作者李鵬,原文首發于InfoQ,《 容器混合雲,Kubernetes 助力基因分析 》
引言
James Watson 和 Francis Crick 于 1953 年發現了 DNA 的雙螺旋結構,從此揭開了物種進化和遺傳的神秘面紗,開啟了人類對數字化遺傳的認知,但是人類基因奧秘卻是一點點被讀懂的。
1956 年,一則癌症和染色體相關性的發現令整個癌症研究界震動:慢性骨髓性白血病(CML)患者的第 22 号染色體,比一般然明顯短很多。二十餘年後,學者們發現,9 号染色體的 Abl 基因,與 22 号染色體的 BCR 基因連到了一塊,交錯易位産生了一條 BCR-Abl 融合基因。BCR-Abl 蛋白一直處于活躍狀态且不受控制,引發不受控的細胞分裂,進而導緻癌症。
也就是說,隻要細胞表達 BCR-Abl 蛋白,就有血癌風險。美國着手深入研究,并成功推出了治療慢性骨髓性白血病的新藥。這,就是格列衛,也是去年《我不是藥神》中被我們熟知的‘高價藥’。
在格列衛誕生前,隻有 30% 的慢性骨髓性白血病患者能在确診後活過 5 年。格列衛将這一數字從 30% 提高到了 89%,且在 5 年後,依舊有 98% 的患者取得了血液學上的完全緩解。為此,它也被列入了世界衛生組織的基本藥物标準清單,被認為是醫療系統中“最為有效、最為安全,滿足最重大需求”的基本藥物之一。
容器混合雲如何應對基因測序的 IT 挑戰
基因測序在血液惡性良性腫瘤領域應用的越來越廣泛。根據病人的診斷結果, 血液惡性良性腫瘤專科醫生會選擇相應的檢查,比如 PCR 結合實時熒光探針技術, 來檢測測 BCR-Abl 融合基因, 以診斷慢性骨髓性白血病, 也可以通過二代測序方式,SEGF(Single-end Gene Fusion)能夠通過單端 NGS 測序資料檢測複雜的基因融合類型。
在另一面,無創産檢唐氏/愛德華式篩查,近年來以高準确率和對胎兒的低風險,越來越受到國内年輕産婦的歡迎。基因公司每年都完成幾十萬例的 NIPT 檢查,每一例的 NIPT 涉及到數百 MB+ 的資料處理,存儲和報告生成。一家大型基因測序功能公司每日會産生 10TB 到 100TB 的下機資料,大資料生信分析平台需要達到 PB 級别的資料處理能力。這背後是生物科技和計算機科技的雙向支撐:測序應用從科研逐漸走向臨床應用,計算模式從離線向線上演進,傳遞效率越來越重要。
基因計算面臨以下幾方面挑戰:
1.資料存儲:資料增長快,存儲費用高,管理困難;長期儲存資料可靠性難以保障;需要尋求低成本大資料量的資料壓縮方式;中繼資料管理混亂,資料清理困難。
2.分發共享:海量資料需要快速、安全的分發到國内多地及海外;傳統硬碟寄送方式周期長,可靠性低;多地中心資料需要共享通路。
3.計算分析:批量樣本處理時間長,資源需求峰谷明顯,難以規劃;大規模樣本的資料挖掘需要海量計算資源,本地叢集難以滿足;計算工作1. 3. 流流程遷移困難、線上線下排程困難、跨地域管理困難;線下彈性能力差,按需計算需求。
