如果問 mapreduce 和 spark 什麼關系,或者說有什麼共同屬性,你可能會回答他們都是大資料處理引擎。如果問 spark 與 tensorflow 呢,就可能有點迷糊,這倆關注的領域不太一樣啊。但是再問 spark 與 MPI 呢?這個就更遠了。雖然這樣問多少有些不嚴謹,但是它們都有共同的一部分,這就是我們今天談論的一個話題,一個比較大的話題:分布式計算架構。
不管是 mapreduce,還是 spark 亦或 tensorflow,它們都是利用分布式的能力,運作某些計算,解決一些特定的問題。從這個 level 講,它們都定義了一種“分布式計算模型”,即提出了一種計算的方法,通過這種計算方法,就能夠解決大量資料的分布式計算問題。它們的差別在于提出的分布式計算模型不同。Mapreduce 正如其名,是一個很基本的 map-reduce 式的計算模型(好像沒說一樣)。Spark 定義了一套 RDD 模型,本質上是一系列的 map/reduce 組成的一個 DAG 圖。Tensorflow 的計算模型也是一張圖,但是 tensorflow 的圖比起 spark 來,顯得更“複雜”一點。你需要為圖中的每個節點和邊作出定義。根據這些定義,可以指導 tensorflow 如何計算這張圖。Tensorflow 的這種具體化的定義使它比較适合處理特定類型的的計算,對 tensorflow 來講就是神經網絡。而 spark 的 RDD 模型使它比較适合那種沒有互相關聯的的資料并行任務。那麼有沒有一種通用的、簡單的、性能還高的分布式計算模型?我覺着挺難。通用往往意味着性能不能針對具體情形作出優化。而為專門任務寫的分布式任務又做不到通用,當然也做不到簡單。
插一句題外話,分布式計算模型有一塊伴随的内容,就是排程。雖然不怎麼受關注,但這是分布式計算引擎必備的東西。mapreduce 的排程是 yarn,spark 的排程有自己内嵌的排程器,tensorflow 也一樣。MPI 呢?它的排程就是幾乎沒有排程,一切假設叢集有資源,靠 ssh 把所有任務拉起來。排程實際上應當分為資源排程器和任務排程器。前者用于向一些資源管理者申請一些硬體資源,後者用于将計算圖中的任務下發到這些遠端資源進行計算,其實也就是所謂的兩階段排程。近年來有一些 TensorflowOnSpark 之類的項目。這類項目的本質實際上是用 spark 的資源排程,加上 tensorflow 的計算模型。
當我們寫完一個單機程式,而面臨資料量上的問題的時候,一個自然的想法就是,我能不能讓它運作在分布式的環境中?如果能夠不加改動或稍加改動就能讓它分布式化,那就太好了。當然現實是比較殘酷的。通常情況下,對于一個一般性的程式,使用者需要自己手動編寫它的分布式版本,利用比如 MPI 之類的架構,自己控制資料的分發、彙總,自己對任務的失敗做容災(通常沒有容災)。如果要處理的目标是恰好是對一批資料進行批量化處理,那麼 可以用 mapreduce 或者 spark 預定義的 api。對于這一類任務,計算架構已經幫我們把業務之外的部分(腳手架代碼)做好了。同樣的,如果我們的任務是訓練一個神經網絡,那麼用 tensorflow pytorch 之類的架構就好了。這段話的意思是,如果你要處理的問題已經有了對應架構,那麼拿來用就好了。但是如果沒有呢?除了自己實作之外有沒有什麼别的辦法呢?
