近日,在上海交通大學上海進階金融學院主辦的2019國際金融科技會議上,氪信科技創始人兼CEO朱明傑博士結合企業自身一系列實踐經驗,從技術角度對AI金融痛點和難點進行了系統性梳理。
他表示,強金融資料以外的“另類資料”已經遠遠超出評分卡的處理範圍,主要包括動态時序類、文本類、網絡類三種,“總的思路是在金融場景下,将專家的經驗變成機器能夠了解的資料,不斷訓練機器,提高機器的學習能力,最後讓機器處理人力無法解決的問題。”
以下為演講全文,雷鋒網(公衆号:雷鋒網)AI金融評論進行了不改變原意的精編。
今天大家講金融大資料,主要都在說強金融資料之外的“另類資料”。我們這些做計算機工作的,能感受到風控專家最痛苦的地方,是他們希望按照以前定規則的方式,把這些資料編碼到以往的評分體系裡。比如以前你可以根據工資多少、納稅多少做評分卡,是以對那些金融概念之外的資料,比如一個人一天和多少人打電話,他的網際網路行為、社交狀況等,風控專家一開始也想根據傳統經驗把這些資料變成特征變量,結果發現它們遠遠超出了評分卡可處理的範圍。
以前我們在網際網路裡面處理的就是這些資料,我們訓練機器在一堆照片裡識别誰是章子怡,不是告訴它誰長得美長得白就是章子怡,不是這樣的。但是我們依然能做出識别率非常高的模型,這裡面沒有什麼神奇的單項技術,它是一系列技術。同理,我們今天用AI技術去處理金融領域的另類資料,也不是圍繞一個非常fancy的技術,不是首先要遷就人的了解範疇,我們是為了達到實際效果才出發的。
三種“另類資料”的處理方式
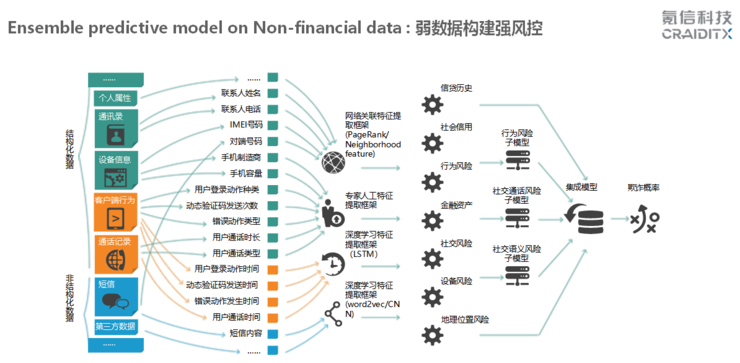
氪信另類資料建構強風控體系工作總結圖
一般來說,難以做成評分卡的另類資料主要包括動态時序類、文本類、網絡類三種,這些讓風控專家束手無策的資料問題,機器都能解決。總的思路是在金融場景下,将專家的經驗變成機器能夠了解的資料,不斷訓練機器,提高機器的學習能力,最後讓機器處理人力無法解決的問題。
時序資料是基于時間的一系列資料,如果風控人員要用評分卡把這類資料歸類成一個一個特征變量會極其痛苦,但是機器不同,它可以存儲和處理大量的時序資料,是一種關注總體而非個别節點的方式。

這是我們跟京東金融的一個合作成果,相關論文發表在2018年的KDD上,主要是處理發生在APP上面的序列化行為,比如個人注冊了一個頁面,輸入了一些資訊,點選的速度,從左邊滑還是右邊滑……這樣一些資料,然後從中找出有欺詐嫌疑的一些人的特征,并提出了一套行為事件流時序模型架構。這套架構的提出基于一個很自然的想法:這些年大家多用深度學習,尤其是LSTM(基于深度循環網絡的特征提取架構),它特别适合處理時序型資料。是以我們就把這類序列行為編碼到我們的LSTM模型裡去。
做到這一步還不夠,我們還有一套架構是用CNN的模型對序列行為衍生特征。具體結果可以看我們在KDD 2018上面的paper。
文本類資料處理方式
在金融行業,以前大家可能對文本資料束手無策,因為你很難将一系列的對話文本轉變成數字化變量,解釋給計算機聽,最後還能輸出結果。我們能做到的是在一個限定的場景裡面,給出一個很好的結果。因為你每對它多做一個限制,你的計算複雜度就會降低很多,在有限的計算資源和技術條件下,就能得到一個足夠好的效果。
第一篇論文主要講我們建了一套QA問答體系的特征,從一段文本最後變成數值化的向量,其實是有标準做法的。但是我們發現,在一個限定的場景裡,比如說客服場景是一問一答的方式,單單用X-Encoder(基于無監督深度學習的特征提取架構)是不夠高效的,于是我們做了一套針對QA的基于X-Encoder的催收風險模型互動式特征提取架構,專門适合金融領域的一問一答。
第二篇論文是關于提取客戶标簽的,通過對話把你的context提取成标準事件。這件事的關鍵點在于,今天金融機構的客服人員,都是被訓練成機器一樣在工作,一個新人招進來以後,就用标準化的教育訓練模闆去教導他,告訴他比如客戶講了這句話以後,你要講哪些話,怎麼給客戶打标簽等等。是以我們的工作是建構一個知識庫,建立标準對話流程預測體系,讓這個新人可以更快地上手。我
第三類網絡資料,因為個人資料非常有限,尤其在金融領域,大資料風控其實需要大量的訓練樣本,但金融場景裡面的訓練樣本是非常寶貴的,比如你想獲得一個人是壞人的樣本資料,那麼至少得有一筆幾萬塊的壞賬,這個成本非常高。這跟我們以前做網際網路預測分析不一樣,使用者喜不喜歡一部電影,一個廣告,或者一個手機殼,這件事情的成本沒那麼高。
