一、解決的問題
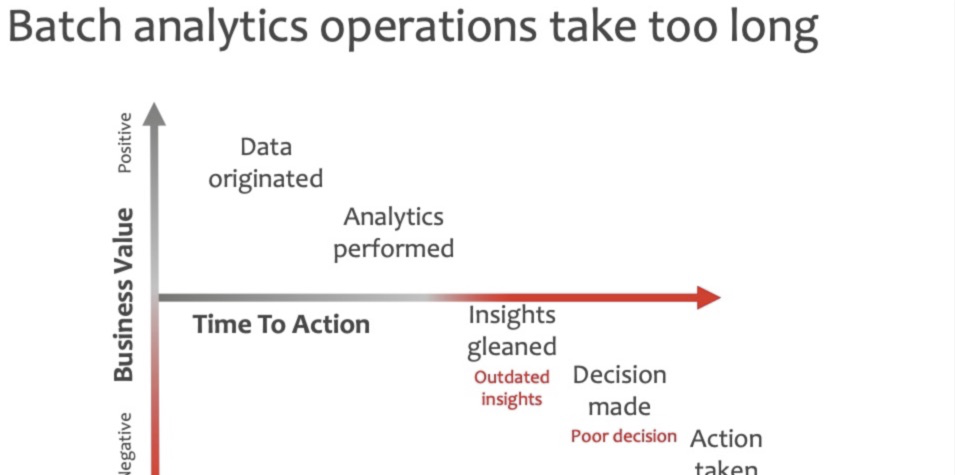
- 資料是實時産生的,對資料進行批處理所花費的成本太高了,資料産生的價值被低估
基于資料流的異常檢測:Robust Random Cut Forest - 在高維資料下,如何能發現異常的次元?
If my time-series data with 30 features yields an unusually high anomaly score. How do I explain why this particular point in the time-series is unusual? Ideally I'm looking for some way to visualize "feature importance" for a specific data point.
二、業内的解決方案
1、Numenta公司提出的HTM算法模型
- 背景:在大多數情況下,傳感器流的數量很大,人類很少有機會,更不用說專家幹預了。 是以,以無人監督的自動方式(例如,無需手動參數調整)操作通常是必要的。 底層系統通常是非平穩的,探測器必須不斷學習和适應不斷變化的統計資料,同時進行預測。 Hierarchical Temporal Memory (HTM)網絡以有原則的方式在各種條件下穩健地檢測異常。
- 生産系統應該是高效的,非常容忍噪聲資料,不斷使用資料統計的變化,并檢測非常微妙的異常,同時最大限度地減少誤報。該算法在實時金融異常檢測中表現較好,切已經得到商業化部署。HTM與序列預測中的一些現有算法相比是有利的,特别是複雜的非馬爾可夫序列,HTM不斷學習系統,自動适應不斷變化的統計資料,這是一種與流分析特别相關的屬性。
- 該公司開發的Grok系統,目前服務在AWS,針對實體機器進行異常檢測。The Leading AIOPS Platform For Intelligent Incident Prediction And Self-Healing Operations In IT Service Assurance
2、Amazon Kinesis
2.1 應用場景
- AWS Metering
- Amazon S3 events
- Amazon Cloud Watch Logs
- Amazon.com online catalog
- Amazon Go Video analysis
2.2 Kinesis - RRCF調用方式
-- creates a temporary stream.
