果可以,則将目标 StreamNode 的 id 也放入 hasher 中,且這個目标 StreamNode 的 id 與目前 StreamNode 的 id 取相同的值;
- 三是将上述步驟後産生的位元組資料,與目前 StreamNode 的所有輸入 StreamNode 對應的位元組資料,進行相應的位操作,最終得到的位元組資料,就是目前 StreamNode 對應的長度為 16 的位元組數組。
JobGraph 到 ExexcutionGraph 以及實體執行計劃
JobGraph 到 ExexcutionGraph 以及實體執行計劃的流程:
- 将 JobGraph 裡面的 jobVertex 從 Source 節點開始排序。
- 在 executionGraph.attachJobGraph(sortedTopology)方法裡面,根據 JobVertex 生成 ExecutionJobVertex,在 ExecutionJobVertex 構造方法裡面,根據 jobVertex 的 IntermediateDataSet 建構 IntermediateResult,根據 jobVertex 并發建構 ExecutionVertex,ExecutionVertex 建構的時候,建構 IntermediateResultPartition(每一個 Execution 建構 IntermediateResult 數個IntermediateResultPartition );将建立的 ExecutionJobVertex 與前置的 IntermediateResult 連接配接起來。
- 建構 ExecutionEdge ,連接配接到前面的 IntermediateResultPartition,最終從 ExecutionGraph 到實體執行計劃。
Flink Job 執行流程
Flink On Yarn 模式
基于 Yarn 層面的架構類似 Spark on Yarn 模式,都是由 Client 送出 App 到 RM 上面去運作,然後 RM 配置設定第一個 container 去運作 AM,然後由 AM 去負責資源的監督和管理。需要說明的是,Flink 的 Yarn 模式更加類似 Spark on Yarn 的 cluster 模式,在 cluster 模式中,dirver 将作為 AM 中的一個線程去運作。Flink on Yarn 模式也是會将 JobManager 啟動在 container 裡面,去做個 driver 類似的任務排程和配置設定,Yarn AM 與 Flink JobManager 在同一個 Container 中,這樣 AM 可以知道 Flink JobManager 的位址,進而 AM 可以申請 Container 去啟動 Flink TaskManager。待 Flink 成功運作在 Yarn 叢集上,Flink Yarn Client 就可以送出 Flink Job 到 Flink JobManager,并進行後續的映射、排程和計算處理。
Fink on Yarn 的缺陷
- 資源配置設定是靜态的,一個作業需要在啟動時擷取所需的資源并且在它的生命周期裡一直持有這些資源。這導緻了作業不能随負載變化而動态調整,在負載下降時無法歸還空閑的資源,在負載上升時也無法動态擴充。
- On-Yarn 模式下,所有的 container 都是固定大小的,導緻無法根據作業需求來調整 container 的結構。譬如 CPU 密集的作業或許需要更多的核,但不需要太多記憶體,固定結構的 container 會導緻記憶體被浪費。
- 與容器管理基礎設施的互動比較笨拙,需要兩個步驟來啟動 Flink 作業: 1.啟動 Flink 守護程序;2.送出作業。如果作業被容器化并且将作業部署作為容器部署的一部分,那麼将不再需要步驟2。
- On-Yarn 模式下,作業管理頁面會在作業完成後消失不可通路。
- Flink 推薦
per job clusters
在 Flink 版本 1.5 中引入了 Dispatcher,Dispatcher 是在新設計裡引入的一個新概念。Dispatcher 會從 Client 端接受作業送出請求并代表它在叢集管理器上啟動作業。
引入 Dispatcher 的原因主要有兩點:
- 第一,一些叢集管理器需要一個中心化的作業生成和監控執行個體;
- 第二,能夠實作 Standalone 模式下 JobManager 的角色,且等待作業送出。在一些案例中,Dispatcher 是可選的(Yarn)或者不相容的(kubernetes)。
資源排程模型重構下的 Flink On Yarn 模式
沒有 Dispatcher job 運作過程
用戶端送出 JobGraph 以及依賴 jar 包到 YarnResourceManager,接着 Yarn ResourceManager 配置設定第一個 container 以此來啟動 AppMaster,Application Master 中會啟動一個 FlinkResourceManager 以及 JobManager,JobManager 會根據 JobGraph 生成的 ExecutionGraph 以及實體執行計劃向 FlinkResourceManager 申請 slot,FlinkResoourceManager 會管理這些 slot 以及請求,如果沒有可用 slot 就向 Yarn 的 ResourceManager 申請 container,container 啟動以後會注冊到 FlinkResourceManager,最後 JobManager 會将 subTask deploy 到對應 container 的 slot 中去。
在有 Dispatcher 的模式下
會增加一個過程,就是 Client 會直接通過 HTTP Server 的方式,然後用 Dispatcher 将這個任務送出到 Yarn ResourceManager 中。
新架構具有四大優勢,詳情如下:
- client 直接在 Yarn 上啟動作業,而不需要先啟動一個叢集然後再送出作業到叢集。是以 client 再送出作業後可以馬上傳回。
- 所有的使用者依賴庫和配置檔案都被直接放在應用的 classpath,而不是用動态的使用者代碼 classloader 去加載。
- container 在需要時才請求,不再使用時會被釋放。
- “需要時申請”的 container 配置設定方式允許不同算子使用不同 profile (CPU 和記憶體結構)的 container。
新的資源排程架構下 single cluster job on Yarn 流程介紹
single cluster job on Yarn 模式涉及三個執行個體對象:
- clifrontend
- Invoke App code;
- 生成 StreamGraph,然後轉化為 JobGraph;
- YarnJobClusterEntrypoint(Master)
- 依次啟動 YarnResourceManager、MinDispatcher、JobManagerRunner 三者都服從分布式協同一緻的政策;
- JobManagerRunner 将 JobGraph 轉化為 ExecutionGraph ,然後轉化為實體執行任務Execution,然後進行 deploy,deploy 過程會向 YarnResourceManager 請求 slot,如果有直接 deploy 到對應的 YarnTaskExecutiontor 的 slot 裡面,沒有則向 Yarn 的 ResourceManager 申請,帶 container 啟動以後 deploy。
- YarnTaskExecutorRunner (slave)
- 負責接收 subTask,并運作。
整個任務運作代碼調用流程如下圖:
subTask 在執行時是怎麼運作的?
