簡介
作為阿裡在APM和IOT領域的重要布局,時序資料庫承載着阿裡對于實體網和未來應用監控市場的未來和排頭兵,作為業内排名第一的時序資料庫InfluxDB,其在國内和國際都擁有了大量的使用者,阿裡适逢其時,重磅推出了阿裡雲 InfluxDB®。
限于篇幅,本文僅就InfluxDB的其中一個子產品:snapshot,對其機制和記憶體使用的優化進行分析。
為什麼要做snapshot
InfluxDB采用的是TSM引擎,TSM 存儲引擎主要由幾個部分組成: cache、wal、tsm file、compactor。
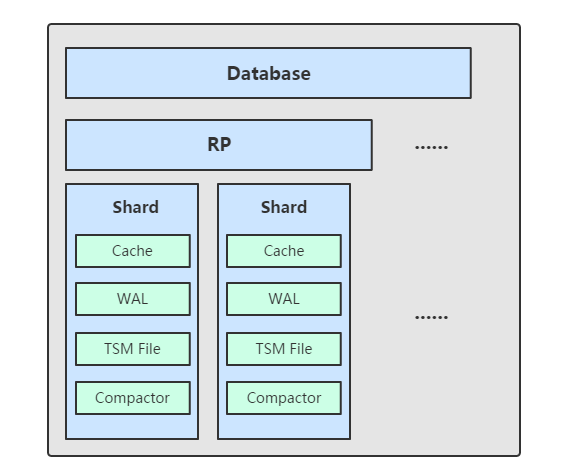
TSM存儲引擎,其核心思想類似于LSM Tree,它會将最近的資料緩存在磁盤中,在達到預設的門檻值之後就會觸發snapshot,也就是我們常說的快照刷盤。
記憶體的作用是為了緩存,加速查詢。snapshot主要是解決資料持久化落盤問題。
Snapshot的工作機制
由于snapshot是将cache中的資料刷到磁盤,那麼首先,我們來看一下Cache的内部結構。
Cache的内部結構

如上圖所示,每一個cache内部劃分成了16個partition。每1個partition内部包含一個map,所有的map其key為SeriesKey,value為entry。
// Value represents a TSM-encoded value.
type Value interface {
// UnixNano returns the timestamp of the value in nanoseconds since unix epoch.
UnixNano() int64
// Value returns the underlying value.
Value() interface{}
// Size returns the number of bytes necessary to represent the value and its timestamp.
Size() int
// String returns the string representation of the value and its timestamp.
String() string
// internalOnly is unexported to ensure implementations of Value
// can only originate in this package.
internalOnly()
}
// Values represents a slice of values.
type Values []Value
// entry is a set of values and some metadata.
type entry struct {
mu sync.RWMutex
values Values // All stored values.
vtype byte
} entry是一個Value類型的數組,Value本身是一個接口,按照值類型的不同分為:FloatValue、StringValue、BooleanValue、IntegerValue、FloatValue、StringValue。
以FloatValue為例,每一種類型的Value包含了一個int類型的時間戳和具體的值value。
type FloatValue struct {
unixnano int64
value float64
} Snapshot的流程
從代碼層面上來講,從總體的概要流程如下:
下面讓我們來逐個分析下:
Snapshot的入口
if e.enableCompactionsOnOpen {
e.SetCompactionsEnabled(true)
} Snapshot的機制
// compactCache continually checks if the WAL cache should be written to disk.
func (e *Engine) compactCache() {
t := time.NewTicker(time.Second)
defer t.Stop()
for {
e.mu.RLock()
quit := e.snapDone
e.mu.RUnlock()
select {
case <-quit:
tsdb.UpdateCacheSize(e.id, 0, e.logger)
return
case <-t.C:
e.Cache.UpdateAge()
tsdb.UpdateCacheSize(e.id, e.Cache.Size(), e.logger)
if e.ShouldCompactCache(time.Now()) {
start := time.Now()
e.traceLogger.Info("Compacting cache", zap.String("path", e.path))
err := e.WriteSnapshot()
if err != nil && err != errCompactionsDisabled {
e.logger.Info("Error writing snapshot", zap.Error(err))
atomic.AddInt64(&e.stats.CacheCompactionErrors, 1)
} else {
atomic.AddInt64(&e.stats.CacheCompactions, 1)
}
atomic.AddInt64(&e.stats.CacheCompactionDuration, time.Since(start).Nanoseconds())
}
}
}
} 每隔1秒鐘檢查一次,是否達到snapshot的條件。
snapshot的條件有兩個:
是否達到配置的門檻值。(預設情況下是25M)
離上次snapshot的間隔是否超越:cache-snapshot-write-cold-duration的配置。(預設情況下是10min)
Snapshot的具體實作
那麼,這裡涉及兩個問題:
1、落盤的檔案格式如何?
2、snapshot刷盤的過程本身是如何進行的?
