本篇文章整理自今日頭條的沈輝在 RocketMQ 開發者沙龍中的演講,主要和大家分享一下,RocketMQ 在微服務架構下的實踐和容災體系建設。沈輝是今日頭條的架構師,主要負責 RocketMQ 在頭條的落地以及架構設計,參與消息系統的時間大概一年左右。
以下是本次分享的議題:
- 頭條的業務背景
- 為什麼選擇 RocketMQ
- RocketMQ 在頭條的落地實踐
- 頭條的容災系統建設
業務背景
今日頭條的服務大量使用微服務,容器數目巨大,業務線繁多, Topic 的數量也非常多。另外,使用的語言比較繁雜,包括 Python,Go, C++, Java, JS 等,對于基礎元件的接入,維護 SDK 的成本很高。
引入 RocketMQ 之前采用的消息隊列是 NSQ 和 kafka , NSQ 是純記憶體的消息隊列,缺少消息的持久性,不落盤直接寫到 Golang 的 channel 裡,在并發量高的時候 CPU 使用率非常高,其優點是可以無限水準擴充,另外,由于不需要保證消息的有序性,叢集單點故障對可用性基本沒有影響,是以具有非常高的可用性。我們也用到了 Kafka ,它的主要問題是在業務線和 Topic 繁多,其寫入性能會出現明顯的下降,拆分叢集又會增加額外的運維負擔。并且在高負載下,其故障恢複時間比較長。是以,針對當時的狀況和業務場景的需求,我們進行了一些調研,期望選擇一款新的 MQ 來比較好的解決目前的困境,最終選擇了 RocketMQ 。
這是一個經過阿裡巴巴多年雙11驗證過的、可以支援億級并發的開源消息隊列,是值得信任的。其次關注一下他的特性。 RocketMQ 具有高可靠性、資料持久性,和 Kafka 一樣是先寫 PageCache ,再落盤,并且資料有多副本;并且它的存儲模型是所有的 Topic 都寫到同一個 Commitlog 裡,是一個append only 操作,在海量 Topic 下也能将磁盤的性能發揮到極緻,并且保持穩定的寫入時延。然後就是他的性能,經過我們的 benchmark ,采用一主兩從的結構,單機 qps 可以達到 14w , latency 保持在 2ms 以内。對比之前的 NSQ 和 Kafka , Kafka 的吞吐非常高,但是在多 Topic 下, Kafka 的 PCT99 毛刺會非常多,而且平均值非常長,不适合線上業務場景。另外 NSQ 的消息首先經過 Golang 的 channel ,這是非常消耗 CPU 的,在單機 5~6w 的時候 CPU 使用率達到 50~60% ,高負載下的寫延遲不穩定。另外 RocketMQ 對線上業務特性支援是非常豐富的,支援 retry , 支援并發消費,死信隊列,延時消息,基于時間戳的消息回溯,另外消息體支援消息頭,這個是非常有用的,可以直接支援實作消息鍊路追蹤,不然就需要把追蹤資訊寫到 message 的 body 裡;還支援事務的消息。綜合以上特性最終選擇了 RocketMQ 。
下面簡單介紹下,今日頭條的部署結構,如圖所示:
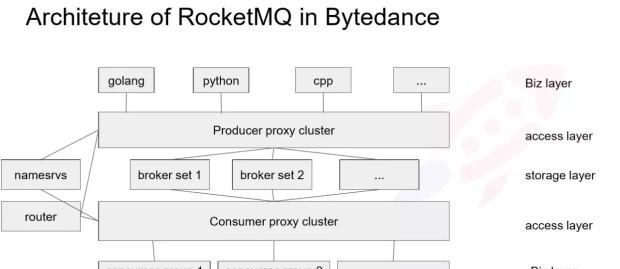
由于生産者種類繁多,我們傾向于保持用戶端簡單,因為推動 SDK 更新是一個很沉重的負擔,是以我們通過提供一個 Proxy 層,來保持生産端的輕量。 Proxy 層是由一個标準的 gRpc 架構實作,也可以用 thrift ,當然任何 RPC 都架構都可以實作。
Producer 的 Proxy 相對比較簡單,雖然在 Producer 這邊也內建了很多比如路由管理、監控等其他功能, SDK 隻需實作發消息的請求,是以 SDK 的非常輕量、改動非常少,在疊代過程中也不需要一個個推業務去更新 SDK 。 SDK 通過服務發現去找到一個 Proxy 執行個體,然後建立連接配接發送消息, Proxy 的工作是根據 RPC 請求的消息轉發到對應的 Broker 叢集上。 Consumer Proxy 實作的是 pull 和二次 reblance 的邏輯,這個後面會講到,相當于把 Consumer 的 pull 透傳給 Brokerset , Proxy 這邊會有一個消息的 cache ,一定程度上降低對 broker page cache 的污染。這個架構和滴滴的 MQ 架構有點相似,他們也是之前做了一個 Proxy ,用 thrift 做 RPC ,這對後端的擴容、運維、減少 SDK 的邏輯上來說都是很有必要的。
在容器以及微服務場景下為什麼要做這個 Porxy ?

