簡介:
本文向您詳細介紹如何通過DataWorks資料同步功能,将Hadoop資料同步到阿裡雲Elasticsearch上,并進行搜尋分析。
本文字數:2673
閱讀時間:預計10分鐘
目錄
背景資訊
環境準備
資料準備
資料同步
結果驗證
資料搜尋與分析
以下是正文
您也可以使用Java代碼進行同步,具體請參考
通過ES-Hadoop将Hadoop資料寫入阿裡雲Elasticsearch和在
E-MapReduce中使用ES-Hadoop。
- 搭建Hadoop叢集。在進行資料同步前,您需要保證自己的Hadoop叢集環境正常。本文使用阿裡雲EMR服務自動化搭建Hadoop叢集,詳細過程請參見步驟三: 建立叢集 。EMR Hadoop的版本資訊如下。
- EMR版本:EMR-3.11.0
- 叢集類型:HADOOP
- 軟體資訊:HAFS2.7.2/YARN2.7.2/Hive2.3.3/Ganglia3.7.2/Spark2.3.1/HUE4.1.0/Zeppelin0.8.0/ Tez0.9.1 / Sqoop1.4.7 / Pig0.14.0 / ApacheDS2.0.0 / Knox0.13.0
- Hadoop叢集使用VPC網絡,區域為華東1(杭州),主執行個體組ECS計算ziyu 配置公網及内網IP,高可用選擇為否(非HA模式),具體配置如下圖所示

- 購買和配置Elasticsearch。登入 Elasticsearch控制台 ,參考 購買和配置 ,購買一個Elasticsearch執行個體。選擇與EMR叢集相同的區域和VPC網絡配置,如下圖所示。

【最佳實踐】如何運用DataWorks資料同步功能,将Hadoop資料同步到阿裡雲Elasticsearch上 - 建立DataWorks工作空間。 建立DataWorks 項目,區域選擇華東1區。本文直接使用已經存在的項目bigdata_DOC。
