概要
随着現代硬體的記憶體越來越大,位址轉換的開銷變得不可忽視,大頁(Hugepage)方案可以有效的減輕MMU壓力,但是如何設計高效的大頁管理方案,對于開發者而言仍然屬于比較頭疼的問題;近期的研究論文Ingens通過分析核心的頁面通路模式和硬體性能計數器中>的資料,發現linux的大頁管理政策在位址轉換性能、缺頁時延及記憶體膨脹(memory bloat)等方面都存在着較大的缺陷。
今年的ASPLOS 19提出的一篇新論文《HawkEye: Efficient Fine-grained
OS Support for Huge Pages》,提出了一種新型的大頁管理方案HawkEye,HawkEye管理算法的主要思想包括:異步頁面預清零、全零頁面去重、頁通路精細化跟蹤以及通過硬體性能計數器的位址轉換開銷測量,研究資料表明,HawkEye擁有更高的性能以及更健全的功
能,在各種工作負載下的表現都比linux更加優秀。
論文背景
随着應用程式使用到的記憶體範圍越來越大,位址轉換帶來的開銷變得不可忽視,多級TLB、多級cache等技術及現代架構已經支援了多種不同尺寸的大頁,但是這更加需要OS在不同的工作負載之下,謹慎的選擇大頁的使用政策,特别是對于擁有兩層位址轉換的虛拟化場
景,MMU的開銷問題會變得格外嚴重。
盡管硬體提供了大量的支援,但是大頁在一些重要應用程式上的性能表現仍然不能讓人滿意,主要原因來自于軟體層面的大頁管理算法。linux大頁管理算法需要在位址轉換開銷、缺頁時延、記憶體膨脹、算法本身的開銷以及公平性之間做複雜的平衡,HawkEye暴露了當
前大頁管理方案的一些問題,并提出一套新的方案來解決它們。
首先簡要介紹三種具有代表性的大頁方案:Linux、FreeBSD以及Kwon等人的研究論文Ingens。
Linux
linux的透明大頁通過以下兩種方式來申請大頁:
- 當系統存在足夠的連續記憶體時,通過缺頁異常直接配置設定大頁給應用程式
- 通過khugepaged背景線程選擇性的将4k小頁合并為大頁
linux隻有在系統記憶體碎片化較高、缺頁異常很難直接配置設定到大頁時才會啟動背景線程的合并功能,啟動後khugepaged會按照FCFS(first-come-first-serve)政策選擇程序進行合并,隻有合并完一個程序後才會選擇下一程序
FreeBSD
Freebsd支援多種size的大頁,與linux不同的是,freebsd預留了一塊連續的實體記憶體區域給缺頁異常,但是隻有當一個連續2M(以2M大頁為例)中的所有4k頁均被配置設定出去後,freebsd才将其合并為大頁,并且在記憶體壓力過大時,還會将大頁中被釋放的小頁拆分出來
還給os(同時也就不能再以大頁管理),是以freebsd的方案擁有較高的記憶體使用率,但是會導緻更多的缺頁異常以及MMU開銷
Ingens
從Ingens的論文來看,Ingens的作者指出了linux及freebsd大頁管理方案中的缺陷,并且聲明Ingens可以針對這些問題做出平衡,總的來說,Ingens擁有以下特點:
- Ingens通過一種自适應的方案來平衡記憶體膨脹及位址轉換的開銷:在系統記憶體壓力較小時,盡可能的給應用程式配置設定大頁來提升性能;在系統壓力較大時,則采用比較保守的大頁合并門檻值來避免出現大量的記憶體膨脹
- 為了避免由于同步頁面清零帶來過高的缺頁時延,Ingens采用了專門的核心線程來異步完成大頁配置設定