CREATE OR REPLACE STREAM "TEMP_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- creates another stream for application output.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- Compute an anomaly score for each record in the input stream
-- using Random Cut Forest
CREATE OR REPLACE PUMP "STREAM_PUMP" AS
INSERT INTO "TEMP STREAM"
SELECT STREAM "passengers", "distance", ANOMALY_SCORE
FROM TABLE (RANDOM_CUT_FOREST (
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM")))
-- Sort records by descending anomaly score, insert into output stream
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM * FROM "TEMP_STREAM"
ORDER BY FLOOR("TEMP_STREAM".ROWTIME TO SECOND), ANOMALY_SCORE
DESC; 3、Azure IoT Edge, Azure Stream Analytic

- 下面的示例查詢假設在2分鐘的滑動視窗中以每秒120個事件的曆史記錄來統一輸入每秒事件的速率。 最終的SELECT語句提取并輸出得分和異常狀态,置信度為95%。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep 4、SLS @ Alibaba Cloud
三、算法原理
3.0、無監督樹形異常檢測算法發展曆程
- 2008 - Isolation Forest Published
- 2013 - Survey on outlier detection
- 2016 - RRCF published in JMLR
- 2016 - RRCF available on Amazon Kinesis
- 2018 - RRCF available on Hydroserving
3.1 2008年Isolate Forest原理
1. 單棵樹的建構過程
iTree是一種随機二叉樹,每個節點要麼有兩個孩子,要麼就是葉子節點,每個節點包含一個屬性q和一個劃分值p。
具體的建構過程如下:
- 從原始訓練集合X種無放回的抽取樣本子集
- 劃分樣本子集,每次劃分都從樣本中随機選擇一個屬性q,再從該屬性中随機選擇一個劃分的值p,該p值介于屬性q的最大與最小值之間
- 根據2中的屬性q與值p,劃分目前樣本子集,小于值p的樣本作為目前節點的左孩子,大于p值的樣本作為目前的右孩子
- 重複上述2,3步驟,遞歸建構每個節點的左、右孩子節點,知道滿足終止條件為止,通常終止條件為所有節點均隻包含一個樣本或者多個相同的樣本,或者樹的深度達到了限定的高度
2. 建構參數的說明
有兩個參數控制着模型的複雜度:
- 每棵樹的樣本子集大小,它控制着訓練資料的大小,論文中的實驗發現,當該值增加到一定程度後,IForest的辨識能力會變得可靠,但沒有必要繼續增加下去,因為這并不會帶來準确率的提升,反而會影響計算時間和記憶體容量,論文實作發現該參數取256對于很多資料集已經足夠;
- 內建的樹的數量,也可以了解為對原始資料的采樣的次數,它控制着模型的內建度,論文中描述取值100就可以了;
3. 如何衡量樣本的異常值
4. 一些缺點
- Contains all points
- Every leaf contains one distinct point
- Each node separates bounding box of it's points in two halves
3.2 2016年RRCF原理
0. 為何會引入RRCF算法?
- 資料是持續産生的,資料中的時間戳是一個重要因素,而這個次元卻經常被大家忽略
- 資料的結構和形态是未知的,需要設計一個魯棒性的算法來應對各種複雜的場景需求
- iTree是針對候選資料,進行N次無放回的采樣,通過對靜态資料集進行劃分而得到。若針對流式資料,每次都要針對最新的資料進行采樣,再去構造資料集,運作算法,得到相應的結果;
- 在針對流式資料的異常檢測場景中,缺少對序列中時序的關系的考慮,算法僅僅把目前的點當做孤立的點進行模組化;
1. 針對資料流進行采樣模組化
針對第一個上述的第一個問題:
- 可以采用一些采樣政策(蓄水池采樣)能準确的目前的資料點是否參與異常模組化;
- 同時指定一個時間視窗長度,當模組化的資料過期後,應該從模型中剔除掉;
2. 算法中核心的幾個操作
- 構造Robust Random Cut Tree操作
基于資料流的異常檢測:Robust Random Cut Forest - 從一個Tree中删除某個樣本
基于資料流的異常檢測:Robust Random Cut Forest - 插入一個新的樣本到樹結構中
基于資料流的異常檢測:Robust Random Cut Forest
- 引用論文中的一段話
