内容來源:宜信技術學院第4期技術沙龍-線上直播|宜信微服務任務排程平台建設實踐
主講人:宜信進階架構師&開發平台負責人 梁鑫
導讀:如今,無論是網際網路應用還是企業級應用,都充斥着大量的批處理任務,常常需要一些任務排程系統幫助我們解決問題。随着微服務化架構的逐漸演進,單體架構逐漸演變為分布式、微服務架構。
在此背景下,很多之前的任務排程平台已經不能滿足業務系統的需求,于是出現了一些基于分布式的任務排程平台。這些平台各有其特點,但也各有不足之處,比如不支援任務編排、與業務高耦合、不支援跨平台等問題,不是非常符合公司的需求,是以我們開發了微服務任務排程平台(SIA-TASK)。本次分享主要圍繞SIA平台展開,包括研發背景設計思路和技術架構,以及如何支援業務方。
一、SIA-TASK的産生
1.1 背景
無論是網際網路應用還是企業級應用,都充斥着大量的批處理任務,常常需要一些任務排程系統幫助我們解決問題。随着微服務化架構的逐漸演進,單體架構逐漸演變為分布式、微服務架構。
在這樣的背景下,很多之前的任務排程平台或元件已經不能滿足業務系統的需求,于是出現了一些基于分布式的任務排程平台。這些平台各有其特點,但也各有不足之處,比如不支援任務編排、與業務高耦合、不支援跨平台等問題。
1.2 種類
按照任務與時間的關系,我們把批處理任務分成三類,飛機型、地鐵型、公共汽車型。
- 飛機型是指每年/月/周/天固定某一時刻執行的任務。這種任務在我們的業務系統中非常常見,比如每天1點要執行一個跑批任務去清理前一天的日志;每月10号要給公司全員發工資,這些都屬于飛機型任務。
- 地鐵型是指每隔固定時間執行任務,不可并發。我們也經常遇到這樣的批處理任務,第一個任務沒有結束,第二個任務是不可以執行的,這就是不可并發。
- 公共汽車型是指每隔固定時間執行任務,可并發。如果是公共汽車型的任務,前一個任務沒有結束,下一個任務也可以按點開始執行。
1.3 問題
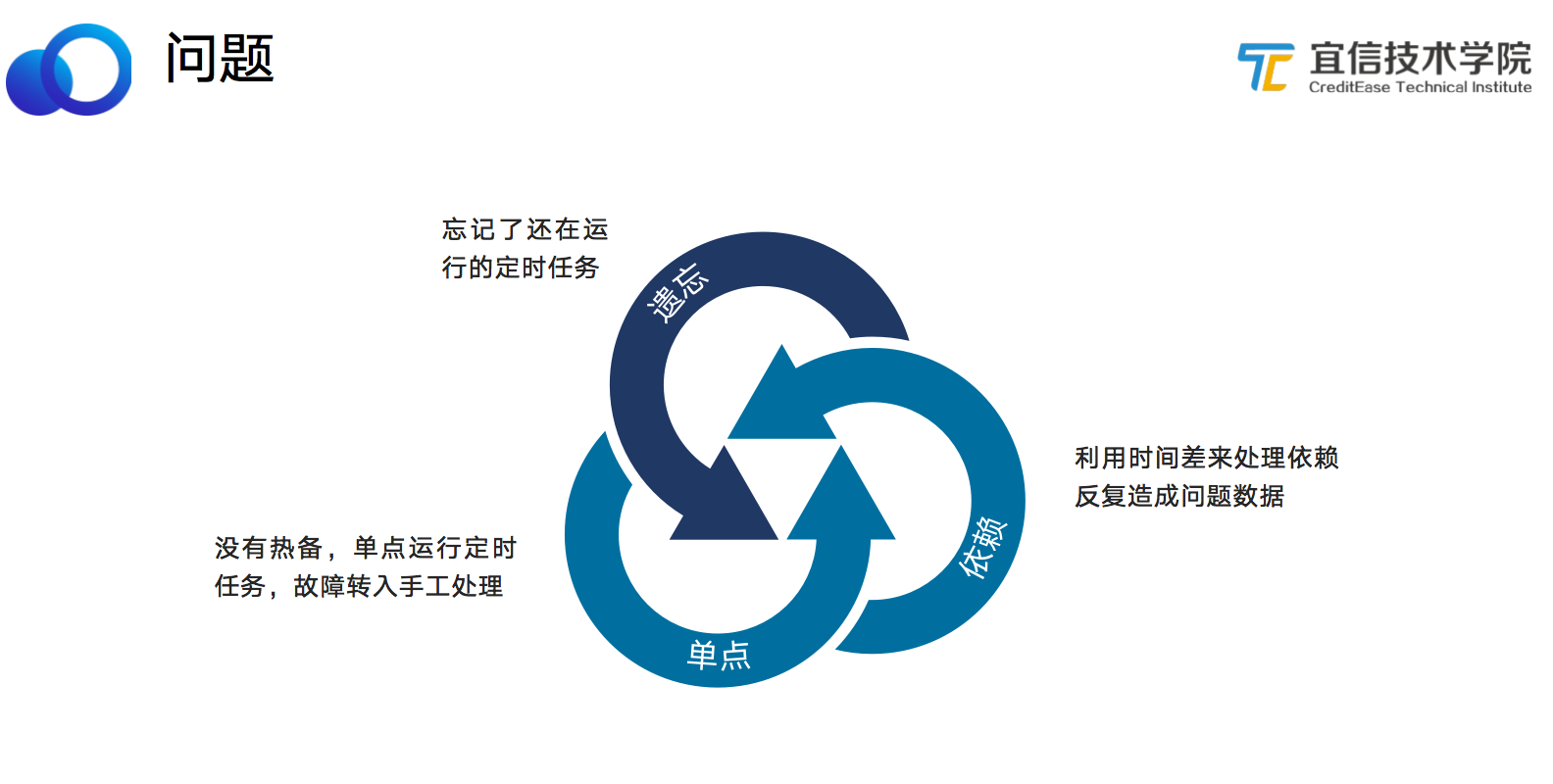
在跑批任務的過程中會遇到以下問題:
- 遺忘,忘記了還在運作的定時任務。在我們公司發生過一個這樣的案例,若幹年前的一個冬天,我們的一個項目團隊用3個月的時間做了一個項目,運作一段時間後發現項目的效果并不是很理想,便将相關的程式都停掉了,卻忘了有一個跑批任務的節點還在繼續運作,直到兩年後,這個節點産生的日志把磁盤填滿了,觸發了監控報警,我們才發現。
- 單點,就是沒有熱備,跑批任務是一個單點運作的定時任務,出了故障需要轉入手工處理。
- 依賴,利用時間差來處理依賴反複造成問題資料。大家知道項目有的時候是需要有依賴關系的。比如某個項目的跑批流程A和跑批流程B存在先後次序,項目組設定跑批流程A在淩晨2點運作,跑批流程B在淩晨4點運作,從時間上保證先後次序,萬一跑批流程A執行時間過長,超過2小時,就會導緻資料出現問題,需要手工處理出現問題的資料。
1.4 關系
前文提到任務之間是有關系的,那到底存在哪些關系呢?我認為主要有以下3種:
- 串行,存在先後關系的兩個任務。即任務B在任務A後執行,要先執行任務A之後再執行任務B。
- 并行,可以并發執行的兩個任務。比如任務B和C都要在任務A之後執行,而任務A執行完成後,任務B和C可以同時執行,那B和C就是并行關系。