4.安全合規:基因資料安全隐私要求極高;自建資料中心安全防護能力不足;資料合約(區塊鍊);RAM 子賬号支援。
而這樣看來一套完備架構方案則是必不可少的。與傳統高性能計算相比,按需切分任務的需求,自動從雲中申請資源,自動伸縮能力達到最小化資源持有成本,90% 以上的資源使用率,用完後自動返還計算資源。最大化資源的使用效率,最低單樣本的處理成本,最快速的完成大批量樣本的處理。随着基因測序業務增長,自動完成線下資源使用,和線上資源擴容。高速内網帶寬,和高吞吐的存儲,和幾乎無限的存儲空間。
基因計算不同于正常的計算,對海量資料計算和存儲能力都提出了很高的要求。主要通過容器計算的自動伸縮特性和阿裡雲 ECS 的自動伸縮能力的打通,可以大規模彈性排程雲上的計算資源。通過對基因資料的合理切分,實作大規模的并行計算同時處理 TB 級别的樣本資料。通過按需擷取的計算能力,以及高吞吐的對象存儲的使用,大幅降低了計算資源持有的成本和單個樣本的處理成本。
整體技術架構是雲原生容器混合雲,雲上雲下資源一體,跨地域叢集統一管理。作為主要 Player,容器技術在資料分拆,資料品質控制,Call 變異提供了标準化流程化、加速、彈性、鑒權、觀測、度量等能力,在另外一方面,高價值挖掘需要借助容器化的機器學習平台和并行架構對基因、蛋白質、醫療資料完成大規模線性代數計算來建立模型,進而使精準醫療能力成為現實。
基因工程中的關鍵問題及解決方案
-
資料遷移與傳輸
資料遷移、資料拆分階段百萬小檔案的讀取對底層的檔案系統壓力,通過避免不必要小檔案的讀寫提高樣本的處理效率。 通過資料中心與阿裡雲的專線連接配接,實作高吞吐低延遲的資料上雲以及與工作流結合的上雲、校驗、檢測方式。而最終需要達成的目标是:在短時間内完成數十 TB 級資料的加密搬遷,確定資料傳輸用戶端的高性能與安全性,實作并發傳輸、斷點續傳,且保有完善的通路授權控制。
-
基因計算典型任務:增強型工作流
基因計算的典型特征就是資料分批計算,需要按照特定步驟先後依次完成。将該問題抽象後,即需要申明式工作流定義 AGS(AlibabaCloud Genomics Service) workflow。
其工作流的特點是:多層次,有向無環圖。科研大工作流 1000-5000+ 深度的 DAG,需要準确的流程狀态監控和高度的流程穩定性。簡單流程從任意步驟重制啟動 ,失敗步驟可以自動完成重試和繼續,定時任務,通知,日志,審計,查詢,統一操作入口 CLI/UI 。
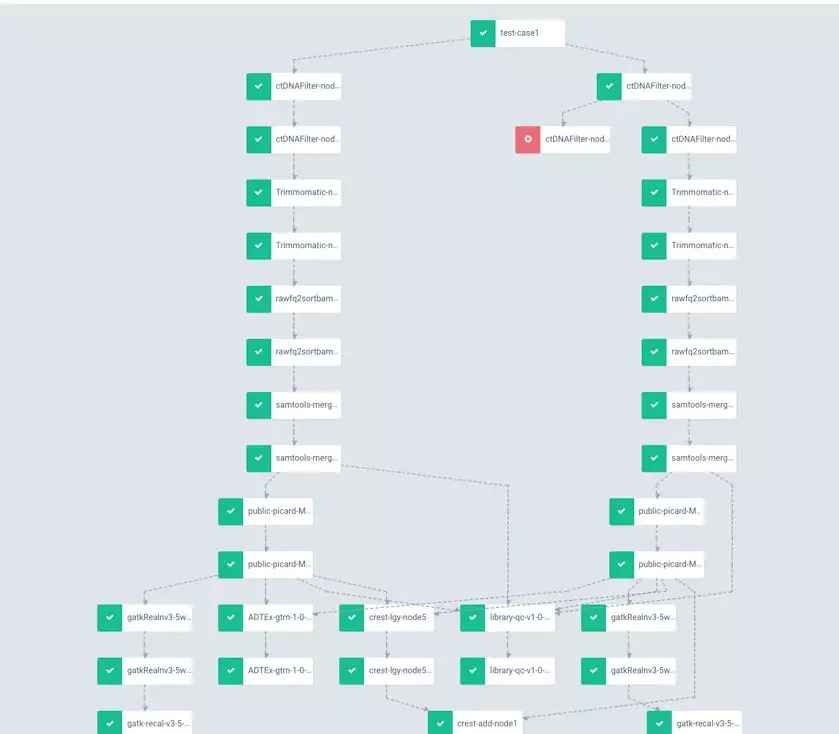
我們采用的方案是:
1.簡單 YAML 申明式定義,多層次,有向無環圖, 複雜依賴支援, 任務自動分拆,自動并行化;
2.雲原生,與社群 Argo 完全相容的增強性 Workflow 定義;
3.實時資源統計,監控內建雲監控,雲日志 SLS 內建, 審計內建, 定時任務;