【最佳實踐】如何運用DataWorks資料同步功能,将Hadoop資料同步到阿裡雲Elasticsearch上
在Hadoop叢集中建立測試資料,步驟如下。
- 進入 EMR控制台界面 ,單擊左側菜單欄的互動式工作台。
- 選擇檔案 > 建立互動式任務。
- 在Notebook對話框中,輸入互動式任務的名稱,選擇預設類型以及關聯叢集,單擊确認。本文建立一個名為es_test_hive的互動式任務,預設類型為Hive,關聯叢集為 中建立的EMR Hadoop叢集。
- 在代碼編輯區域中,輸入Hive建表語句,單擊運作。本文檔使用的建表語句如下。
CREATE TABLE IF NOT
EXISTS hive_esdoc_good_sale(
create_time timestamp,
category STRING,
brand STRING,
buyer_id STRING,
trans_num BIGINT,
trans_amount DOUBLE,
click_cnt BIGINT
)
PARTITIONED BY (pt string) ROW FORMAT
DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n' 表建立成功後,系統會提示Query executed successfully。
- 單擊檔案 > 建立段落,在段落編輯區域輸入SQL語句,單擊運作,插入測試資料。
【最佳實踐】如何運用DataWorks資料同步功能,将Hadoop資料同步到阿裡雲Elasticsearch上
您可以選擇從OSS或其他資料源導入測試資料,也可以手動插入少量的測試資料。本文使用手動插入資料的方法,腳本如下。
jinsert into