- 分支,根據前置任務的傳回結果進行判斷,不同的結果執行不同的後續任務。比如傳回0的時候,執行任務A,傳回1的時候執行任務B,這是一種分支的情況。
1.5 思考
基于上述的幾種關系,我們在建設任務排程平台的時候會思考以下兩個方面:
- 平台化。項目團隊總是希望把更多的精力投入到業務開發中,希望把其它與業務開發無關的事情盡可能地放到架構團隊。他們希望有一個執行任務的平台,僅僅需要把編寫好的業務邏輯放到這個平台就可以了,這個平台會完成所有的工作,項目組隻需要關心業務邏輯。
- 微服務。為了更好地滿足項目的需求,我們希望能把任務的業務邏輯和任務的編排排程區隔開來,采用注冊和發現機制來建設任務排程平台,與業務相關的部分交給項目團隊處理,把其他的部分交給任務平台來處理。
1.6 因素
除了上述兩個方面的考慮以外,我們還需要思考以下八個因素。
- 任務編排。多個業務之間的定時任務存在流程次序,前面提到任務之間有并行的關系、有串行的關系,還有分支的關系,我們希望平台能有相應的編排功能去處理和支援這些任務。
- 任務分片。對于一個大型任務,需要分片并行執行。
- 跨平台。除了使用 Java 技術棧(SpringBoot、Spring等)的項目之外,還要能夠支援使用其他語言的應用。
- 無侵入。業務不希望與排程高耦合,隻關注業務的執行邏輯,希望平台對業務本身代碼是無侵入的,将影響降到最低。
- 高可用/故障轉移。排程系統自身必須保證高可用,不能有單點,任務執行過程中遇到問題有補償措施,能夠平滑處理,減少人工介入。
- 可視化。任務排程的操作提供可視化頁面,友善使用。
- 實時監控。平台要有實時監控系統,實時擷取任務的執行狀态。
- 動态編輯。業務的任務時鐘參數可能變動,在可視化的基礎上,對所有任務執行的操作都實時反映到業務系統中去,不需要停機部署。
基于以上的背景與考慮,我們建設了微服務任務排程平台SIA-Task。
二、SIA-TASK的核心設計思想
2.1 簡介
SIA是“Simple is Awesome”的簡稱。
SIA-TASK(微服務任務排程平台)是其中的一項重要産品,SIA-Task契合目前微服務架構模式,具有跨平台、可編排、高可用、無侵入、一緻性、異步并行、動态擴充、實時監控等特點。
SIA-TASK是任務排程的一體式解決方案,對任務進行中繼資料采集,然後進行任務可視化編排,最終進行任務排程,并且對任務采取全流程監控,簡單易用。對業務完全無侵入,通過簡單靈活的配置即可生成符合預期的任務排程模型。
SIA-TASK借鑒微服務的設計思想,擷取分布在每個任務執行器上的任務中繼資料,上傳到任務注冊中心。利用線上方式進行任務編排,可動态修改任務時鐘,采用HTTP作為任務排程協定,統一使用JSON資料格式,由排程中心進行時鐘解析,執行任務流程,進行任務通知。
2.2 術語
簡單介紹一下SIA-TASK的術語。
- 任務(Task): 基本執行單元,執行器對外暴露的一個HTTP調用接口;
- 作業(Job): 由一個或者多個存在互相邏輯關系(串行/并行)的任務組成,任務排程中心排程的最小機關;
- 計劃(Plan): 由若幹個順序執行的作業組成,每個作業都有自己的執行周期,計劃沒有執行周期;
- 任務排程中心(Scheduler): 根據每個的作業的執行周期進行排程,即按照計劃、作業、任務的邏輯進行HTTP請求,它是一個單獨的節點;
