Nebula Graph 是一個高性能的分布式開源圖資料庫,本文為大家介紹 Nebula Graph 的整體架構。
Meta Service
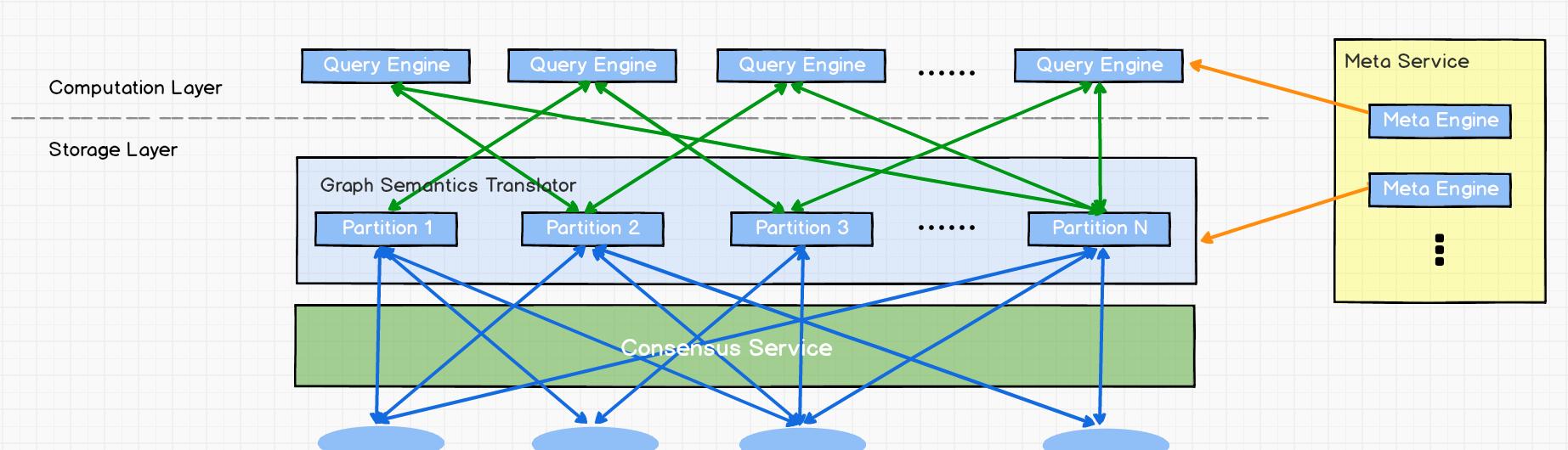
上圖為 Nebula Graph 的架構圖,其右側為 Meta Service 叢集,它采用 leader / follower 架構。Leader 由叢集中所有的 Meta Service 節點選出,然後對外提供服務。Followers 處于待命狀态并從 leader 複制更新的資料。一旦 leader 節點 down 掉,會再選舉其中一個 follower 成為新的 leader。
Meta Service 不僅負責存儲和提供圖資料的 meta 資訊,如 schema、partition 資訊等,還同時負責指揮資料遷移及 leader 的變更等運維操作。
存儲計算分離
在架構圖中 Meta Service 的左側,為 Nebula Graph 的主要服務,Nebula 采用存儲與計算分離的架構,虛線以上為計算,以下為存儲。
存儲計算分離有諸多優勢,最直接的優勢就是,計算層和存儲層可以根據各自的情況彈性擴容、縮容。
存儲計算分離還帶來的另一個優勢:使水準擴充成為可能。
此外,存儲計算分離使得 Storage Service 可以為多種類型的個計算層或者計算引擎提供服務。目前 Query Service 是一個高優先級的計算層,而各種疊代計算架構會是另外一個計算層。
無狀态計算層
現在我們來看下計算層,每個計算節點都運作着一個無狀态的查詢計算引擎,而節點彼此間無任何通信關系。計算節點僅從 Meta Service 讀取 meta 資訊,以及和 Storage Service 進行互動。這樣設計使得計算層叢集更容易使用 K8s 管理或部署在雲上。
計算層的負載均衡有兩種形式,最常見的方式是在計算層上加一個負載均衡(balance),第二種方法是将計算層所有節點的 IP 位址配置在用戶端中,這樣用戶端可以随機選取計算節點進行連接配接。
每個查詢計算引擎都能接收用戶端的請求,解析查詢語句,生成抽象文法樹(AST)并将 AST 傳遞給執行計劃器和優化器,最後再交由執行器執行。
Shared-nothing 分布式存儲層
Storage Service 采用 shared-nothing 的分布式架構設計,每個存儲節點都有多個本地 KV 存儲執行個體作為實體存儲。Nebula 采用多數派協定 Raft 來保證這些 KV 存儲之間的一緻性(由于 Raft 比 Paxo 更簡潔,我們選用了 Raft )。在 KVStore 之上是圖語義層,用于将圖操作轉換為下層 KV 操作。
圖資料(點和邊)是通過 Hash 的方式存儲在不同 Partition 中。這裡用的 Hash 函數實作很直接,即 vertex_id 取餘 Partition 數。在 Nebula Graph 中,Partition 表示一個虛拟的資料集,這些 Partition 分布在所有的存儲節點,分布資訊存儲在 Meta Service 中(是以所有的存儲節點和計算節點都能擷取到這個分布資訊)。
附錄
Nebula Graph GitHub 位址:
https://github.com/vesoft-inc/nebula,加入 Nebula Graph 交流群,請聯系 Nebula Graph 官方小助手微信号:NebulaGraphbot
Nebula Graph:一個開源的分布式圖資料庫。
GitHub:
官方部落格: https://nebula-graph.io/cn/posts/
微網誌: https://weibo.com/nebulagraph
![更改LYNC SIP位址[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)