hive_esdoc_good_sale PARTITION(pt =1 ) values('2018-08-21','外套','品牌A','lilei',3,500.6,7),('2018-08-22','生鮮','品牌B','lilei',1,303,8),('2018-08-22','外套','品牌C','hanmeimei',2,510,2),(2018-08-22,'衛浴','品牌A','hanmeimei',1,442.5,1),('2018-08-22','生鮮','品牌D','hanmeimei',2,234,3),('2018-08-23','外套','品牌B','jimmy',9,2000,7),('2018-08-23','生鮮','品牌A','jimmy',5,45.1,5),('2018-08-23','外套','品牌E','jimmy',5,100.2,4),('2018-08-24','生鮮','品牌G','peiqi',10,5560,7),('2018-08-24','衛浴','品牌F','peiqi',1,445.6,2),('2018-08-24','外套','品牌A','ray',3,777,3),('2018-08-24','衛浴','品牌G','ray',3,122,3),('2018-08-24','外套','品牌C','ray',1,62,7) ; - 使用同樣的方式建立段落,并在段落編輯區域輸入
`
-
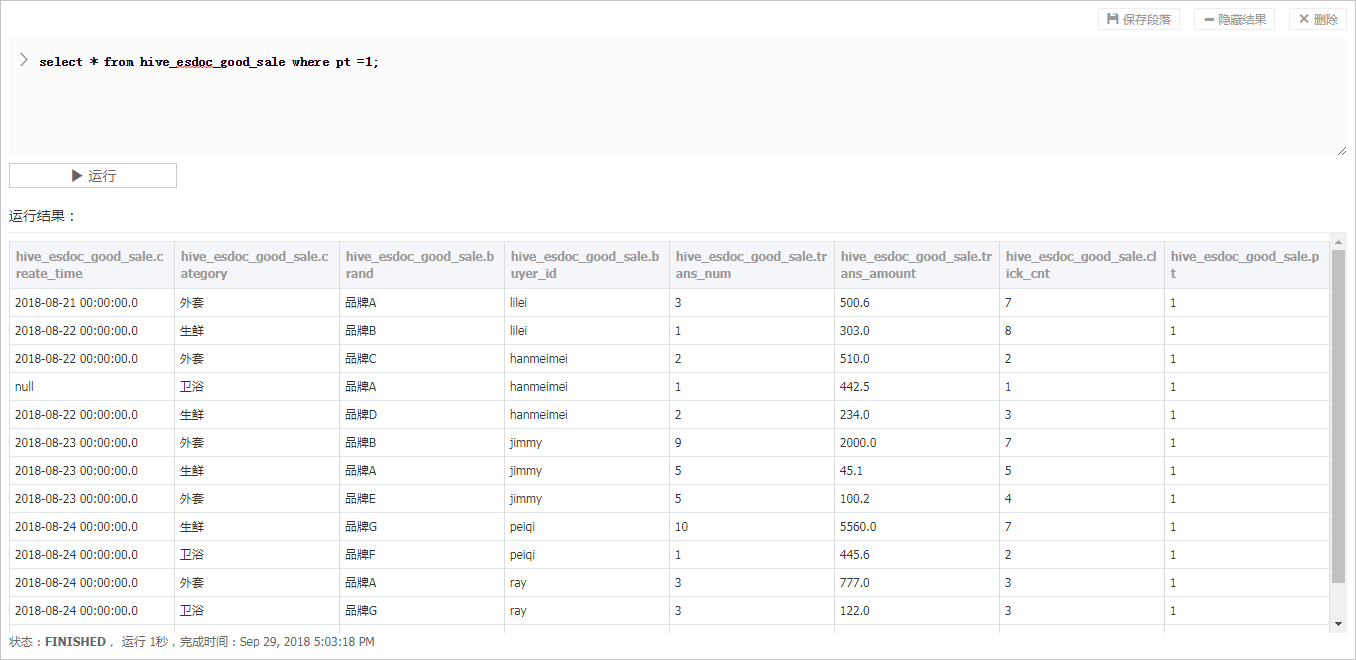
- from hive_esdoc_good_sale where pt =1;
語句,單擊**運作**。
此操作可以檢查Hadoop叢集表中是否已存在資料可用于同步,運作成功結果如下。
### 資料同步
> **說明