有以下幾點原因:
1、 SDK 會非常簡單輕量。
2、很容易對流量進行控制; Proxy 可以對生産端的流量進行控制,比如我們期望某些Broker壓力比較大的時候,能夠切一些流量或者說切流量到另外的機房,這種流量的排程,多環境的支援,再比如有些預釋出環境、預上線環境的支援,我們 Topic 這邊寫入的流量可以在 Proxy 這邊可以很友善的完成控制,不用修改 SDK 。
3,解決連接配接的問題;特别是解決 Python 的問題, Python 實作的服務如果要獲得高并發度,一般是采取多程序模型,這意味着一個程序一個連接配接,特别是對于部署到 Docker 裡的 Python 服務,它可能一個容器裡啟動幾百個程序,如果直接連到 Broker ,這個 Broker 上的連接配接數可能到幾十上百萬,此時 CPU 軟中斷會非常高,導緻讀寫的延時的明顯上漲。
4,通過 Proxy ,多了一個代理,在消費不需要順序的情況下,我們可以支援更高的并發度, Consumer 的執行個體數可以超過 Consume Queue 的數量。
5,可以無縫的繼承其他的 MQ 。中間有一層 Proxy ,後面可以更改存儲引擎,這個對用戶端是無感覺的。
6,在 Conusmer 在更新或 Restart 的時候, Consumer 如果直接連 broker 的話, rebalance 觸發比較頻繁, 如果 rebalance 比較頻繁,且 Topic 量比較大的時候,可能會造成消息堆積,這個業務不是太接受的;如果加一層 Proxy 的話, rebalance 隻在 Proxt 和 Broker 之間進行,就不需要 Consumer 再進行一次 rebalance , Proxy 隻需要維護着和自己建立連接配接的 Consumer 就可以了。當消費者重新開機或更新的時候,可以最小程度的減少 rebalance 。
以上是我們通過 Proxy 接口給 RocketMQ 帶來的好處。因為多了一層,也會帶來額外的 Overhead 的,如下:
1,會消耗 CPU , Proxy 那一層會做RPC協定的序列化和反序列化。
如下是 Conusme Proxy 的結構圖,它帶來了消費并發度的提高。由于我們的 Broker 叢集是獨立部署的,考慮到broker主要是消耗包括網卡、磁盤和記憶體資源,對于 CPU 的消耗反而不高,這裡的解決方式直接進行混合部署,然後直接在新的機器上進行擴,但是 Broker 這邊的 CPU 也是可以得到利用的。
2,延遲問題。經過測試,在 4Kmsg、20W Tps 下,延遲會有所增加,大概是 1ms ,從 2ms 到 3ms 左右,這個時延對于業務來說是可以接受的。
下面看下 Consumer 這邊的邏輯,如下圖所示,
比如上面部署了兩個 Proxy , Broker,左邊有 6 個 Queue ,對于順序消息來說,左邊這邊 rebalance 是一個相對靜态的結果, Consumer 的上下線是比較頻繁的。對于順序消息來說,左邊和之前的邏輯是保持一緻的, Proxy 會為每個 Consumer 執行個體配置設定到合适的數量的 Queue ;對于不關心順序性的消息,Proxy 會把所有的消息都放到一個隊列裡,然後從這個隊列 dispatch 到各個 Consumer ,對于亂序消息來說,理論上來說 Consumer 數量可以無限擴充的;相對于和普通 Consumer 直連的情況,Consumer 的數量如果超過了Consume Queue的數量,其中多出來的 Consumer 是沒有辦法配置設定到 Queue 的,而且在容器部署環境下,單 Consumer 不能起太多線程去支撐高并發;在容器這個環境下,比較好的方式是多執行個體,然後按照 CPU 的核心數,啟動多個線程,比如 8C 的啟動 8 個線程,因為容器是有 Quota 的,一般是 1C,2C,4C,8C 這樣,這種情況下,如果線程數超過了 CPU 的核心數,其實對并發度并沒有太大的意義。