調用 StreamTask 的 invoke 方法,執行步驟如下:
* initializeState()即operator的initializeState()
* openAllOperators() 即operator的open()方法
* 最後調用 run 方法來進行真正的任務處理 我們來看下 flatMap 對應的 OneInputStreamTask 的 run 方法具體是怎麼處理的。
@Override
protected void run() throws Exception {
// cache processor reference on the stack, to make the code more JIT friendly
final StreamInputProcessor<IN> inputProcessor = this.inputProcessor;
while (running && inputProcessor.processInput()) {
// all the work happens in the "processInput" method
}
} 最終是調用 StreamInputProcessor 的 processInput() 做資料的處理,這裡面包含使用者的處理邏輯。
public boolean processInput() throws Exception {
if (isFinished) {
return false;
}
if (numRecordsIn == null) {
try {
numRecordsIn = ((OperatorMetricGroup) streamOperator.getMetricGroup()).getIOMetricGroup().getNumRecordsInCounter();
} catch (Exception e) {
LOG.warn("An exception occurred during the metrics setup.", e);
numRecordsIn = new SimpleCounter();
}
}
while (true) {
if (currentRecordDeserializer != null) {
DeserializationResult result = currentRecordDeserializer.getNextRecord(deserializationDelegate);
if (result.isBufferConsumed()) {
currentRecordDeserializer.getCurrentBuffer().recycleBuffer();
currentRecordDeserializer = null;
}
if (result.isFullRecord()) {
StreamElement recordOrMark = deserializationDelegate.getInstance();
//處理watermark
if (recordOrMark.isWatermark()) {
// handle watermark
//watermark處理邏輯,這裡可能引起timer的trigger
statusWatermarkValve.inputWatermark(recordOrMark.asWatermark(), currentChannel);
continue;
} else if (recordOrMark.isStreamStatus()) {
// handle stream status
statusWatermarkValve.inputStreamStatus(recordOrMark.asStreamStatus(), currentChannel);
continue;
//處理latency watermark
} else if (recordOrMark.isLatencyMarker()) {
// handle latency marker
synchronized (lock) {
streamOperator.processLatencyMarker(recordOrMark.asLatencyMarker());
}
continue;
} else {
//使用者的真正的代碼邏輯
// now we can do the actual processing
StreamRecord<IN> record = recordOrMark.asRecord();
synchronized (lock) {
numRecordsIn.inc();
streamOperator.setKeyContextElement1(record);
//處理資料
streamOperator.processElement(record);
}
return true;
}
}
}
//這裡會進行checkpoint barrier的判斷和對齊,以及不同partition 裡面checkpoint barrier不一緻時候的,資料buffer,
final BufferOrEvent bufferOrEvent = barrierHandler.getNextNonBlocked();
if (bufferOrEvent != null) {
if (bufferOrEvent.isBuffer()) {
currentChannel = bufferOrEvent.getChannelIndex();
currentRecordDeserializer = recordDeserializers[currentChannel];
currentRecordDeserializer.setNextBuffer(bufferOrEvent.getBuffer());
}
else {
// Event received
final AbstractEvent event = bufferOrEvent.getEvent();
if (event.getClass() != EndOfPartitionEvent.class) {
throw new IOException("Unexpected event: " + event);
}
}
}
else {
isFinished = true;
if (!barrierHandler.isEmpty()) {
throw new IllegalStateException("Trailing data in checkpoint barrier handler.");
}
return false;
}
}
}
streamOperator.processElement(record) 最終會調用使用者的代碼處理邏輯,假如 operator 是 StreamFlatMap 的話,
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
collector.setTimestamp(element);
userFunction.flatMap(element.getValue(), collector);//使用者代碼
}
如有不正确的地方,歡迎指正,關于 Flink 資源排程架構調整,網上有一篇非常不錯的針對 FLIP-6 的翻譯,推薦給大家。
資源排程模型重構▼ Apache Flink 社群推薦 ▼
Apache Flink 及大資料領域頂級盛會 Flink Forward Asia 2019 大會議程重磅釋出,參與
問卷調研就有機會免費擷取門票!
https://developer.aliyun.com/special/ffa2019