**
由于DataWorks項目所處的網絡環境與Hadoop叢集中的資料節點(Data Node)網絡通常不可達,是以您可以通過自定義資源組的方式,将DataWorks的同步任務運作在Hadoop叢集的Master節點上(Hadoop叢集内Master節點和資料節點通常可達)。
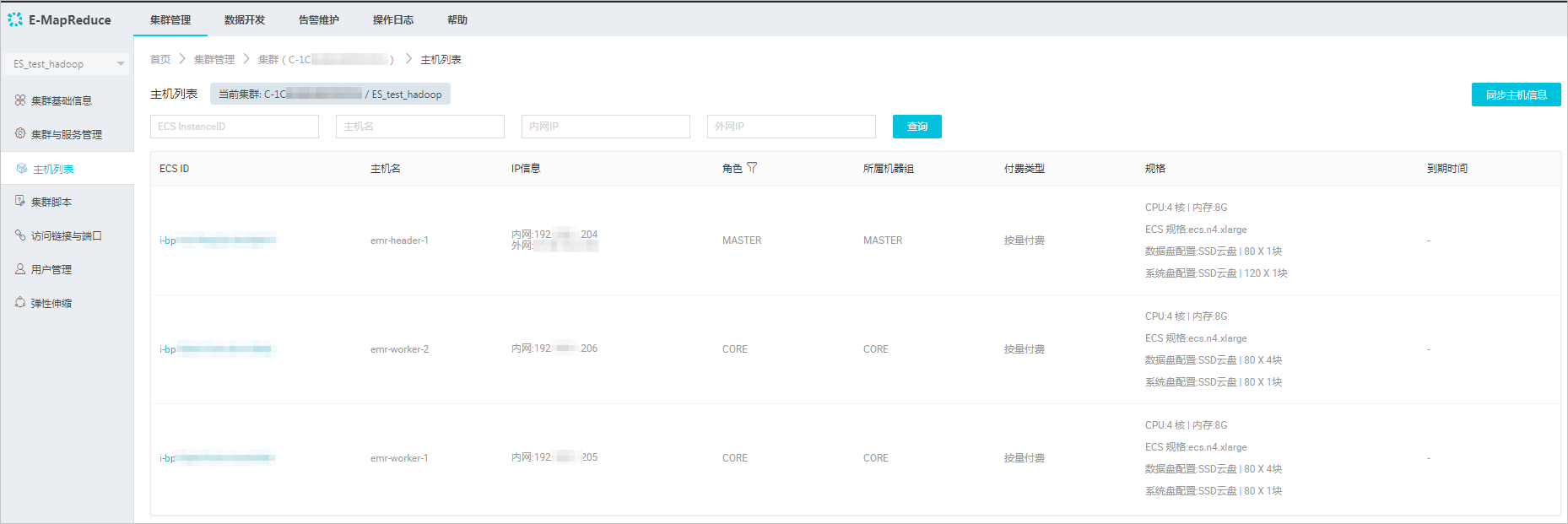
1. 檢視Hadoop叢集的資料節點。
- 在EMR控制台上,單擊左側菜單欄的叢集。
- 選擇您的叢集,單擊右側的管理。
- 在叢集管理控制台上,單擊左側菜單欄的主機清單,檢視叢集master節點和資料節點資訊。
> **說明
**
通常非HA模式的EMR上Hadoop叢集的Master節點主機名為emr-header-1,Data Node主機名為emr-worker-X。
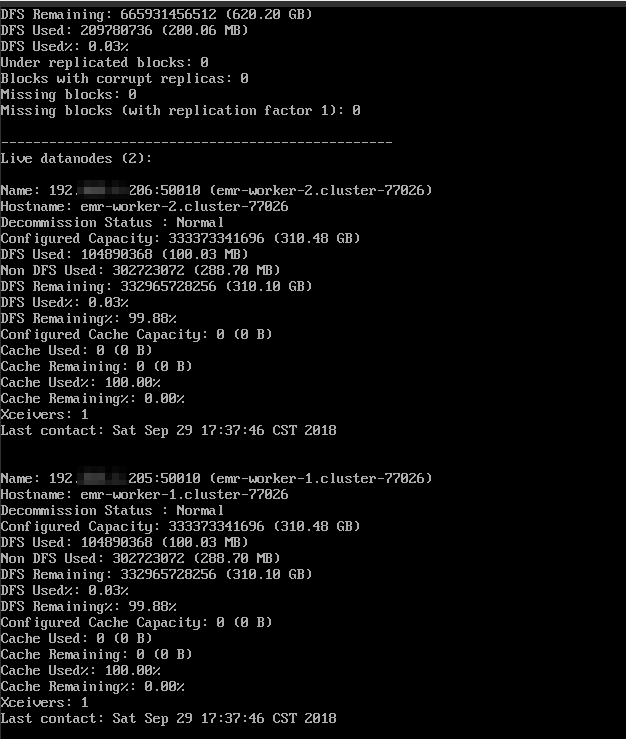
- 單擊上圖中Master節點的ECS ID,進入ECS執行個體詳情頁。單擊遠端連接配接進入ECS伺服器,通過hadoop dfsadmin -report指令檢視資料節點資訊。
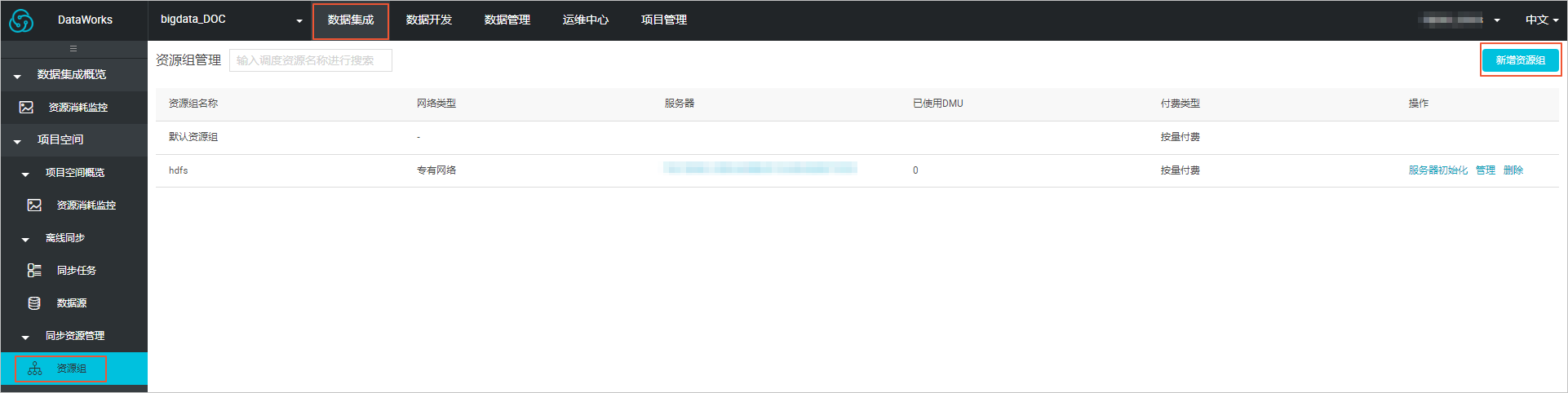
2. 建立自定義資源組。
- 進入DataWorks的**資料內建**頁面,選擇**資源組** > **新增資源組**。
關于自定義資源組的詳細資訊請參見[新增任務資源](https://help.aliyun.com/document_detail/72979.html?spm=a2c4g.11186623.2.31.341d491ecP7i8I#concept-wfz-j45-q2b)。
- 根據界面提示,輸入資源組名稱和伺服器資訊。此伺服器為您EMR叢集的Master節點,伺服器資訊說明如下。
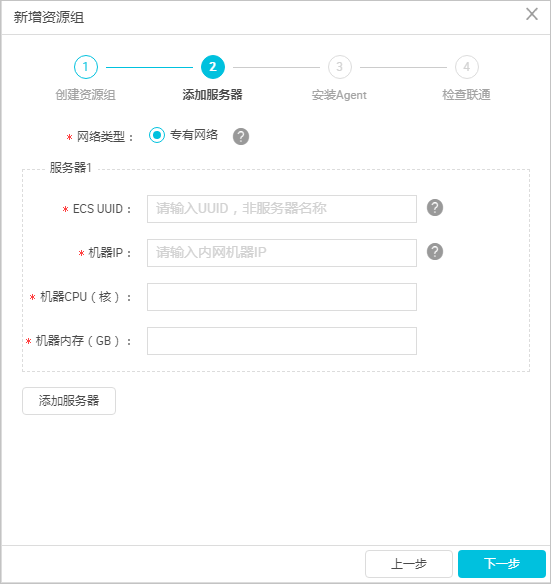