今天注意到一個項目,
Ray ,聲稱你隻需要稍微修改一下你的代碼,就能讓它變為分布式的(實際上這個項目早就釋出了,隻是一直沒有刻意關注它)。當然這個代碼僅局限于 python,比如下面這個例子,+------------------------------------------------+----------------------------------------------------+
| **Basic Python** | **Distributed with Ray** |
+------------------------------------------------+----------------------------------------------------+
| | |
| # Execute f serially. | # Execute f in parallel. |
| | |
| | @ray.remote |
| def f(): | def f(): |
| time.sleep(1) | time.sleep(1) |
| return 1 | return 1 |
| | |
| | |
| | ray.init() |
| results = [f() for i in range(4)] | results = ray.get([f.remote() for i in range(4)]) |
+------------------------------------------------+----------------------------------------------------+ 這麼簡單?這樣筆者想到了
openmp
(注意不是
openmpi
)。來看看,
#include<iostream>
#include"omp.h"
using namespace std;
void main() {
#pragma omp parallel for
for(int i = 0; i < 10; ++i) {
cout << "Test" << endl;
}
system("pause");
} 把頭檔案導入,添加一行預處理指令就可以了,這段代碼立馬變為并行執行。當然 openmp 不是分布式,隻是借助編譯器将代碼中需要并行化的部分編譯為多線程運作,本身還是一個程序,是以其并行度收到 CPU 線程數量所限。如果 CPU 是雙線程,那隻能 2 倍加速。在一些伺服器上,CPU 可以是單核 32 線程,自然能夠享受到 32 倍加速(被并行化的部分)。不過這些都不重要,在使用者看來,Ray 的這個做法和 openmp 是不是有幾分相似之處?你不需要做過多的代碼改動,就能将代碼變為分布式執行(當然 openmp 要更絕一點,因為對于不支援 openmp 的編譯器它就是一行注釋而已)。
那麼 Ray 是怎麼做到這一點的呢?其實 Ray 的做法說起來也比較簡單,就是定義了一些 API,類似于 MPI 中的定義的通信原語。使用的時候,将這些 API “注入”到代碼合适的位置,那麼代碼就變成了使用者代碼夾雜着一些 Ray 架構層的 API 調用,整個代碼實際上就形成了一張計算圖。接下來的事情就是等待 Ray 把這張計算圖完成傳回就好了。Ray 的論文給了個例子:
@ray.remote
def create_policy():
# Initialize the policy randomly.
return policy
@ray.remote(num_gpus=1)
class Simulator(object):
def __init__(self):
# Initialize the environment.
self.env = Environment()
def rollout(self, policy, num_steps):
observations = []
observation = self.env.current_state()
for _ in range(num_steps):
action = policy(observation)
observation = self.env.step(action)
observations.append(observation)
return observations
@ray.remote(num_gpus=2)
def update_policy(policy, *rollouts):
# Update the policy.
return policy
@ray.remote
def train_policy():
# Create a policy.
policy_id = create_policy.remote()