4.統一操作入口 ags-cli 與 Kubectl 內建;
5.阿裡雲存儲卷申明式支援,NAS,OSS,CloudDisk, 緩存加速支援。
-
雲上雲下資源的統一排程
通過跨越 IDC 和雲上可用區的混合雲 ACK 叢集實作計算資源的統一排程和資料的雲端彙聚。自動化,流程化上雲資料,和後續的資料處理流程,形成 24 小時内完成批次下機資料的本地, 上雲,雲端處理和報告生成。按需彈性提供計算節點或者無服務化計算資源,形成按需計算能力,處理突發分析任務。我所帶領的阿裡雲基因資料服務團隊努力建構更具彈性的容器化叢集,分鐘級數百節點自動伸縮能力和分鐘級數千輕量容器拉起的 Serverless 能力, 通過提高并行度來提高内網帶寬的使用率,最終提高整體資料吞吐率,通過 NAS 用戶端和服務端的 TCP 優化來提高 IO 讀寫速度,通過為 OSS 增加緩存層和分布式的緩存來實作對象存儲讀取加速等等。
還有很多問題,篇幅原因在此不一一展開:如何進行基因資料管理、最優化機關資料處理成本、采用批量計算的方式進行對樣本分析、怎樣使得基因資料處理安全及跨組織安全分享等等。
生命科學和精準醫學應用,未來已來
NovaSeq 測序儀帶來了低成本(100$/WGS)高産出(6TB 通量)的二代測序方案,大量 NovaSeq 的使用為基因測序公司每天産出的幾十 TB 資料,這就要求大量的算力來分拆和發現變異,以及需要大量的存儲來儲存原始資料和變異資料。阿裡雲基因資料服務不斷提升極緻彈性的計算能力,和大規模并行處理能力,以及海量高速存儲來幫助基因公司快速自動化處理每天幾十上百 TB 的下機資料,并産通過 GATK 标準産出高品質的變異資料。
以 PacBio 和 Nanopore 為代表的三代測序的出現,超過 30K 到數百 K 的長讀,和 20GB 到 15TB 的大通量産出,長讀和資料量對資料比對,分拆,發現變異帶來了更大的算力需要和高 IO 吞吐的需求,對基因計算過程中優化基因分析流程,拆分資料,按需排程大量計算資源,提供超高的 IO 吞吐帶來了更大的挑戰。
解碼未知,丈量生命。科技的每一小步,都會成為人類前行的一大步。
本文作者
李鵬(Eric Li),阿裡雲資深架構師,資料科學家,美國 FDA2018 精準醫療大賽Top2 Winner ,金融/生物計算行業解決方案專家,專注于基于 Kubernetes 的容器産品開發和銀行,生信行業的生産落地。在加入阿裡雲之前,曾在 IBM 擔任 Watson 資料服務容器平台首席架構師,機器學習平台架構師,IBM 2015 Spark 全球大賽金獎獲得者,帶領多個大型開發項目,涵蓋雲計算,資料庫性能工具、分布式架構、生物計算,大資料和機器學習。
![初談驗證碼與驗證碼設計[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)