- 任務編排中心(Config): 編排中心使用任務來建立計劃和作業;
- 任務執行器(Executer): 接收HTTP請求進行業務邏輯的執行;
- Hunter:Spring項目擴充包,負責執行器中的任務抓取,上傳注冊中心,業務可依賴該元件進行Task編寫。
Job、Task、Plan的關系
Task是業務執行的基本單元,執行器對外暴露的一個HTTP調用接口。若幹個Task構成一個Job,而Plan是由若幹個順序執行的Job構成。
為什麼這裡需要一個Plan?有的時候兩個任務不光有順序關系(就是A任務執行完之後再執行B任務),還需要滿足一定的時間要求,比如上午10點執行任務A,下午2點執行任務B,而且必須保證上午10點任務A按時執行完成。
打個比方,今晚8點有一場足球比賽的直播,如果晚上8點我還不能到家,那我就沒辦法看直播,而如果今天我下班早,下午6點多就到家,也必須等到8點才能開始看球賽,這就是Plan計劃的來源。
2.3 組成

SIA-TASK任務排程平台有以下幾個部分組成:
- 任務執行器,就是你的業務代碼在哪裡,這是屬于項目組的。
- 任務注冊中心,我們用的是ZooKeeper。
- 任務編排中心
- 持久存儲,我們用的是MySQL。
- 任務排程中心
2.4 運作
接下來詳細介紹SIA-TASK的運作邏輯。
首先,通過注解抓取任務執行器中的任務上報到任務注冊中心。任務執行器在啟動的時候,會有一個叫online Task的注解,隻要把這個注解放到control代碼的方法上,就會自動把HTTP接口抓取出來,然後上報到任務注冊中心,這裡我們用的是ZooKeeper。
任務編排中心從任務注冊中心擷取資料進行編排儲存入持久化存儲。也就是說,相當于在執行器裡,把業務調用HTTP接口請求的URL位址、端口等執行個體抓取出來上傳到ZooKeeper裡,ZooKeeper就拿到了一個個的任務,ZooKeeper會把任務本身的資訊抓取出來放到MySQL裡。
這裡要差別一下什麼是任務,什麼是任務執行個體。任務執行個體和任務的關系,有點像類和對象的關系,就是一份業務邏輯代碼可能部署在多個節點上,也就是說這些節點的業務邏輯代碼是一模一樣的,在運作階段抓取的時候會把每個節點上業務邏輯代碼都抓取上來,針對這個業務它就是一個任務,但是每一個端口、每個IP位址對應的可能就是一個任務執行個體。比如高可用熱備時,我們會把任務本身的資訊經過處理之後儲存到持久存儲裡,而執行個體本身的資訊隻會停留在ZooKeeper裡。
任務配置中心可以根據ZooKeeper裡的資訊和MySQL裡的資訊進行配置,就是根據抓取的任務,給這些Task加時鐘、政策,然後編排出Job和Plan,并把現在的這些資訊儲存到MySQL裡。
任務排程中心從持久化存儲擷取排程資訊,知道編排的Job、Plan、時鐘、政策等邏輯,任務排程中心按照排程邏輯通路任務執行器,對這些從執行器上抓取來的Task進行排程。
這就是SIA-TASK的運作邏輯,同時我們會把排程日志存到Kafka裡。
2.5 特性
1)基于注解自動抓取任務
在暴露成HTTP服務的方法上加入@OnlineTask注解,@OnlineTask會自動抓取方法所在的IP位址、端口、請求路徑、請求方法、請求參數格式等資訊上傳到任務注冊中心(zookeeper),并同步把任務資訊寫入持久化存儲中。
