雲原生日志資料分析上手指南
背景資訊
本指南主要涉及阿裡雲雲産品:
- 日志服務(SLS, https://www.aliyun.com/product/sls )
- 對象存儲服務(OSS, https://www.aliyun.com/product/oss
- Data Lake Analytics(DLA, https://www.aliyun.com/product/datalakeanalytics
上述三款雲産品均屬于Serverless化的雲原生服務型産品,無維護成本、高可用,簡單配置即可在雲上搭建起企業級的日志資料分析鍊路和應用。
日志作為一種特殊的資料,對處理曆史資料、診斷問題以及了解系統活動等有着非常重要的作用。對資料分析人員、開發人員或者運維人員而言,日志都是其工作過程中必不可缺的資料來源。
通常情況下,為節約成本,我們會将日志設定一定的儲存時間,隻分析該時間段内的日志,此類日志稱之為“熱”日志。這種做法,短期内可以滿足使用需求,但從長期來看,大量的曆史日志被擱置,無法發揮其價值。
對于許多企業而言,對日志分析的需求特征通常為低時效和低頻率。并且在一個企業中,為偶發性的日志分析去建構一套完整的日志分析系統,無論在經濟成本還是運維成本上都是不劃算的。如何在降低存儲成本的同時滿足大批量日志的分析需求,是擺在企業面前的一道難題。
實施方案
從使用者角度,這套雲原生日志資料分析方案非常輕量化。利用
日志服務 LOG(Log Service,簡稱LOG/原SLS)來投遞日志,
阿裡雲對象存儲服務(Object Storage Service,簡稱OSS)來存儲日志,
Data Lake Analytics(DLA)來分析日志。該方案有以下三個優勢:
- LOG是針對實時資料一站式服務,在阿裡集團經曆大量大資料場景錘煉而成。提供日志類資料采集、智能查詢分析、消費與投遞等功能,全面提升海量日志處理/分析能力。LOG強大的日志投遞能力,能夠從源頭對接各種類型的日志格式,并且穩定地将日志投遞到指定的位置。
- OSS極低廉的存儲成本,能夠讓您的日志檔案存儲任意長的時間。
- DLA強大的分析能力,Serverless的架構,按掃描量收費。DLA可以對投遞到OSS上的日志按年、按月、按日進行多元度的分區,提高日志的命中率,降低掃描量,進而以極低的成本、極高的性能來完成大資料量曆史日志分析。分析完的資料,還可以利用DLA的雲上資料源打通能力,回流到多種雲資料系統(RDS, OSS, Table Store, AnalyticDB,PolarDB等)中。

前提條件
在開始實施步驟之前,需要先完成以下準備工作。
- 參考文檔 LOG快速入門 ,開通日志服務、建立項目、建立日志庫。
- 開通OSS服務 、在日志服務項目所在的地域 建立存儲空間 。
- 開通并初始化DLA服務
實施步驟
步驟一:通過Logtail采集ECS日志
詳細操作請參見
通過Logtail采集ECS日志根據本示例中的日志檔案特點,Logtail配置如下所示。本截圖示例中是以正規表達式的方式進行采集和字段提取為例,當然,日志服務支援多種采集和提取方式,本文隻是示例其中一種。

模式選擇完整正則模式,需要提供完整正規表達式。
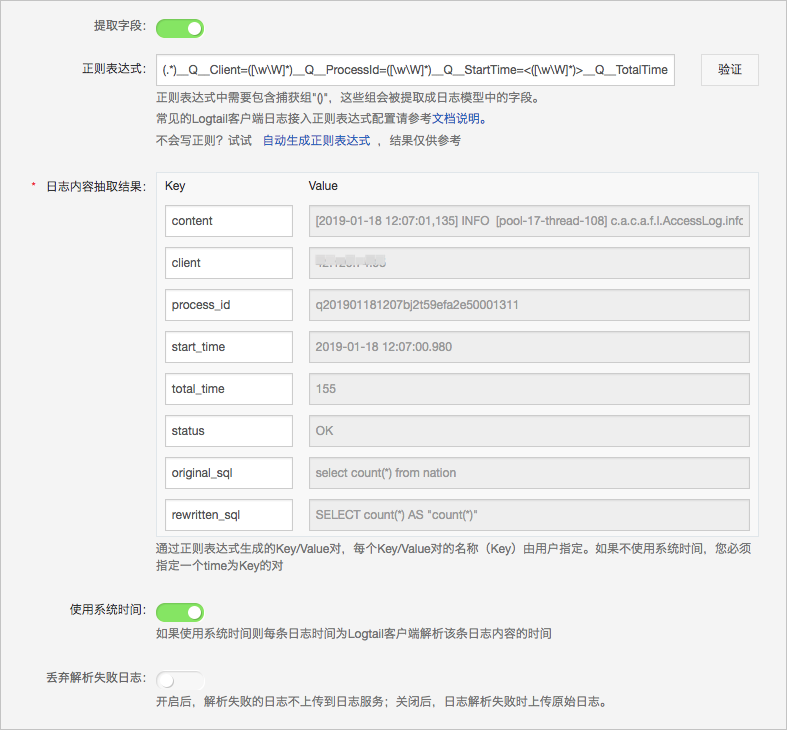
步驟二:投遞日志到OSS
投遞日志到OSS,并且
日志服務投遞OSS使用Parquet存儲的相關配置在OSS投遞功能頁面,配置各項參數,關于各項參數配置說明:
https://help.aliyun.com/document_detail/29002.html
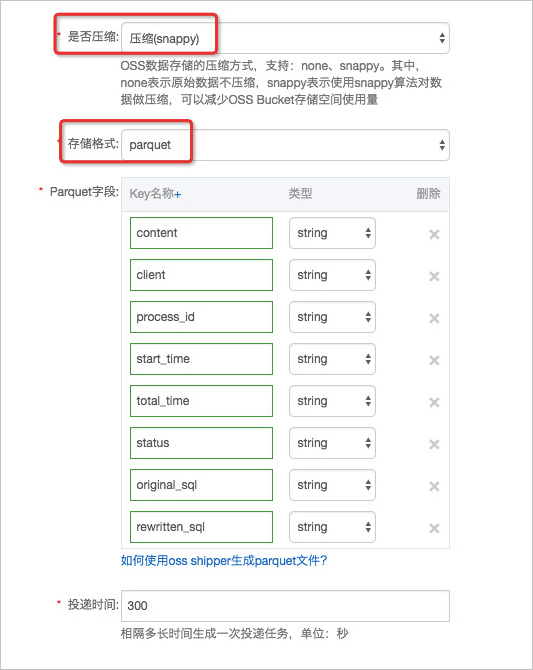
參數說明:
- OSS Bucket和OSS Prefix設定日志投遞到OSS的哪個目錄。
- 修改分區格式,将分區列的名字填入到目錄中:
-
格式為分區列名=分區列值。
如圖所示,修改分區格式預設值,即一級分區列的列名為year,列值為%Y; 二級分區列的列名為month,列值為%m;三級分區列的列名為day,列值為%d;如果分區粒度想到小時(每小時産生的資料量較大時),可以設定四級分區,列名為hour,列值為%H。