- 為了保證程序間公平性,Ingens将連續記憶體視為一種系統資源,使用共享配置設定的原則公平的為各個程序提供配置設定服務
HawkEye
作為一種作業系統級别的新型大頁解決方案,HawkEye基于達成以下幾個目标,提出了一種簡潔且有效的算法:
- 在位址轉換開銷、記憶體膨脹、缺頁異常時延中找到最佳平衡
- 盡可能的将大頁配置設定給那些能夠得到最大性能提升的應用程式
- 在虛拟化場景下改進共享記憶體的行為機制
通過對各種典型應用進行測試(盡量挑選對大頁訴求不同的應用),HawkEye的資料表明其與現有方案相比性能得到了顯著的改善,同時增加的開銷可以忽略不計(最壞情況下每核增加3.4%的cpu開銷)
大頁的常見問題
通常在設計大頁管理方案時,會面臨到以下幾個問題之間的抉擇和平衡,而相對于已有的作業系統解決方案,HawkEye在這些問題上采取的方式會顯得更為有效
位址轉換開銷和記憶體膨脹
設計大頁管理方案最大的問題在于如何權衡位址轉換開銷和記憶體膨脹,linux采用的同步大頁配置設定政策能最大限度的減少MMU開銷,但是往往當應用程式僅使用大頁中的一小部分記憶體時,會導緻大量的記憶體膨脹;freebsd的保守做法(隻有當小頁全部使用才合并為大頁>)解決了記憶體膨脹問題,但卻是以犧牲整體性能為代價。
Ingens的方案比較折中,它提出了一個概念用于測量系統的記憶體壓力,稱之為FMFI -- Free Memory Fragmentation Index(空閑記憶體碎片指數),當FMFI < 0.5 (記憶體碎片低)時,Ingens行為類似于linux,盡可能的給應用程式配置設定大頁來提升性能,當FMFI > 0.5>(記憶體碎片高)時,Ingens轉換為比較保守的政策,隻有當90%的小頁均被配置設定時,才會将其合并為大頁,以此來緩解系統記憶體膨脹問題。
但是Ingens并不是最佳方案,因為其在記憶體碎片較低的激進模式下配置設定出去的大頁,造成的記憶體膨脹并沒有被回收回來。通過以下一個簡單的Redis key-value store測試可以證明這個問題:
在一個記憶體為48G的系統上使用Redis做下述測試:
- insert key-value 記憶體資料條目,使程序的記憶體占用(RSS)達到45G
- delete 80%的資料條目
- 等待一段時間後,再次insert資料,使記憶體占用再次達到45G
測試結果如下:
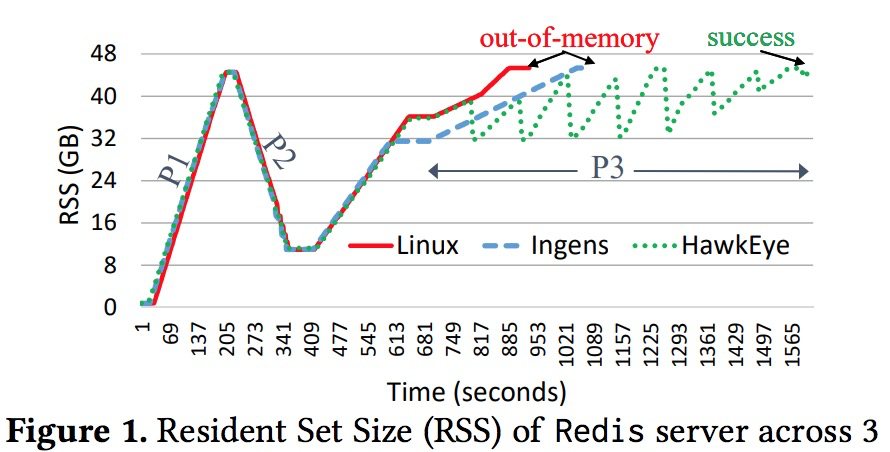
如圖所示,當執行P2階段删除操作後,程序RSS迅速降低到約11GB左右,這個時候khugepaged核心線程會将很多空閑頁面合并為大頁,當在P3階段進行配置設定時,RSS達到32G之前Ingens與linux一樣都在盡可能的配置設定新的大頁給應用程式,随後Ingens進入保守狀态避免内
存進一步膨脹,但最終Ingens與linux都觸發了系統的oom異常,此時檢查有效的資料條目可以發現,linux産生了28G的記憶體膨脹(隻有20G的有效資料),而Ingens産生了20G的記憶體膨脹(有28G的有效資料),可以發現雖然Ingens試圖減少記憶體膨脹,但是在前期造成>的記憶體浪費并不能回收。
如果将Ingens完全配置成保守模式,可以解決記憶體膨脹的問題,但是這種模式在低記憶體壓力下性能損耗比較嚴重,一個理想的政策應該如圖中的HawkEye所示,在低壓力下盡可能的滿足應用程式的高性能,而在記憶體壓力過大時又能夠從記憶體膨脹中有效的恢複回來。