2)基于注解無侵入多線程控制
單一任務執行個體必須保持單線程運作,任務排程架構自動攔截@OnlineTask注解進行單線程運作控制,保持在一個任務運作時不會被再次排程。而且整個控制過程對開發者完全無感覺。
就是在一個任務執行個體上,要保證任務在運作的時候是單線程狀态。其實這是由使用者自己控制的,如果需要是單線程的,這裡可以加以控制;如果需要是多線程的,可以不加控制。這個控制并不需要另加代碼,隻需要在注解上去處理。
3)高度靈活任務編排模式
SIA-TASK的設計思想是以任務為原子,把多個任務按照執行的關系組合起來形成一個作業(Job)。同時運作時分為任務排程中心和任務編排中心,使得作業的排程和作業的編排分隔開來,互不影響。在我們需要調整作業的流程時,隻需要在編排中心進行處理即可。同時編排中心支援任務按照串行、并行、分支等方式組織關系。在相同任務不同任務執行個體時,也支援多種排程方式進行處理,而且整個的處理編排都是在頁面上完成的,這個功能非常好用,這也是SIA-TASK平台的一個亮點。
4)排程器自适應任務配置設定
任務執行過程中出現失敗、異常時,可以根據任務定制的政策進行多點重新喚醒任務,保證任務的不間斷執行。我們設定了很多政策,比如某個Task出現問題了怎麼辦?是再喚醒一次?還是不管了?還是人工幹預發警報?我們定制了很多政策去處理這些問題。
2.6 關鍵點
了解了平台特性,我們來梳理SIA-TASK的技術關鍵點。
- 任務流。實作任務與任務之間可配置的流向關系,形成有向無環圖(DAG)。 任務流可由定時時間(Cron 表達式)或外部請求(提供 API 位址) 開始,根據 DAG 邏輯執行。
- 中繼資料管理。微服務中各個任務中繼資料的管理同步資料抓取、錄入。
- 智能運維。可視化的任務實時監控,所有監控都是有頁面可以看到的;實時預警機制,出現問題的時候,會發送郵件或短信給相關人員告警;半智能化的自主修複,嗅探重試,不需要人工幹預。
- 資源隔離。程序間的資源隔離;程序内的資源隔離,提高系統吞吐,提供穩定性。時鐘用的是Core Schedule,一個排程中心對一個項目組用一個Core Schedule,每個項目組在同一個排程的時候,同一個排程器上都是隔離的,一個項目組出問題,不會影響到其他的項目組,這就相當于代表了隔離性負載均衡。
- 負載均衡。排程中心排程任務的時候,任務的執行周期時間不一樣,可能有的任務需要的時間長一點,有的任務需要的時間短一點,排程器的資源也不太一樣,有的CPU高一點,有的CPU低一點,那如何保證排程負載均衡?如何保證資源隔離的負載均衡?我們會根據這種任務排程的曆史值(任務耗時)以及機器本身性能的值進行考量,使每一個任務排程中心擁有的排程數量差不多、消耗也差不多。這是一種新的負載,而不是簡單的流量負載。
三、SIA-TASK組成子產品
3.1 首頁
任務排程管理首頁主要包括三部分:排程器資訊、排程次數、對接項目詳情。
- 排程器資訊:排程中心排程器的數量。
- 排程次數:排程中心排程Job的曆史累計總數。
- 對接項目詳情:排程中心對接的項目組總數,Job總數。
目前SIA-Task平台上已經接入了51個項目,上面跑的Job數有600多個,今年上線的版本,Job已經跑了3000多萬次。
排程器上有幾個值需要了解一下,每台排程器都有三個名額。