- 如果不使用分區列名=分區列值的形式也可以,即保留日志服務保留的預設分區格式:%Y/%m/%d/%H/%M,但是這裡是到分鐘級别的分區,粒度通常太小,可以改成%Y/%m/%d/%H%M,到天級别分區。
-
- 存儲格式設定為parquet。
- 壓縮方式設定為snappy,使用snappy算法對資料做壓縮,可以減少OSS Bucket存儲空間使用量。
日志資料投遞到OSS中以後,就可以通過DLA讀取并分析OSS中的日志。
步驟三:在DLA中建立OSS連接配接
登入
DLA控制台,登入DMS,在DLA中建立一個到OSS的連接配接。文法如下:
_
CREATE SCHEMA oss_log_schema with DBPROPERTIES(
catalog='oss',
location = 'oss://myappbucket/sls_parquet/'
); location:日志檔案所在的OSS Bucket的目錄,需以
/
結尾表示目錄。myappbucket是OSS Bucket名字。
步驟四:在DLA中建立指向OSS日志檔案的外表(分區表)
如果在步驟二中,SLS投遞到OSS分區配置的分區為year、month、day,則建表示例如下:
CREATE EXTERNAL TABLE sls_parquet (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (year STRING, month STRING, day STRING)
STORED AS PARQUET
LOCATION 'oss://myappbucket/sls_parquet/'; 注意:
- 建立表中的列名要和生成的parquet檔案中設定的列名一緻。
- 分區列的名稱、順序需要和步驟二:投遞日志到OSS中的分區列一緻。更多建立分區表資訊,請參見 通過DLA建立OSS分區表
- LOCATION中,根據示例,OSS上檔案路徑示例應該類似:oss://myappbucket/sls_parquet/year=2019/month=01/day=01/,或者oss://myappbucket/sls_parquet/2019/01/01/,LOCATION應該指定到實際分區開始目錄的父目錄一層,即oss://myappbucket/sls_parquet/。
步驟五:使用指令添加、維護分區資訊
步驟四外表建立成功後,執行
MSCK REPAIR TABLE
将分區資訊同步到DLA中。
MSCK REPAIR TABLE sls_parquet; - MSCK指令隻能識别符合DLA分區列命名規則的目錄,即分區列的目錄名為分區列名=分區列值,例如:oss://myappbucket/sls_parquet/year=2019/month=01/day=01/;
- MSCK指令可以一次性識别目前OSS上實際存在的符合分區命名規則的所有分區,如果後面OSS上有新增分區,需要再次執行上述MSCK指令;
- 可以通過SHOW PARTITIONS sls_parquet指令檢視目前實際DLA能看到的分區情況,如果初次沒有執行MSCK指令,SHOW PARTITIONS sls_parquet應該傳回空,看不到任何分區,執行MSCK完後,再執行SHOW PARTITIONS sls_parquet應該傳回目前OSS上實際符合分區命名規則的所有分區。
如果之前配置投遞到OSS上的資料目錄如:oss://myappbucket/sls_parquet/2019/01/01/
則執行:
ALTER TABLE sls_parquet ADD
PARTITION (year='2019', month='01', day='01')
LOCATION 'oss://myappbucket/sls_parquet/2019/01/01/'; 該指令隻添加了一個分區:2019/01/01/
也可以一次添加多個分區:
ALTER TABLE sls_parquet ADD
PARTITION (year='2019', month='01', day='01')
LOCATION 'oss://myappbucket/sls_parquet/2019/01/01/',
PARTITION (year='2019', month='01', day='02')