接下來,分享一下做這個接入方式的時候遇到的一些問題,如下圖所示:
1、消息大小的限制。
因為這裡有一層 RPC ,在 RPC 請求過程中會有單次請求大小的限制;另外一方面是 RocketMQ 的 producer 裡會有一個 MaxMessageSize 方法去控制消息不能超過這個大小; Broker 裡也有一個參數,是 Broker 啟動的配置,這個需要Broker重新開機,不然修改也不生效, Broker 裡面有一個 DefaultAppendMessage 配置,是在啟動的時候傳進去對的參數,如果僅 NameServer 線上變更是不生效的,而且超過這個大小會報錯。因為現在 RocketMQ 預設是 4M 的消息,如果将 RocketMQ 作為日志總線,可能消息體大小不是太夠, Procuer 和 Broker 是都需要做變更的。
2、多連接配接的問題。
如果看 RocketMQ 源碼會發現,多個 Producer 是共享一個底層的 MQ Client 執行個體的,因為一個 socket 連接配接吞吐是有限的,是以隻會和Broker建立一個socket連接配接。另外,我們也有 socket 與 socket 之間是隔離的,可以通過 Producer 的 setIntanceName() ,當與 DefaultI Instance 的 name 不一樣時會新啟動一個 Client 的,其實就是一個新的 socket 連接配接,對于有隔離需求的、連接配接池需求得等,這個參數是有用的,在 4.5.0 上新加了一個接口是指定構造的執行個體數量。
3、逾時設定。
因為多了一層 RPC ,那一層是有一個逾時設定的,這個會有點不一樣,因為我們的 RPC 請求裡會帶上逾時設定的,用戶端到 Proxy 有一個 RTT ,然後 Producer 到 Broker 的發送消息也是有一個請求響應延時,需要給 SDK 一個正确的逾時語義。
4、如何選擇一個合适的 reblance 算法,我們遇到這個問題是在雙機房同城容災的背景下,會有一邊 Topic 的 MessageQueue 沒有寫入。
這種情況下, RocketMQ 自己預設的是按照平均配置設定算法進行配置設定的,比如有 10 個 Queue , 3 個 Proxy 情況, 1、2、3 是對應 Proxy1,4、5、6 是對應 Proxy2,7、8、9、10 是對應 Proxy3 ,如果在雙機房同城容災部署情況下,一般有一半 Message Queue 是沒有寫入的,會有一大部分 Consumer 是啟動了,但是配置設定到的 Message Queue 是沒有消息寫入的。然後另外一個訴求是因為有跨機房的流量,是以他其實直接複用開源出來的 Consumer 的實作裡就有根據 MachineRoom 去做 reblance ,會就近配置設定你的 MessageQueue 。
5、在 Proxy 這邊需要做一個緩存,特别是拉消息的緩存。