> **注意 **完成添加伺服器後,您需要保證Master Node與DataWorks網絡可達。
- 如果您使用的是ECS伺服器,需設定伺服器的安全組。
- 如果您使用的内網IP互通,需要[添加安全組。](https://help.aliyun.com/document_detail/72978.html?spm=a2c4g.11186623.2.33.341d491ecP7i8I#concept-ec4-cj5-q2b)
- 如果您使用的是公網IP,可直接設定安全組公網出入方向規則。
由于本文檔的EMR叢集使用的是VPC網絡,且與DataWorks在同一區域下,是以不需要進行安全組設定。
- 按照提示安裝自定義資源組Agent。
> **注意**:由于本文使用的是VPC網絡類型,是以不需開通8000端口。
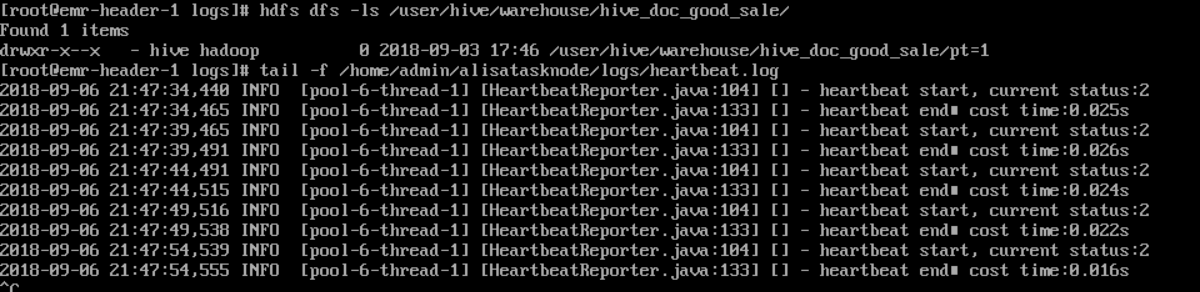
觀察到目前狀态為**可用**時,說明新增自定義資源組成功。如果狀态為不可用,您可以登入Master Node,使用```js
tail –f/home/admin/alisatasknode/logs/heartbeat.log
命```
令檢視DataWorks與Master Node之間心跳封包是否逾時。
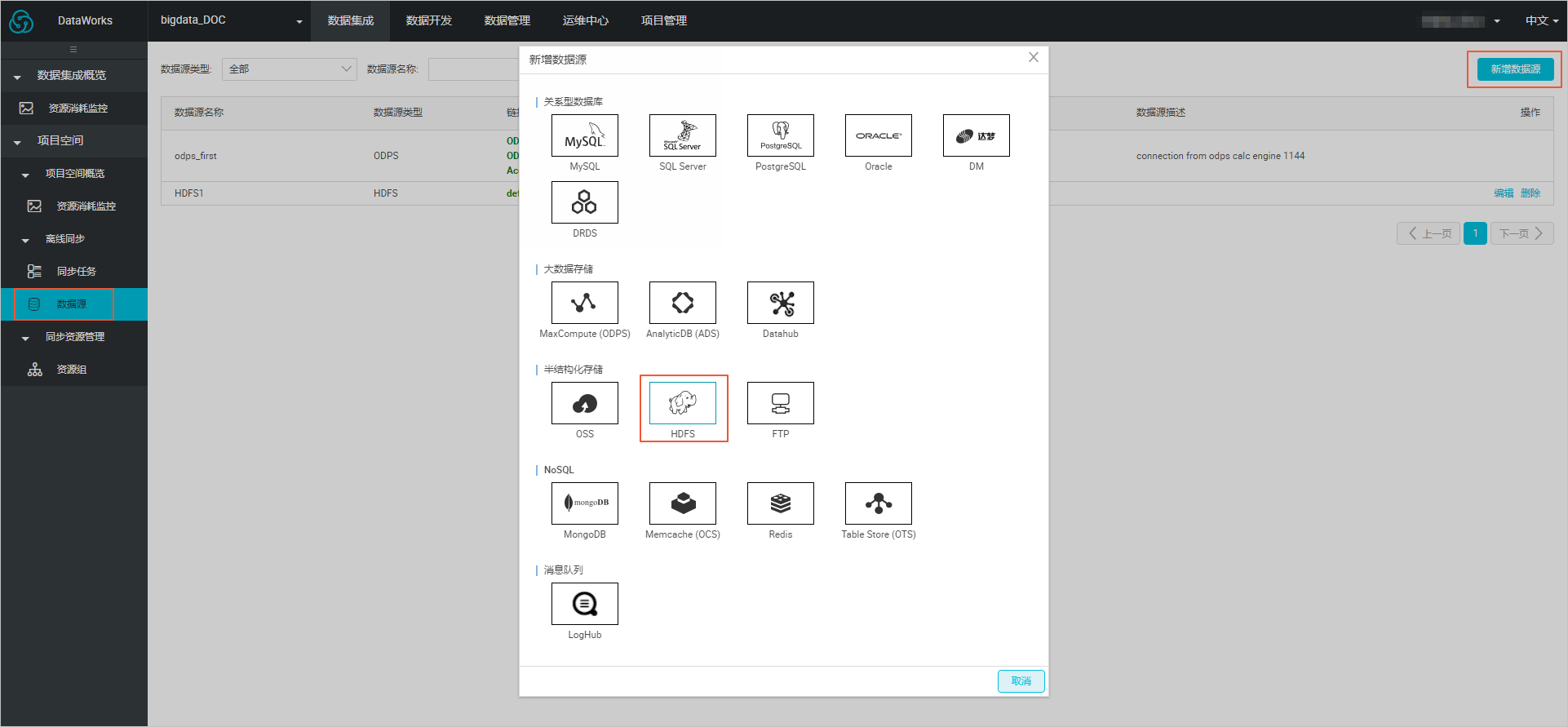
3. 建立資料源
- 在DataWorks的資料內建頁面,單擊**資料源**>**新增資料源**,在彈框中選擇**HDFS**類型的資料源
- 在**新增HDFS**資料源頁面中,填寫**資料源名稱**和**defaultFS。**
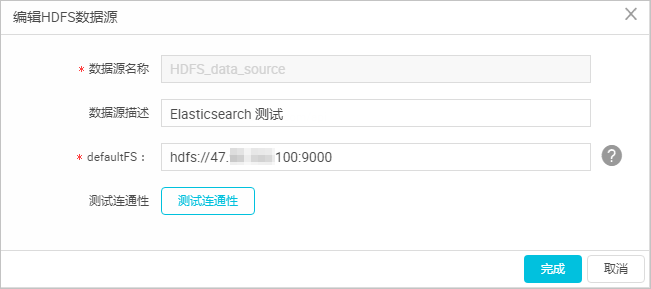
> 注意 對于EMR Hadoop叢集而言,如果Hadoop叢集為非HA叢集,則此處位址為```js
hdfs://emr-header-1的IP:9000