我們先看落盤的檔案格式:
/>
TSM檔案包括了三個部分:Series Data Section、Series Index Section、 Footer。
1、Series Data Section生成:
Series Data Section有若幹個Series Data Block組成。
其中對于Series Data Block,這個是在記憶體中完成組裝的,具體是有cacheKeyIterator.encode函數完成,代碼如下:
func (c *cacheKeyIterator) encode() {
concurrency := runtime.GOMAXPROCS(0)
n := len(c.ready)
// Divide the keyset across each CPU
chunkSize := 1
idx := uint64(0)
for i := 0; i < concurrency; i++ {
// Run one goroutine per CPU and encode a section of the key space concurrently
go func() {
tenc := getTimeEncoder(tsdb.DefaultMaxPointsPerBlock)
fenc := getFloatEncoder(tsdb.DefaultMaxPointsPerBlock)
benc := getBooleanEncoder(tsdb.DefaultMaxPointsPerBlock)
uenc := getUnsignedEncoder(tsdb.DefaultMaxPointsPerBlock)
senc := getStringEncoder(tsdb.DefaultMaxPointsPerBlock)
ienc := getIntegerEncoder(tsdb.DefaultMaxPointsPerBlock)
defer putTimeEncoder(tenc)
defer putFloatEncoder(fenc)
defer putBooleanEncoder(benc)
defer putUnsignedEncoder(uenc)
defer putStringEncoder(senc)
defer putIntegerEncoder(ienc)
for {
i := int(atomic.AddUint64(&idx, uint64(chunkSize))) - chunkSize
if i >= n {
break
}
key := c.order[i]
values := c.cache.values(key)
for len(values) > 0 {
end := len(values)
if end > c.size {
end = c.size
}
minTime, maxTime := values[0].UnixNano(), values[end-1].UnixNano()
var b []byte
var err error
switch values[0].(type) {
case FloatValue:
b, err = encodeFloatBlockUsing(nil, values[:end], tenc, fenc)
case IntegerValue:
b, err = encodeIntegerBlockUsing(nil, values[:end], tenc, ienc)
case UnsignedValue:
b, err = encodeUnsignedBlockUsing(nil, values[:end], tenc, uenc)
case BooleanValue:
b, err = encodeBooleanBlockUsing(nil, values[:end], tenc, benc)
case StringValue:
b, err = encodeStringBlockUsing(nil, values[:end], tenc, senc)
default:
b, err = Values(values[:end]).Encode(nil)
}
values = values[end:]
c.blocks[i] = append(c.blocks[i], cacheBlock{
k: key,
minTime: minTime,
maxTime: maxTime,
b: b,
err: err,
})
if err != nil {
c.err = err
}
}
// Notify this key is fully encoded
c.ready[i] <- struct{}{}
}
}()
}
} 其中針對幾個不同的資料類型分别通過不同Encoder來進行組裝,最後是形成了一個cacheBlock的二維數組,并儲存在iter當中。
接下來的問題就是如何将這些二維數組刷盤。
2、依次刷盤
前面我們已知iter中保留有這些cacheBlock,我們隻需要周遊疊代器就可以将這些資料刷盤。但還有一個問題,Series Index Section如何生成?
因為Series Index Section最終由IndexEntry構成,而IndexEntry中minTime和maxTime、Size都可以由cacheBlock的資料得到,關鍵是Offset。
其實Offset的計算是随着疊代的過程,不斷地往前走,就像在一個Buffer中,填滿了一個Series Data Block,就會更新一次Offset。
關鍵的代碼如下:
n, err := t.w.Write(block) // Write的過程中,會更新t.n,也就是offset
if err != nil {
return err
}
n += len(checksum)
// Record this block in index
t.index.Add(key, blockType, minTime, maxTime, t.n, uint32(n)) //t.n 就是offset 總結以上所述,大體的過程是,encode生層Series Data Block, 在疊代過程中,生成了Series Index Section,最終,将Series Index Section Append到Series Data Block 就生成了TSM檔案。
那麼問題來了Series Index Section的儲存時需要空間的,如果是Series Index Section占用的記憶體過大,則可能會是以加大了程式OOME的風險。
snapshot記憶體使用的優化
如果有n個cache,同時做snapshot。 則耗費的記憶體為: n IndexSize。
例如:5db 4 retention, IndexSize = 50m。 則節省:5 4 50 = 1G的記憶體使用量。
是以,我們可以想到的一個優化點是:在snapshot過程當中利用檔案來做Series Index Section的暫存區,進而節省這一部分記憶體。
驗證
當我們利用磁盤來做Index的緩沖區時,系統在snapshot的過程中,會生成1個臨時的索引檔案,如下圖所示。
而不用磁盤來做Index緩沖區的時候,則不會生成這個檔案,如下圖所示。
經過我們的長時間的穩定性測試,證明,在利用磁盤來做Index的緩沖區時,能有效降低系統大壓力下的OOME機率。
商業化
阿裡雲InfluxDB®現已正式商業化,歡迎通路購買頁面(
https://common-buy.aliyun.com/?commodityCode=hitsdb_influxdb_pre#/buy)與文檔(
https://help.aliyun.com/document_detail/113093.html?spm=a2c4e.11153940.0.0.57b04a02biWzGa)。