特别提醒一下, Proxy 拉消息都是通過 Slave 去拉,不需要使用 Master 去拉, Master 的 IO 比較重;還有 Buffer 的管理,我們是遇到過這種問題的,如果隻考慮 Message 數量的話,會導緻 OOM ,是以要注意消息 size 的設定,
6、端到端壓縮。
因為 RocketMQ 在消息超過 4k 的時候, Producer 會進行壓縮。如果不在用戶端做壓縮,這還是涉及到 RPC 的問題, RPC 一般來說, Byte 類型,就是 Byte 數組類型它是不會進行壓縮的,隻是會進行一些正常的編碼,是以消息體需要在用戶端做壓縮。如果放在 Proxy 這邊做, Proxy 壓力會比較大,是以不如放在用戶端去承載這個壓縮。
前面大緻介紹了我們這邊大緻如何接入 RocketMQ ,如何實作這麼一套 Proxy ,以及在實作這套 Proxy 過程中遇到的一些問題。下面看一下災難恢複的方案,設計之初也參考了一些潛在相關方案。
第一種方案:擴充叢集,擴充叢集的方案就像下圖所示。
這是 master 和 slave 跨機房去部署的方式。因為我們有一層 proxy ,是以可以很友善的去做流量的排程,讓消息隻在一個主機房進行消息寫入,不需要一個類似中控功能的實體存在。
第二種方案:類似 MySQL 和 Redis 的架構模式,即單主模式,隻有一個地方式寫入的,如下圖所示。資料是通過 Mysql Matser/Slave 方式同步到另一個機房。這樣 RocketMQ 會啟動一個類似 Kafka 的 Mirror maker 類進行消息複制,這樣會多一倍的備援,實際上資料還會存在一些不一緻的問題。
第三種方案:雙寫加雙向複制的架構。這個結構太複雜不好控制,尤其是雙向複制,其中消息區回環的問題比較好解決,隻需針對在每個正常的業務消息,在 Header 裡加一個标志字段就好,另外的 Mirror 發現有這個字段就把這條消息直接丢掉即可。這個鍊路上維護複雜而且存在資料備援,其中最大問題是兩邊的資料不對等,在一邊挂掉情況下,對于一些無法接受資料不一緻的是有問題的。
此外,雙寫都是沒有 Mirror 的方案,如下圖所示。這也是我們最終選擇的方案。我們對有序消息和無序消息的處理方式不太一樣,針對無序消息隻需就近寫本機房就可以了,對于有序消息我們還是會有一個主機房,Proxy 會去 NameServer 拉取 Broker 的 Queue 資訊, Producer 将有序消息路由到一個指定主機房,消費端這一側,就是就近拉取消息。對于順序消息我們會采取一定的排程邏輯保證均衡的分擔壓力擷取消息,這個架構的優點是比較簡單,缺點是當叢集中一邊挂掉時,會造成有序消息的無序,這邊是通過記錄消息 offset 來處理的。
此外,還有一種獨立叢集部署的,相當于沒有上圖中間的有序消息那條線,因為大多數有序消息是整體體系的,服務要部署單元化,比如某些 uid 、訂單 Id 的消息或請求隻會落到一邊機房的,完全不用擔心消息來得時候是否需要按照某些 key 去指定 MessageQueue ,因為過來的消息必定是隸屬于這個機房的,也就是說中間有序消息那條線可以不用關心了,可以直接去掉。但是,這個是和整個公司部署方式以及單元化體系有關系的,對于部分業務我們是直接做到兩個叢集,兩邊的生産者、消費者、Broker 、Proxy 全部是隔離的,兩邊都互不發現,就是這麼一套運作方式,但是這就需要業務的上下遊要做到單元化的程度才可行。
以上就是 RocketMQ 在頭條的落地實踐頭條的容災系統建設分享,謝謝。
作者資訊:沈輝,畢業于北京郵電大學,就職于位元組跳動基礎架構,主要參與負責消息隊列服務的開發與維護。