。```
如果Hadoop叢集為HA叢集,則此處位址為```js
hdfs://emr-header-1的IP:8020
。```
在本文中,emr-header-1與DataWorks通過VPC網絡連接配接,是以此處填寫内網IP,且不支援連通性測試。
4. 配置資料同步任務。
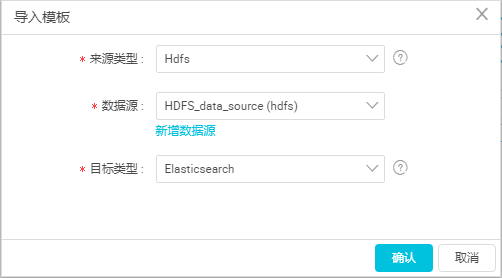
a. 在DataWorks資料內建頁面,單擊左側菜單欄的**同步任務**,選擇**建立** > **腳本模式**。
b. 在**導入模闆**對話框中,選擇資料源類型如下,單擊**确認**。
c. 完成導入模闆後,同步任務會轉入[腳本模式](https://help.aliyun.com/document_detail/74304.html?spm=a2c4g.11186623.2.38.341d491ecP7i8I#concept-olb-drc-p2b),本文中配置腳本如下,相關解釋請參見腳本模式配置,Elasticsearch的配置規則請參考[配置Elasticsearch Writer。](https://help.aliyun.com/document_detail/74362.html?spm=a2c4g.11186623.2.39.341d491ecP7i8I#concept-okj-c24-q2b)
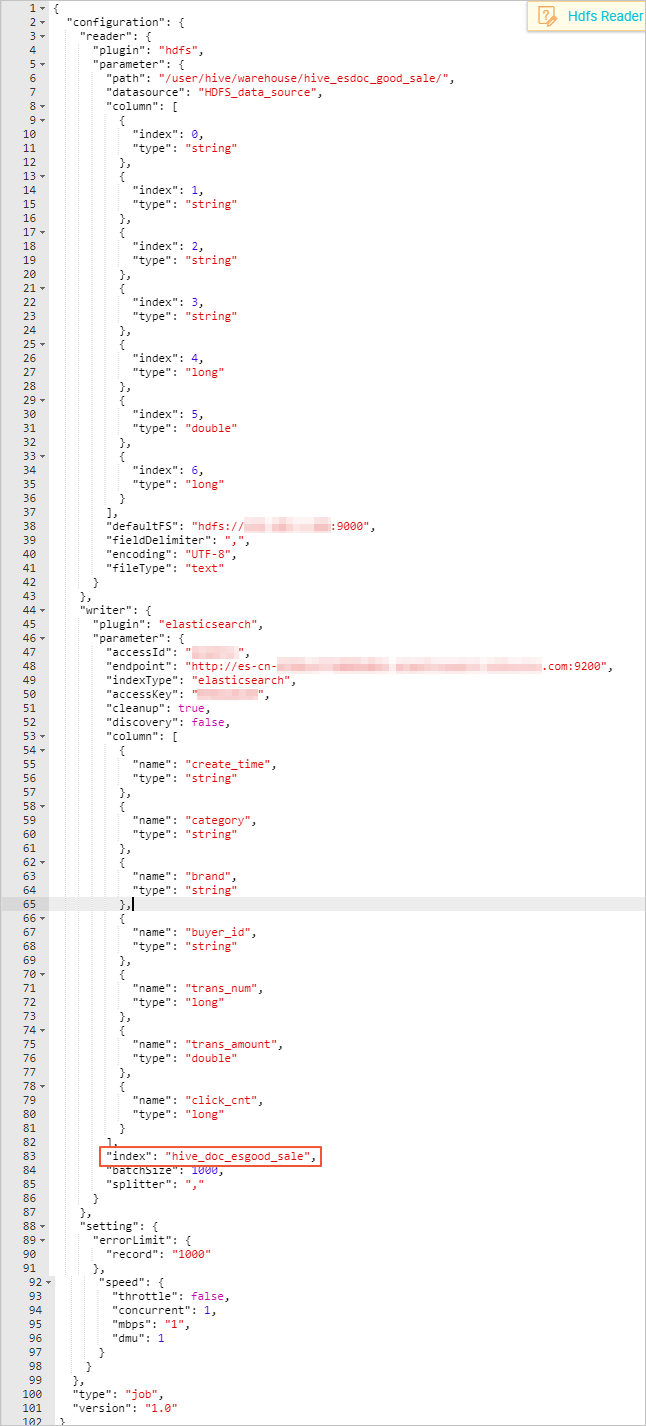
- 同步腳本的配置分為三個部分,Reader用來配置您上遊資料源(待同步資料的雲産品)的config,Writer用來配置 Elasticsearch的config,setting用來配置同步中的一些丢包和最大并發等。
- path為資料在Hadoop叢集中存放的位置,您可以在登入master node後,```js
