微服務化産品線,每一個服務專心于自己的業務邏輯,并對外提供相應的接口,看上去似乎很明了,其實還有很多的東西需要考慮,比如:服務的自動擴充,熔斷和限流等,随着業務的擴充,服務的數量也會随之增多,邏輯會更加複雜,一個服務的某個邏輯需要依賴多個其他服務才能完成。一但一個依賴不能提供服務很可能會産生 雪崩效應
,最後導緻整個服務不可通路。
微服務之間進行
rpc
http
調用逾時
失敗重試
等機制來確定服務的成功執行,看上去很美,如果不考慮服務的熔斷和限流,就是雪崩的源頭。
假設我們有兩個通路量比較大的服務A和B,這兩個服務分别依賴C和D,C和D服務都依賴E服務
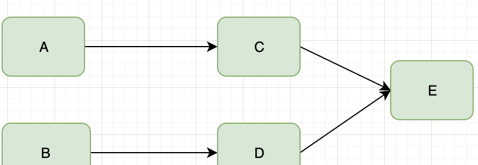
逾時
重試

- 程式bug導緻服務不可用,或者運作緩慢
- 緩存擊穿,導緻調用全部通路某服務,導緻down掉
- 通路量的突然激增。
- 硬體問題,這感覺隻能說是點背了⊙︿⊙。
雖然雪崩效應的産生千萬條,保證服務的不挂機,和流暢運作是我們不可推卸的責任,對應雪崩效應還是有很多保護方案的。
服務的橫向擴充
現在我們可以利用很多工具來保證服務不會挂掉,然後流量比較大的時候,可以橫向擴充服務來保證業務的流暢。比如我們最常使用k8s,能保證服務的運作狀态,也可以讓服務自動的橫向擴充。對于使用者通路量的激增情況這樣處理還是很不錯的,但是,橫向擴充也是有盡頭的,如果在一定環境下
E
服務的響應時間過長,依然有可能導緻雪崩效應的産生。
限流
限制用戶端的調用來達到限流的做法是很常見的,比如,我們限制每秒最大處理200個請求,超過個數量直接拒絕請求。常見的算法如
令牌桶算法以一定的速度在桶裡放令牌,當用戶端請求服務的時候,要先從桶裡得到令牌,才能被處理,如果沒桶裡的令牌用完了,則拒絕通路。
熔斷
在用戶端控制對依賴的通路,如果調用的依賴不可用時,則不再調用,直接傳回錯誤,或者降級處理。開源的庫比如
hystrix-go,也是我接下來要寫的源碼分析的一個庫。很好的實作了熔斷和降級的功能。他的主要思想是,設定一些閥值,比如,最大并發數,錯誤率百分比,熔斷嘗試恢複時間等。能過這些閥值來轉換熔斷器的狀态:
- 關閉狀态,允許調用依賴
- 打開狀态,不允許調用依賴,直接傳回錯誤,或者調用fallback
- 半開狀态,根據
熔斷嘗試恢複時間
關閉
打開
具體的實作方式和對
源碼的分析,我在後續的文章會詳細給大家介紹。