Let 0 be a left decision and 1 be a right decision. Thus,for x ∈ S, we can write its path as a binary string in the same manner of the isolation forest, m(x). We can repeat this for all x ∈ S and arrive at a complete model description:M(S) = ⊕x∈Sm(x), the appending of all our m(x) together. We will consider the anomaly score of a point x to be the degree to which including it causes our model description to change if we include it or not,
- 形象化的描述如下所示
基于資料流的異常檢測:Robust Random Cut Forest
上圖左側表示構造出來的樹的結構,其中x是我們待處理的樣本點,有圖表示将該樣本點删除後,動态調整樹結構的形态。其中$q_0,...,q_r$表示從樹的根節點編碼到a節點的描述串。
- 利用上述公式的描述,可以得到具體的衡量分數,但是如果将上述分數直接轉換為異常值,還需要算法同學根據自己的場景進行合理的轉換
3.3 流式改造 - 蓄水池采樣算法
- 算法大緻描述:給定一個資料流,資料流長度N很大,且N直到處理完所有資料之前都不可知,請問如何在隻周遊一遍資料(O(N))的情況下,能夠随機選取出m個不重複的資料。
- 具體的僞代碼描述
int[] reservoir = new int[m];
// init
for (int i = 0; i < reservoir.length; i++)
{
reservoir[i] = dataStream[i];
}
for (int i = m; i < dataStream.length; i++)
{
// 随機獲得一個[0, i]内的随機整數
int d = rand.nextInt(i + 1);
// 如果随機整數落在[0, m-1]範圍内,則替換蓄水池中的元素
if (d < m)
{
reservoir[d] = dataStream[i];
}
} 通過對資料流進行采樣,可以較好的從資料流中等機率的進行采樣,通過RRCF中提供的DELETE方法,可以将置換出模型的資料動态的删除掉,将新選擇的樣本資料動态的加入到已經有的樹中去,進而得到對應的CODISP值。
3.4 并行調用的改造
該算法同Isolation Forest算法一樣,非常适合并行建構,在此不做太多的贅述,推薦讀者使用Python一個并行的軟體包Joblib,能非常友善的幫助使用者開發。
傳送門:Joblib: running Python functions as pipeline jobs
四、算法實驗結果
4.1 多元度的流量場景實驗
- 實驗資料說明:(時間戳,流量,平均請求延遲,通路次數),資料每5秒聚合一個點
- 該實驗結果是使用全量的資料進行RRCF樹的構造,在對結果中的全部葉子節點去擷取對應的CODISP值,可視化如下結果,其中第一條曲線表示:網站每5秒的請求流量情況;第二條曲線表示:網站每5秒的平均請求延遲情況;第三條曲線表示:網站每5秒的通路次數情況;第四條曲線表示:每個點的CODISP值的大小;
- 在實際場景中,可以通過對CODISP值的判别來判定具體點是否是異常;
基于資料流的異常檢測:Robust Random Cut Forest - 使用資料的前1024個點做為基礎模型的資料,去構造100棵樹;針對餘下的資料點逐點輸入算法中去,采用蓄水池采樣的政策,動态的對樹内部的有效點進行增删,實時得到最新點的CODISP值,繪制結果如下圖所示;
基于資料流的異常檢測:Robust Random Cut Forest
4.2 如何将CODISP分數轉換成異常值
- 了解下算法的本質:某個點的删除,導緻整體樹結構發生變化的程度(目前使用受影響程度正比于樹種點的數量),對于一個确定容量的樹來說,可以通過設定具體的門檻值,來判别異常
- 可以針對CODISP使用K-Sigma算法,得到具體的上界異常值
4.3 如何對檢測到的異常進行可解釋性描述
- 該部分比較複雜,請等下一篇文章的分享
參考文獻
- Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. "Robust random cut forest based anomaly detection on streams." In International Conference on Machine Learning, pp. 2712-2721. 2016.
- Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova, and Al Geist. "Reservoir-based random sampling with replacement from data stream." In Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
- http://proceedings.mlr.press/v48/guha16-supp.pdf
- Implementation of the Robust Random Cut Forest Algorithm for anomaly detection on streams. https://klabum.github.io/rrcf/scoring-rctree.html
- 亞馬遜中關于該算法的參數說明 https://docs.aws.amazon.com/zh_cn/kinesisanalytics/latest/sqlref/sqlrf-random-cut-forest-with-explanation.html
- 亞馬遜中關于該算法的具體例子說明 https://docs.aws.amazon.com/zh_cn/kinesisanalytics/latest/dev/app-anomaly-detection.html