業務背景
對于RDS&POLARDB FOR MYSQL 有些使用者場景會遇到,當一張的資料達到幾千萬時,你查詢一次所花的時間會變多。
這時候會采取水準分表的政策,水準拆分是将同一個表的資料進行分塊儲存到不同的資料庫中,這些資料庫中的表結構完全相同。
本文主要介紹如何把這些水準分表的表歸檔到X-Pack Spark數倉,做統一的大資料計算。X-Pack Spark服務通過外部計算資源的方式,為Redis、Cassandra、MongoDB、HBase、RDS存儲服務提供複雜分析、流式處理及入庫、機器學習的能力,進而更好的解決使用者資料處理相關場景問題。
具體産品見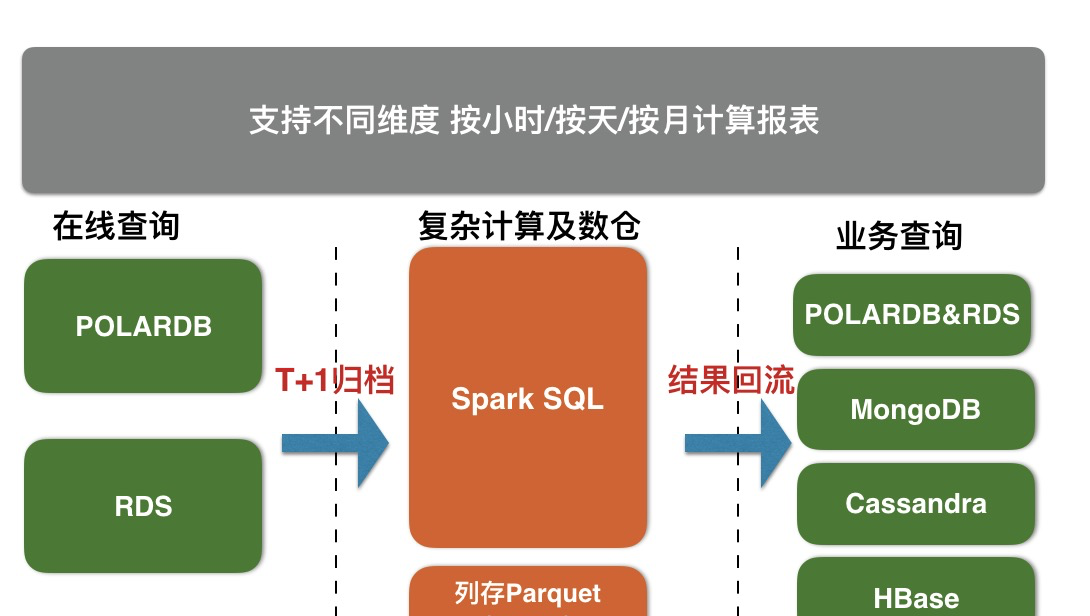
RDS& POLARDB分表歸檔到X-Pack Spark步驟
一鍵關聯POLARDB到Spark叢集
一鍵關聯主要是做好spark通路RDS& POLARDB的準備工作。

POLARDB表存儲
在database ‘test1’中每5分鐘生成一張表,這裡假設為表 'test1'、'test2'、'test2'、... 。
具體的建表語句如下:
CREATE TABLE `test1` ( `a` int(11) NOT NULL,
`b` time DEFAULT NULL,
`c` double DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 歸檔到Spark的調試
x-pack spark提供互動式查詢模式支援直接在控制台送出sql、python腳本、scala code來調試,
幫助文檔。
1、首先建立一個互動式查詢的session,在其中添加mysql-connector的jar包,
可參考wget https://spark-home.oss-cn-shanghai.aliyuncs.com/spark_connectors/mysql-connector-java-5.1.34.jar 2、建立互動式查詢
以pyspark為例,下面是具體歸檔demo的代碼:
spark.sql("drop table sparktest").show()
# 建立一張spark表,三級分區,分别是天、小時、分鐘,最後一級分鐘用來存儲具體的5分鐘的一張polardb表達的資料。字段和polardb裡面的類型一緻
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb裡面建立了databse test1,具有三張表test1 ,test2,test3,這裡周遊這三張表,每個表存儲spark的一個5min的分區
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#構造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表關聯polardb對應的表
externalPolarDBTableNow = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://pc-xxx.mysql.polardb.rds.aliyuncs.com:3306") \
.option("dbtable", dbtable) \
.option("user", "name") \
.option("password", "xxx*") \
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表資料要寫入的spark表的分區資訊
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#執行導資料sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除臨時的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#檢視下分區以及統計下資料,主要用來做測試驗證,實際運作過程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show() 歸檔作業上生産
互動式查詢定位為臨時查詢及調試,生産的作業還是建議使用spark作業的方式運作,使用
文檔參考。這裡以
pyspark作業為例:
/polardb/polardbArchiving.py 内容如下:
# -*- coding: UTF-8 -*-
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("PolardbArchiving") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("drop table sparktest").show()
# 建立一張spark表,三級分區,分别是天、小時、分鐘,最後一級分鐘用來存儲具體的5分鐘的一張polardb表達的資料。字段和polardb裡面的類型一緻
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb裡面建立了databse test1,具有三張表test1 ,test2,test3,這裡周遊這三張表,每個表存儲spark的一個5min的分區
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#構造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表關聯polardb對應的表
externalPolarDBTableNow = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://pc-.mysql.polardb.rds.aliyuncs.com:3306") \
.option("dbtable", dbtable) \
.option("user", "ma,e") \
.option("password", "xxx*") \
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表資料要寫入的spark表的分區資訊
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#執行導資料sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除臨時的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#檢視下分區以及統計下資料,主要用來做測試驗證,實際運作過程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show()
spark.stop()
阿裡雲NoSQL資料庫其他動态
阿裡雲Cassandra資料庫正式公測,提供免費試用:
https://www.aliyun.com/product/cds