使用hdfs dfs –ls /user/hive/warehouse/hive_esdoc_good_sale
命```
令确認。對于分區表,您可以不指定分區,DataWorks資料同步會自動遞歸到分區路徑。
- 由于Elasticsearch不支援timestamp類型,本文檔将**creat_time**字段的類型設定為string。
- **endpoint**為Elasticsearch 的内網或外網位址。如果您使用的是内網位址,請在Elasticsearch的叢集配置頁面,配置Elasticsearch的系統白名單。如果您是用的是外網位址,請在Elasticsearch的網絡配置頁面,配置 Elasticsearch的公網位址通路白名單(包括DataWorks伺服器的IP位址和您所使用的資源組的IP位址)。
- Elasticsearch Writer中**accessId**和**accessKey**需要配置您的Elasticsearch的通路使用者名(預設為elastic)和密碼。
- **index**為Elasticsearch執行個體的索引,您需要使用該索引名稱通路Elasticsearch的資料。
- 在建立同步任務時,DataWorks的預設配置腳本中,**errorLimit**的**record**字段值為0,您需要将其修改為大一些的數值,比如1000。
d. 完成配置後,單擊頁面右側的**配置任務資源組**,選擇您建立的資源組名稱,完成後單擊**運作**。如果提示**任務運作成功**,則說明同步任務已完成。如果運作失敗,可通過複制日志進行進一步排查。
### 結果驗證
1. 進入[Elasticsearch控制台](https://elasticsearch.console.aliyun.com/?spm=a2c4g.11186623.2.41.341d491ecP7i8I),單擊執行個體名稱>可視化控制,在Kibana區域中,單擊右下角進入控制台。