LOCATION 'oss://myappbucket/sls_parquet/2019/01/02/',
PARTITION (year='2019', month='01', day='03')
LOCATION 'oss://myappbucket/sls_parquet/2019/01/03/',
PARTITION (year='2019', month='01', day='04')
LOCATION 'oss://myappbucket/sls_parquet/2019/01/04/'; 該指令添加了四個分區。
- 可以通過SHOW PARTITIONS sls_parquet指令檢視目前實際DLA能看到的分區情況,如果初次沒有執行ALTER TABLE ADD PARTITION指令,SHOW PARTITIONS sls_parquet應該傳回空,看不到任何分區,執行ALTER TABLE ADD PARTITION完後,再執行SHOW PARTITIONS sls_parquet應該傳回實際添加的分區資訊。
另外一個類似的例子,如果之前配置投遞到OSS上的資料目錄如:
oss://myappbucket/sls_parquet/2019-01-01
oss://myappbucket/sls_parquet/2019-01-02
oss://myappbucket/sls_parquet/2019-01-03
oss://myappbucket/sls_parquet/2019-01-04
則對應的DLA建表語句:
CREATE EXTERNAL TABLE sls_parquet (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (day STRING)
STORED AS PARQUET
LOCATION 'oss://myappbucket/sls_parquet/'; 則執行如下語句添加分區:
ALTER TABLE sls_parquet ADD
PARTITION (day='2019-01-01') LOCATION 'oss://myappbucket/sls_parquet/2019-01-01/',
PARTITION (day='2019-01-02') LOCATION 'oss://myappbucket/sls_parquet/2019-01-02/',
PARTITION (day='2019-01-03') LOCATION 'oss://myappbucket/sls_parquet/2019-01-03/',
PARTITION (day='2019-01-04') LOCATION 'oss://myappbucket/sls_parquet/2019-01-04/'; 步驟六:查詢分區表資料
分區資訊同步完成後,使用
SELECT
語句對日志進行查詢分析。例如,對于本示例中,查詢sls_parquet表得到某一天查詢最慢的5條語句。
SELECT original_sql, total_time
FROM sls_parquet
WHERE client != '' AND year='2019' AND month = '01' AND day = '01'
ORDER BY total_time DESC
LIMIT 5; 後續操作
上述示例中,日志資料投遞OSS的存儲格式為Parquet格式,除了Parquet格式,LOG還可以将投遞檔案的格式設定為JSON和CSV。詳細的配置,請參見
JSON格式和
CSV格式- 當投遞檔案的格式設定為JSON且無壓縮時,建表語句為:
CREATE EXTERNAL TABLE sls_json (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (year STRING, month STRING, day STRING)
STORED AS JSON
LOCATION 'oss://myappbucket/sls_json/'; - 當投遞檔案的格式設定為JSON且使用标準Snappy壓縮時,建表語句為:
CREATE EXTERNAL TABLE sls_json_snappy (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (year STRING, month STRING, day STRING)
STORED AS JSON
LOCATION 'oss://myappbucket/sls_json_snappy/'
TBLPROPERTIES(
'text.compression'='snappy',
'io.compression.snappy.native'='true'
); - 必須指定TBLPROPERTIES( 'text.compression'='snappy', 'io.compression.snappy.native'='true')的屬性。
- 當投遞檔案的格式設定為CSV,不包含header,使用标準Snappy壓縮時,建表語句為:
CREATE EXTERNAL TABLE sls_csv_snappy (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (year STRING, month STRING, day STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES(
'separatorChar'=',',
'quoteChar'='"',
'escapeChar'='\\'
)
STORED AS TEXTFILE
LOCATION 'oss://myappbucket/sls_csv_snappy/'
TBLPROPERTIES(
'text.compression'='snappy',
'io.compression.snappy.native'='true',
'skip.header.line.count'='0'
); -
雲原生日志資料分析上手指南雲原生日志資料分析上手指南 - 當投遞檔案的格式設定為CSV無壓縮,且包含header時,建表語句為:
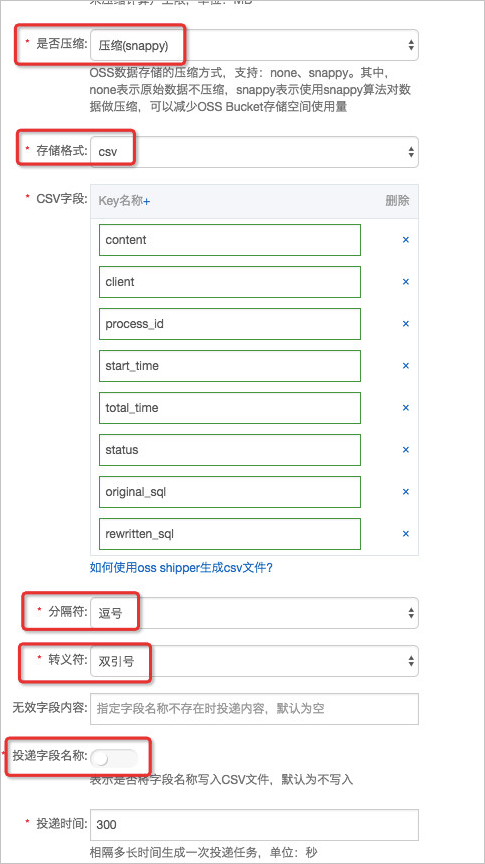
CREATE EXTERNAL TABLE sls_csv (
content STRING,
client STRING,
process_id STRING,
start_time STRING,
total_time STRING,
status STRING,
original_sql STRING,
rewritten_sql STRING
) PARTITIONED BY (year STRING, month STRING, day STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES(
'separatorChar'=',',
'quoteChar'='"',
'escapeChar'='\\'
)
STORED AS TEXTFILE
LOCATION 'oss://myappbucket/sls_csv/'
TBLPROPERTIES(
'skip.header.line.count'='1'
); 關于更多的檔案格式對應的建表支援情況,請參考:
https://yq.aliyun.com/articles/623246更多參考
- Data Lake Analytics學習路徑: https://help.aliyun.com/learn/learningpath/datalakeanalytics.html
- Data Lake Analytics知乎專欄: https://zhuanlan.zhihu.com/data-lake-analytics
- 阿裡雲Data Lake Analytics産品專欄: https://yq.aliyun.com/teams/396
- 雲栖社群: https://yq.aliyun.com/topic/138
1元10TB的資料分析流量包和流量包優惠活動:
https://et.aliyun.com/bdad/datalake![SpringMVC 傳回json的兩種方式[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)