缺頁時延和缺頁次數
作業系統在把頁面配置設定給應用程式時,通常要将頁面内容清零(部分場景除外),頁面清零操作的耗時在缺頁異常中占的比重非常大,特别是在使用大頁時。測試發現清零一個4k頁占整個缺頁異常時長的25%,但是清零一個2M頁需要占整個缺頁異常時長的97%!過高的
缺頁時延會導緻使用者可感覺的延遲,進而對互動式應用帶來極為糟糕的體驗。
Ingens為了解決這個問題,在缺頁異常時隻給應用配置設定4k小頁,而将合并大頁的操作全部交給背景線程khugepaged異步完成,但是這樣做會失去使用大頁的一個重要優點,即可以減少缺頁次數。
通過一個小的benchmark測試,申請100G記憶體并且在每個4k頁上寫一個位元組,然後把記憶體釋放掉,下表顯示了各種大頁方案下的資料對比:

如上表所示,支援透明大頁的linux系統(linux 2MB)相比隻使用4k頁的linux系統,缺頁次數減少了大約500倍,最終在這個測試上帶來了約4倍的性能提升,但是單次缺頁異常的平均時延也上升了約133倍(465µs vs. 3.5µs),而Ingens在該場景下與linux 4k>表現基本一緻。
可以猜想,如果在大頁缺頁時不需要進行頁面清零,那麼就可以讓缺頁異常的時延變短且缺頁次數變少,HawkEye通過實作一個異步頁面歸零線程達到了這個目的。
多程序間的大頁配置設定
由于存在記憶體碎片化,作業系統需要能在多個程序間公平的配置設定大頁。Ingens的作者把連續實體記憶體作為一種系統資源,把程序内部的大頁合并比例作為公平性名額,來評估并保證各個程序的公平性。Ingens的公平性政策有一個比較大的缺陷是如果兩個程序P1和P2擁
有相同比例的大頁百分比,但P1程序的TLB壓力遠高于P2(比如P1的通路分散在多個4k小頁中,但p2的通路集中在一個或某幾個4k小頁),此時P1更需要進行大頁合并,但Ingens會平等對待這兩個程序。
HawkEye提出的方案認為通過MMU開銷來考量整個系統的壓力更為有效,是以它認為公平算法應該嘗試去平衡各個程序的MMU開銷,讓各程序的MMU開銷保持相當。比如程序P1和P2的MMU開銷分别為30%和10%,這時應該将更多的大頁配置設定給P1,将其MMU開銷降低到10%為止>,這樣的政策能夠讓整個系統達到最優的性能。
最後,在單個程序内部,linux和Ingens目前都是采用從虛拟位址的低位址往高位址順序掃描進行大頁合并,這種方式對于熱點在高位址區間的應用并不公平,由于通常應用的熱點都分布在不同的vma區間内,是以目前的做法在實踐上很容易出現不平等的現象。
如何測量位址轉換的開銷
目前估算位址轉換開銷的常用方法是通過WSS(workingset size):WSS更大的任務通常被認為擁有更高的MMU及性能開銷,但是測試發現實際應用并不都是這樣,如下圖所示
擁有高WSS的任務(如mg.D)比低WSS任務(如cg.D)的MMU開銷小得多,這跟程序的記憶體通路模型有較大的關系。
我們并不清楚作業系統是如何測量MMU開銷的,這依賴于應用程式與底層硬體的複雜關互關系,不過根據上述實驗,我們知道這種開銷可能與程序占用的記憶體大小并不直接成比例,是以在有條件的情況下,直接使用硬體性能計數器來統計TLB的開銷更為有效,HawkEye>提出了如下算法來計算MMU overhead:
但由于部分情況下無法使用上述的性能計數器(比如在虛拟化場景,大部分hypervisor并沒有虛拟TLB相關的硬體計數器),為了應對這種狀況,HawkEye提出了兩種算法:
基于硬體性能計數器來測量MMU開銷的HawkEye-PMU算法,以及基于記憶體通路模型來估算MMU開銷的HawkEye-G算法
設計與實作
上圖顯示了HawkEye的主要設計思路,HawkEye的整體解決方案基于四個關鍵因素:
(1)使用異步頁面預清零方案來解決大頁缺頁時的時延過高問題
(2)識别并删除已配置設定大頁中未使用的重複小頁來解決記憶體膨脹問題
(3)基于對大頁區域細粒度的通路跟蹤,來選擇更優的記憶體範圍進行大頁合并,跟蹤的名額包括新近度、頻率和通路覆寫範圍(即在大頁内通路過多少小頁)
(4)基于對MMU開銷來平衡程序間的公平性
異步頁面預清零
異步頁面預清零是一種較為常見的機制,通常是通過建立一個cpu使用受限的背景線程來實作,這種方式早在2000年左右就被提出來了,但是linux的開發人員認為這種方案并不能帶來性能提升,主要基于以下兩個理由:
-
異步預清零會對cache造成很大的污染,特别是容易造成多次cache misses,因為它在兩個程序空間對連續的大片記憶體進行兩次遠距離的通路,第一次是背景線程中的預清零,然後是在應用程式中的實際通路,這種額外的cache miss會導緻系統整體性能的下降。但
是現在大部分硬體已支援non-temporal指令,預清零通過non-temporal方式進行寫入,可以跳過cache直接 寫到記憶體中,可以解決cache污染的問題
- 沒有實際的經驗或資料表明預清零可以帶來明顯的性能收益。但是如表1中的測試資料表明,盡管預清零對于4k頁的收益不夠明顯,但是對于大頁而言,清零的耗時占了缺頁異常97%的時長,而目前大頁已經在各種作業系統中都被廣泛應用,預清零的收益會得到顯>著的提升
為了實作異步預清零,HawkEye通過兩個連結清單來管理夥伴系統中的空閑頁面:zero and no-zero , 優先從zero連結清單配置設定大頁,背景線程會周期性的将no-zero連結清單中的頁面清零,清零時采用 non-temporal 方式寫入,以避免對cache造成污染;而對于page cache和寫時
拷貝的頁面,不需要進行預先清零,這類記憶體申請可以優先從no-zero連結清單中配置設定。
總之, HawkEye認為在新型硬體和目前工作負載的要求下,頁面預清零是一個值得關注的話題,他們的測試資料證明了該方案的有效性。
記憶體膨脹
一般應用的記憶體主要來自以傳統方法(如malloc)申請的全零頁,剩下的就是檔案緩存或寫時拷貝申請的頁面,而透明大頁通常也隻用于匿名頁中。HawkEye在第一次缺頁異常時優先給程序配置設定大頁,但當系統記憶體壓力過大時,會掃描每個大頁中的全零小頁,如果全>零小頁超過一定的比例,就将該大頁拆分成為小頁,并且利用寫時拷貝技術将所有的全零頁面合并為一個。部分場景下這的确會導緻缺頁異常次數變多,但這種做法對減輕記憶體膨脹的收益更為明顯。
為了從記憶體膨脹中恢複,HawkEye使用了兩個記憶體配置設定水線,當系統記憶體申請量超過某個門檻值(比如85%)時,會激活背景恢複線程,周期性的執行直到系統記憶體使用量降低到70%以下。每次執行時,恢複線程優先選擇MMU開銷最小的線程進行掃描,這個政策保證了最不