2. 輸入使用者名和密碼,單擊登入進入kibana控制台,選擇Dev Tools。
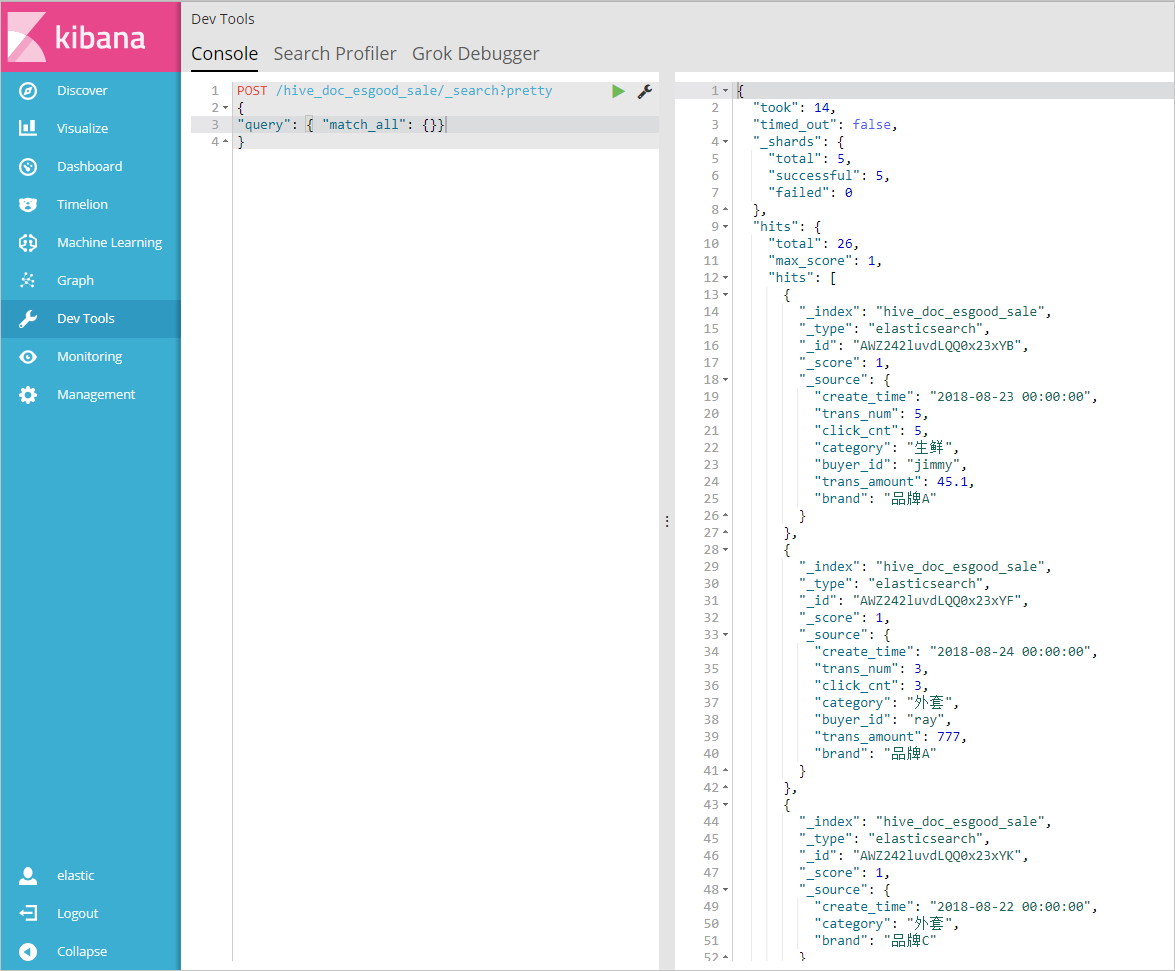
3. 在**Console**控制台中,執行如下指令,檢視已經同步過來的資料 POST /hive_doc_esgood_sale/_search?pretty
{
"query": { "match_all": {}}
}
```hive_doc_esgood_sale``` 為您同步資料時,設定的index字段的值。
### 資料搜尋與分析
1. 在**Console**控制台中,執行如下指令,傳回品牌為A的所有文檔。
"query": { "match_all": {} },
"sort": { "click_cnt": { "order": "desc" } },
"_source": ["category", "brand","click_cnt"]
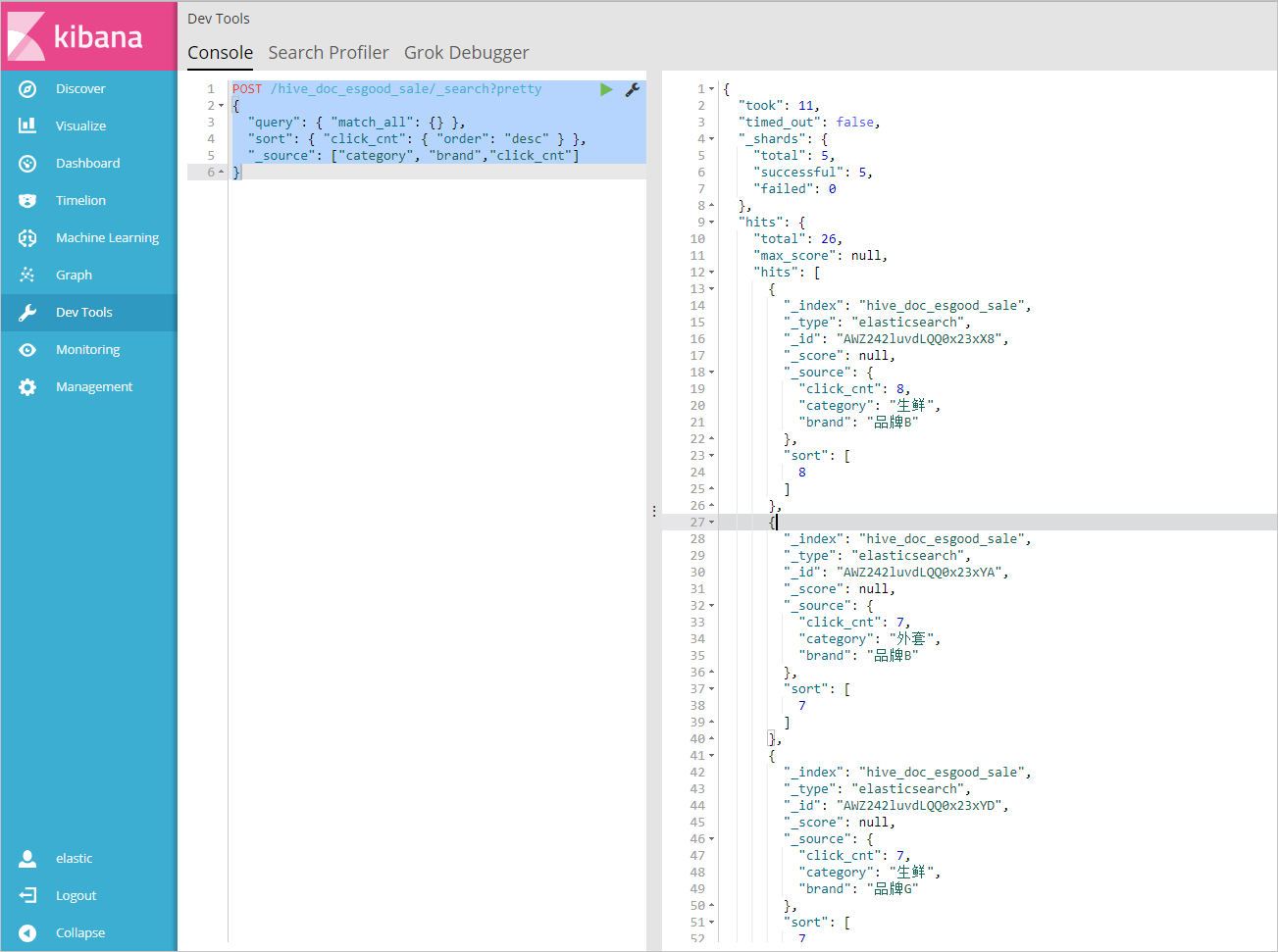
2. 在**Console**控制台中,執行如下指令,按照**點選次數**進行排序,判斷各品牌産品的熱度。
`
更多指令和通路方式,請參見阿裡雲
Elasticsearch官方文檔和
Elastic.co官方幫助中心加入我們
加入《Elasticsearch中文技術社群》,與更多開發者探讨交流
訂閱《阿裡雲Elasticsearch技術交流期刊》每月定期為大家推送相關幹貨
2019年阿裡雲雲栖大會上,Elasticsearch背後的商業公司Elastic與阿裡雲Elasticsearch确定戰略合作更新,在100%相容開源的基礎上,完成了ELK的完整生态雲上閉環,歡迎開通使用。
點選了解更多産品資訊