- Job上限值:所能負載的Job動态門檻值;
- Job運作數量:該排程器目前運作的Job數量;
- Job預警值:當排程器運作的Job數超過預警值時,會發郵件通知管理者。
3.2 排程器管理
關于排程器有幾個 資訊需要了解,如圖所示,點選某個排程器(柱狀圖),會顯示該排程器所搶占的Job詳情清單:
- JobKey:所配置的Job名稱,每個Job都有自己的名字。
- 類型:配置Job的定時任務類型,分為Cron與fixRate兩類。
- Job類型值:如果是Cron表達式,6位時間戳怎麼寫;如果是fixRate,那就是需要間隔多少時間。
- 預警郵箱:該Job配置的預警郵箱。
- 描述資訊:描述該Job的功能資訊,便于管理者能夠迅速發現某台排程器所搶占的Job詳情。
排程器包括工作排程器、下線排程器、離線排程器、白名單。
- 工作排程器:這類排程器具有搶占和排程Job的能力。對某排程器進行下線操作,它會立即失去搶占Job的能力,已經搶占的Job執行完畢後會自動釋放,進而被其他排程器搶占,排程器下線後會進入下線排程器清單中;工作排程器清單提供下線以及批量下線的功能。簡單來說,工作排程器就是正在工作中的排程器。
- 下線排程器:這類排程器程序仍然存活,但失去了搶占Job與參與排程的能力。對這類排程器執行上線操作,會進入工作排程器清單,且開始具有搶占和排程Job的能力;下線排程器清單提供上線及批量上線的功能。就是說,下線排程器依然活着,隻是不再參與搶占Job,之前已經有的Job還是會繼續執行完成,如果點選上線就重新具備搶占Job的能力,變成工作排程器。
- 離線排程器:這類排程器程序不再存活,當下線排程器程序死亡後,會自動進入離線排程器清單,這類排程器程序重新啟動後,會自動進入下線排程器清單;離線排程器清單也提供删除及批量删除的功能。離線排程器一般都是出現問題了,可能是程序挂掉了,也可能是網絡故障了。
- 白名單:将某個IP加入白名單之後,它具有調用所有執行器執行個體的權限;白名單清單提供批量删除的功能,删除該IP後自動失去該權限。
3.3 排程監控
上圖所示是SIA-TASK的排程監控頁面,分着的一塊一塊區域屬于不同項目組。目前SIA-Task接入了51個項目,準備中的有500多個,正在運作的有25個。
有的Job執行非常快,幾秒鐘就執行完了,有的Job執行非常慢,需要很長的時間,我們在狀态抓取的時候,隻能抓取到時間長的Job,這些被抓取的Job顯示為正在運作,而時間短的捕捉不到,但它們都處于執行狀态,這些沒有被抓取到的Job就顯示為準備中。
可能有的Job這段時間不需要運作,可以手動停止,剩下的就是異常停止的Job,需要發送郵件告警。
我們也提供了檢索的能力,可以接受不同項目組登入查詢自己的項目運作狀态。
3.4 Task管理
Task管理界面中,Task按項目組分組顯示,主要提供Task的配置、修改與删除等功能。Task包含兩部分:一部分Task使用了sia-Task-hunter元件,通過标準注解實作Task的自動抓取,這類Task不允許修改;另外一部分Task是由使用者手動添加的,我知道通路的URL和HTTP位址,手動添加進來,這部分Task支援跨平台的抓取,而且可以修改和删除。
一個Task管理包含以下幾個部分内容:項目名稱、應用名稱、任務名稱、機器位址、描述、以及檢視/修改/連通性測試等操作。同一個Task名稱,不同的機器位址,代表一個任務和不同的任務執行個體。