需要大頁的程序優先被處理,與HawkEye的大頁配置設定政策(MMU開銷最大的程序優先配置設定大頁)保持一緻。對于每一個小頁來說,每次掃描到非0位元組即可跳過,對于全零頁需要掃描4096位元組,這樣掃描線程的開銷就與整個系統的總記憶體無關,隻與可回收的記憶體相關,>對于超大記憶體的系統也可适用。
全零小頁合并的機制與linux核心目前的ksm機制比較類似,但是linux核心中的ksm與大頁管理目前屬于兩個獨立的系統,HawkEye借鑒了ksm中的部分技術來快速的找到全零頁面并進行高效的合并。
精細化大頁合并
目前系統的大頁合并機制都是從程序的低位址空間掃描到高位址空間,這種方式效率很低,因為程序的熱點記憶體區域不會都在低位址範圍内。
HawkEye 定義一個叫access-coverage的名額,通過定期對大頁中各小頁的頁表通路位進行掃描統計,可以判斷在一定時間範圍内其中有多少個小頁被通路過,進而選擇出hot regison進行合并,這樣可以顯著提高合并後帶來的TLB收益。
HawkEye 通過一個per程序的資料結構access_map來管理 access-coverage,access_map是一個數組,每個數組成員稱之為一個桶(每個桶内實際是一個連結清單)。拿x86的2M大頁舉例,每個大頁由512個小頁組成,根據大頁中每個小頁頁表上面的通路次數總和 0-512,>将該大頁放入對應的桶中中,通路次數為0-49的放在桶0,50-99的放在桶1,以此類推,下圖顯示了三個程序A、B、C的access_map狀況:
當某一次掃描時,某個大頁的通路範圍增加,比如從30個小頁被通路增加到55個小頁被通路,則需要将其從桶0移動到桶1(更新),此次會把它移到對應桶的連結清單頭部,反之從桶1移到到桶0(降級)時會移到桶的連結清單尾部>,而大頁合并是從連結清單頭部周遊到尾部,這樣可以確定每次合并時優先合并最近通路過的區域。可以注意到HawkEye 的方案兼顧了通路頻率和新近度,最近未通路或通路範圍較低的大頁會被移到更低級的桶中或是目前桶的連結清單尾部。
在 access-coverage 政策裡面,具有最高MMU壓力的頁面會優先被合并為大頁,這與之前讨論的公平性一緻,即優先合并TLB壓力最大的程序;access-coverage總是挑選所有程序中通路範圍最廣的那一個桶(如上圖桶9)來優先回收,如果多個程序含有相同最高等級>,則采用循環的方式保證公平,如上圖,在程序A、B、C中的合并順序為 A1,B1,C1,C2,B2,C3,C4,B3,B4,A2,C5,A3。
但是,MMU開銷可能并不一定與上述基于通路的覆寫範圍完全一緻,是以在HawkEye-PMU算法中,會優先選擇硬體計數器測量出的具有最高MMU開銷的程序,然後再按照上述各桶的順序進行大頁合并。如果有多個程序的MMU開銷相近,則采用循環的方式逐個處理。
限制與讨論
HawkEye算法目前存在以下幾個沒有解決的問題:
(1)記憶體壓力的門檻值如何標明,目前都是采用靜态的固定門檻值,如系統記憶體的85%和70%,如果記憶體壓力一直波動,那麼靜态的門檻值可能會偏保守或是激進,理想的狀态是能夠根據系統狀态,動态的調整這些門檻值
(2)第二個問題是大頁餓死,雖然HawkEye算法基于mmu開銷,但确實有可能造成部分程序沒辦法使用大頁(因為MMU壓力不夠),這個問題可以通過linux的cgroup等機制限制程序的大頁使用數來解決