# Create 10 actors.
simulators = [Simulator.remote() for _ in range(10)]
# Do 100 steps of training.
for _ in range(100):
# Perform one rollout on each actor.
rollout_ids = [s.rollout.remote(policy_id)
for s in simulators]
# Update the policy with the rollouts.
policy_id = update_policy.remote(policy_id, *rollout_ids)
return ray.get(policy_id) 生成的計算圖為
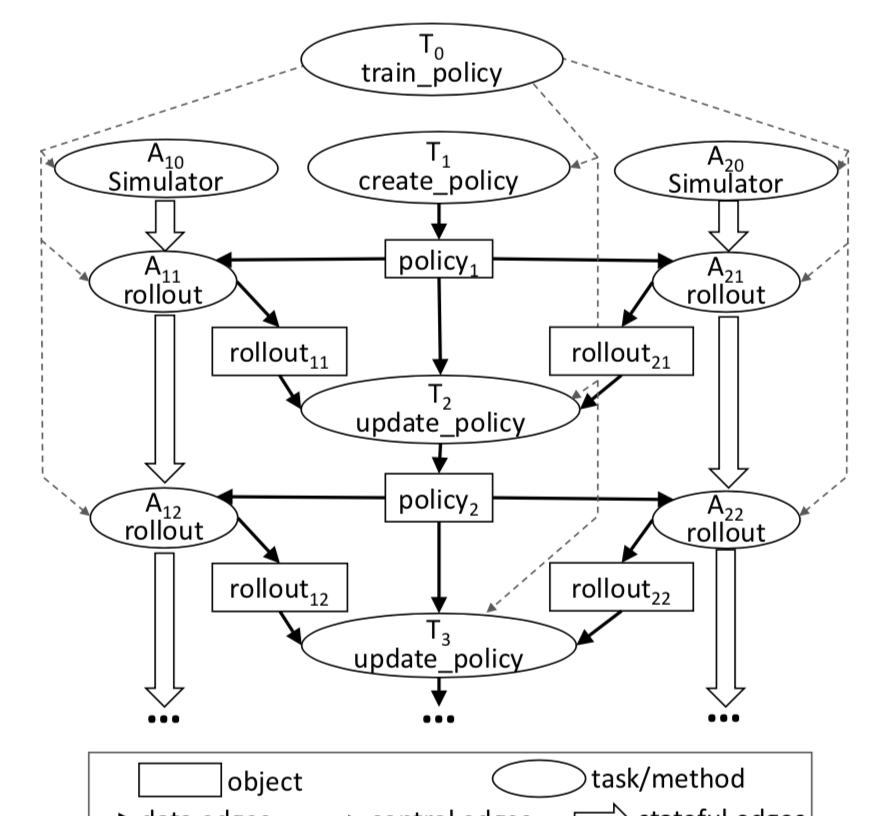
是以,使用者要做的事情,就是在自己的代碼裡加入适當的 Ray API 調用,然後自己的代碼就實際上變成了一張分布式計算圖了。作為對比,我們再來看看 tensorflow 對圖的定義,
import tensorflow as tf
# 建立資料流圖:y = W * x + b,其中W和b為存儲節點,x為資料節點。
x = tf.placeholder(tf.float32)
W = tf.Variable(1.0)
b = tf.Variable(1.0)
y = W * x + b
with tf.Session() as sess:
tf.global_variables_initializer().run() # Operation.run
fetch = y.eval(feed_dict={x: 3.0}) # Tensor.eval
print(fetch) # fetch = 1.0 * 3.0 + 1.0
'''
輸出:
4.0
''' 可以看出,tensorflow 中是自己需要自己顯式的、明确的定義出圖的節點,
placeholder
Variable
等等(這些都是圖節點的具體類型),而 Ray 中圖是以一種隐式的方式定義的。我認為後者是一種更自然的方式,站在開發者的角度看問題,而前者更像是為了使用 tensorflow 把自己代碼邏輯去适配這個輪子。
那麼 ray 是不是就我們要尋找的那個即通用、又簡單、還靈活的分布式計算架構呢?由于筆者沒有太多的 ray 的使用經驗,這個問題不太好說。從官方介紹來看,有限的幾個 API 确實是足夠簡單的。僅靠這幾個 API 能不能達成通用且靈活的目的還不好講。本質上來說,Tensorflow 對圖的定義也足夠 General,但是它并不是一個通用的分布式計算架構。由于某些問題不在于架構,而在于問題本身的分布式化就存在困難,是以試圖尋求一種通用分布式計算架構解決單機問題可能是個僞命題。
話扯遠了。假設 ray 能夠讓我們以一種比較容易的方式分布式地執行程式,那麼會怎麼樣呢?前不久 Databricks 開源了一個新項目,
Koalas,試圖以 RDD 的架構并行化 pandas。由于 pandas 的場景是資料分析,和 spark 面對的場景類似,兩者的底層存儲結構、概念也是很相似的,是以用 RDD 來分布式化 pandas 也是可行的。我想,如果 ray 足夠簡單好用,在 pandas 裡加一些 ray 的 api 調用花費的時間精力可能會遠遠小于開發一套 koalas。但是在 pandas 裡加 ray 就把 pandas 綁定到了 ray 上,即便單機也是這樣,因為 ray 做不到像 openmp 那樣如果支援,很好,不支援也不影響代碼運作。
啰嗦這麼多,其實就想從這麼多引擎的細節中跳出來,思考一下到底什麼是分布式計算架構,每種架構又是設計的,解決什麼問題,有什麼優缺點。最後拿大佬的一個觀點結束本文。David Patterson 在演講 “New Golden Age For Computer Architecture” 中提到,通用硬體越來越逼近極限,要想要達到更高的效率,我們需要設計面向領域的架構(Domain Specific Architectures)。這是一個計算架構層出不窮的時代,每種架構都是為了解決其面對的領域問題出現的,必然包含對其問題的特殊優化。通用性不是使用者解決問題的出發點,而更多的是架構設計者的“一廂情願”,使用者關注的永遠是領域問題。從這個意義上講,面向領域的計算架構應該才是正确的方向。
聲明:限于本人水準有限,文中陳述内容可能有誤。歡迎批評指正。
![【Tensorflow】Tensorflow介紹[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)