我們的做法是找到類似的人,從他的申請資料和社交關系上面去抽取知識,做聚類。當你發現了一個壞人,那麼跟他類似的那群人是壞人的機率就非常高。也就是說,當你找到有效的群體之間相似這種關系以後,是有助于對個體風險做識别的。當然僅僅個人的大資料還不夠,我們還需要借助更多的大資料,最後用內建模型把個人的風險特征和局部網絡、全局網絡上建立的風險特征結合在一起,提升風險預測效果。
模型的可解釋性:AI下一個突破點
剛才講的是幾類不同類型的另類資料處理辦法,這個過程中我們始終有個挑戰,那就是你做的模型是一個黑盒,沒有辦法解釋。我不能告訴金融機構,誰用了這種方法,效果很好,這對金融機構來講是不能接受的,你一定要告訴他為什麼。這其實也是整個AI領域最頭痛的事情,在業務場景特别明顯的地方,比如醫療領域,困難更加明顯,比如AI診斷說要切掉一條腿,為什麼?你不能說是model預測的,或者最後說model出錯了,那這個醫院肯定是會關門的。
是以模型的可解釋性是深度學習突破之後AI面臨的新挑戰,在通用模型上目前我還沒有看到特别好的解決辦法。但是在具體的金融場景裡,我們可以在某種程度上給出解釋。有兩個辦法:一個是局部的近似,用低維模型拟合高維模型,它參考了博弈論裡面的東西,最後得到最優的決策,是倒推博弈論的過程,這個我們有成型的産品,用在了我們的風險解決方案裡面;第二個是把AI模型裡最重要的幾個特征變量找出來,解釋給業務專家聽。
左邊第一個是帶有時間先後序列特征的實踐結果。名額主要就是模型區分度,KS值和AUC。按照KNN的通常做法KS值是0.142,再用一個神經網絡去做MLP,KS值達到0,167。加上這些特征以後,進一步提升到0.203,在一個典型的場景上,加上行為資料,KS值可以做到0.216,差不多提升了50%以上。
第二個是短文本資訊提取模型效果,傳統做法和利用AI模型的做法在數值表現上效果差不多,但是後者的擴充性更強,因為原來要求人非常有經驗,時時想着應對政策,有了這個架構以後就不用人費力去調參了,機器會替代部分人力工作。
第三個是對社交網絡資料的使用效果,如果隻是單純用個人的風險資料,KS值是0.3;加上基于圖的特征以後,有類似于人群的特征,很明顯提升到0.38。
右邊是加入上述三種類型資料以後的綜合表現,我們也可以看到KS值是不斷增長的。
從個體資料處理經驗遷移到群體
群體風險方面,這兩年監管對反洗錢和可疑交易監測要求很嚴格,以前國内監測個人的欺詐風險,主要是基于規則和個人上報,風險營運部門會用很多人工去找,效率很低,現在欺詐的手段層出不窮,就需要用人的規則和以前發生過的欺詐事件訓練機器去抓。原來為了抓可疑交易,假設要雇一百個人人工去看,現在是一百個風險營運的人等着看機器提供的樣本是不是對的,再回報給機器,讓機器訓練得更加準确。
這裡的關鍵是使用圖算法。在網際網路行業專門有做圖算法、圖解決方案的公司,提出解決方案來,發現一直沒有成功的。總結起來是兩個點,一定要根據行業知識來做降維;還需要一套有效的計算體系。我們的列式計算引擎能夠在15分鐘内處理百億級别資料,這在以前是很難想象的。
最下面是原始資金的交易流水。我們知道銀行的交易流水量非常大,不大得話,人工就可以解決了。交易流水形成兩個東西:
首先互相帳戶往來會建立起一個大的Graph,我們會給定以前的可疑種子結點,經過局部社群算法找到跟它關聯的可疑子社群。
比如說放進去10萬個可疑種子,找到10萬個跟它相關的社群。這10萬個社群裡一共是上億的帳戶。其中90%以上的都是好人,我們就對其餘10%的人群進行重點布控。
另外,我們基于風險專家的經驗形成風險知識圖譜,這是一般風險專家會去考慮一個交易往來的特征,從金額、模式、速度、場景方面考慮。
結合這兩個東西來做圖的深度學習預測模型。有了這個模型指導以後,由單個種子去觸發。使用ACL優化的PPR算法,加上Sweep-cut算法,實作大規模的挖掘。最後做到一件事情:通過種子的節點去找密切的社群,學到圖的結構,找到更可疑的人。
講完原理,舉個例子。比如一個大銀行的房貸系統,發現幾十個帳戶,都和叫“X琴”的人有關系,和她的資金往來非常多, X琴可能是中介,或者專門職業給人提供首付、中間過橋的,這裡面肯定不正常。如果純靠人工去找的話,很難從幾十億交易流水資料中找到這樣的東西,但是通過圖挖掘可以一目了然看到X琴的帳戶有問題。
雷鋒網雷鋒網雷鋒網