前言
Cassandra是基于LSM架構的分布式資料庫。LSM中有一個很重要的過程,就是壓縮(Compaction)。預設的壓縮政策是SizeTieredCompactionStrategy,今天主要說一下另一種壓縮政策LeveledCompactionStrategy。
LeveledCompactionStrategy
LeveledCompactionStrategy被用在讀密集的場景,讀操作的延遲相對容易估算(最壞情況讀的檔案數量可以确定),舊資料可以更快被淘汰。缺點是會有更多的磁盤IO消耗,可能會影響到讀寫操作延遲。
這個壓縮算法主要是将資料分級(L0,L1,L2……)。最開始資料在記憶體(memtable)裡,然後被flush到磁盤上,也就是到了L0這級。L0的sstable會和L1的合并成更大的sstable。
增加SSTable:
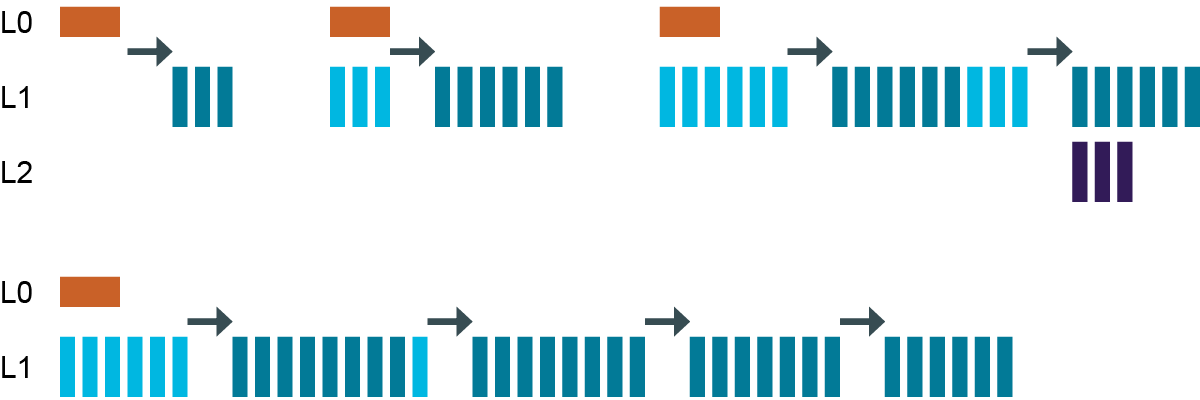
大于L1的層級,sstable都被合并成大于或等于
sstable_size_in_mb
(預設:160MB)。超過L0的層級,建立的sstable大小都大緻相同。每個層級之間資料量是10倍的關系,即L2的資料量是L1的10倍。我們假設L1可以容納
10*160MB
,那麼L2可以容納
100*160MB
。如果在L1做壓縮,結果大于10,會被移動到L2.
非常多次寫入後:

LCS compaction會保證從L1開始沒有重複資料。是以對于讀操作來說,隻要檢索1個或者2個sstable就能查到資料(L0 + LN)。事實上,90%的讀操作都隻需要讀取1個sstable。由于L0是不壓縮的,如果大量讀請求集中在L0,任然可能導緻大量讀IO消耗。
LCS compaction發生的會更頻繁,會消耗更多IO。如果是寫密集型的,并不适合,因為IO開銷可能大于讀的收益。
更多壓縮政策選擇可以參考:
https://docs.datastax.com/en/dse/6.7/dse-dev/datastax_enterprise/config/configChooseCompactStrategy.html寫在最後
為了營造一個開放的Cassandra技術交流環境,社群建立了微信公衆号和釘釘群。為廣大使用者提供專業的技術分享及問答,定期開展專家技術直播,歡迎大家加入。另雲Cassandra免費火爆公測中,歡迎試用:
https://www.aliyun.com/product/cds