3.5 Job管理
前面介紹了一個Job由若幹個Task組成,圖中每一個不同的列代表項目名稱,點選下拉清單可以顯示所有的項目,可以進行過濾、添加、狀态檢視等操作。
其中狀态操作可以手工執行,可以停止或激活Job,Job配置好之後屬于未激活的狀态,需要激活一下。還可以修改Job裡的資訊,配置Job等。
如何添加Job?假如我要添加一個Cron表達式類型的Job,需要添加哪些内容呢?
因為Job是Cron表達式類型的,首先我需要輸入六位表達式内容,還要添加一個預警郵箱,再描述這個Job,每個Job都有一個key,最後還需要添加Job_key。這樣一個新的Job就添加好了。
回過頭來看,添加Job需要配置Task資訊,這是一個比較複雜的過程。一個Job由若幹個Task組成,我們可以用拖拉拽的方式根據Task之間的關系确定形成組成Job的所有Task的順序關系。還可以以不同顔色代表不同項目進行區分,當然隻有管理者才有權限看到所有項目,各個項目的負責人隻能看到自己所屬項目的狀态。
上傳Task的時候會帶一些參數,是以還涉及到參數的處理,比如參數類型、參數值、過期時間等。重點聊聊過期時間。
通過HTTP方式調用會遇到一個問題:到底Task什麼時間會執行完成。為解決這個問題,就需要設一個Task的過期時間,隻要過期時間一到,就會轉入其他政策,比如放棄或人工處理等。因為作為異步調用,不可能無休止地等待用戶端傳回結果。
當然也可能存在一種情況:我得到的結果是逾時了,實際上任務是在正确執行,而且再過一段時間給我傳回結果了。我們曾經設計了一種隊列補償機制來處理這個問題,但是好像意義不大。當然,這隻是一種可能,平台上線至今沒有出現過。
目前平台的Task_選取執行個體政策包括兩種:
- 随機,從可選的清單中,随機選擇執行個體,即IP+端口;
-
固定IP,指定執行個體,随後需要從可選清單中人工指定執行個體。
平台支援四種Task_調用失敗政策:
- STOP,停止政策,調用失敗則整個Job停止,不再執行後續Task;
- IGNORE,忽略政策,調用失敗則跳過該Task,繼續執行後續Task;
- TRANSFER,轉移政策,選取該Task的其他執行個體執行,如果依然失敗,則使用停止政策;
- MULTI_CALLS_TRANSFER,多次調用再轉移政策,重複調用該Task多次,如果依然失敗,則使用轉移政策。
3.6 排程日志
日志管理提供了Job的運作日志相關資訊,按項目組分組顯示,一條Job日志的關鍵元素包含:
- 執行狀态:表示該Job執行結果;
- 執行時間:表示排程器排程Job的時間;
- 執行完成時間:表示Job執行完成的時間;
- 排程資訊:表示執行Job的排程器執行個體;
- 執行資訊:Job執行的具體資訊,并且已實作Job與所引用的Task的執行日志資訊的關聯,日志預設儲存七天。
四、開源
SIA-TASK作為SIA團隊的一個重要産品,在公司接入了數十個項目,運作着數百個Job,經受住了穩定性的考驗。
SIA-TASK微服務排程平台于5月已經開源,開源位址:
https://github.com/siaorg/sia-Task,感興趣的同學可以登入檢視詳細介紹。
分享者:梁鑫
來源:宜信技術學院