(3)其它算法,部分沒有讨論過的管理算法,像khugepaged的合并/拆分機制本身的開銷,能夠将頁表項跟蹤開銷最小化的合并算法等,HawkEye在這些領域暫時沒有太深入的研究
測試資料對比
精細化大頁合并效果
上圖顯示了單個Graph500 和 XSBench應用在不同算法下的執行效果,從第一列可以看到,應用的熱點記憶體區域不是總在低位址空間,第二列和第三列顯示了大頁合并的效果,Linux和Ingens都花了接近1000s才将mmu overhead降下來,而HawkEye隻使用了約300s就有了
顯著的效果。
多程序公平性效果
同時運作三個Graph500 和三個 XSBench應用,下表顯示了整體的運作時長,在HawkEye算法下的運作時長比linux及Ingens更短,性能更高
下圖則展示了上述測試運作過程中,每個程序的大頁占用數及mmu開銷,從圖中可以明顯看出,linux的大頁占用數對各個程序很不公平,随機性較大,Ingens和HawkEye則對各個程序更為公平,而在MMU開銷上的表現HawkEye占據絕對優勢
虛拟化場景效果
下圖顯示了在虛拟化場景下,HawkEye比Linux提升了約18–90% 的性能,可以看到在部分應用(如cg.D)下,HawkEye在虛拟化場景的性能提升比祼機更明顯,原因是在處理guest TLB miss時,涉及到多層MMU開銷,這給了HawkEye的算法更多的發揮空間
測試配置
測試效果
記憶體膨脹恢複效果
下表顯示了Redis場景下的記憶體膨脹與性能之間的平衡效果,在記憶體壓力較小的時候下,HawkEye占用較大的記憶體(與linux-2M相當)以帶來更高的性能,而當記憶體壓力變大時,HawkEye能消除Redis的記憶體膨脹,降低到linux僅使用4k小頁(無記憶體膨脹)時的水準
缺頁異常加速效果
HawkEye在4k場景下對缺頁異常的加速效果并不明顯,這是因為頁清零占據缺頁的比例太小。
下表第一行顯示的是Redis的吞吐量,可以看到HawkEye在2M大頁場景下比linux-2M提升了約1.26倍。
其它行顯示的資料是執行時間,HawkEye-2M比linux-2M在SparseHash測試上提升了約1.62倍。
而虛拟化場景下spin-up運作時長與缺頁異常強相關,可以看到大頁場景下HawkEye可以比linux提升約13倍,但在4k頁場景下提升隻有1.2倍左右
異步預清零線程開銷
下表顯示了在多個測試套下異步預清零線程帶來的性能開銷,可以看到使用non-temporal指令(無cache)可以明顯的降低該開銷,在omnetpp測試下,使用nt-stores可以将overhead從27%降低到6%,而普通場景下的平均開銷都在5%以下
HawkEye-PMU與HawkEye-G對比
HawkEye-PMU基于硬體性能計數器計算MMU開銷,相比HawkEye-G的軟體估算會更精确,HawkEye-G的估算是基于頁面的通路覆寫率,但相同覆寫率的應用也會存在TLB敏感與不敏感之分,如下在一個系統中同時運作兩個任務:TLB敏感任務(如cg.D)與TLB不敏感任務(>如mg.D),可以看到HawkEye-PMU可以精确識别出MMU開銷更高的任務,而HawkEye-G基于頁面通路的估算可能會出現偏差,最壞情況下HawkEye-PMU會比HawkEye-G好36%,如何通過軟體的方式消除這兩種算法的差異需要留給未來的工作