01 什麼是Python
Python是一種程式設計語言,可以讓你更快地工作,并且能夠更有效地內建系統。Python語言由Guido van Rossum開發。你可以在Python的曆史部落格上閱讀Guido講述的Python曆史。
http://python-history.blogspot.in/2009/01/introduction-and-overview.html對于Python初學者甚至是經驗豐富的人來說,這是值得一讀的。以下是其中一段摘錄:
許多Python的關鍵字(if、else、while、for等)與C語言中的相同,Python辨別符與C語言具有相同的命名規則,大多數标準運算符與C語言具有相同的含義。當然,顯然Python不是C語言,它和C語言一個主要的不同是使用縮進而不是大括号進行語句分組。例如,在C語言中按如下方式編寫語句:
Python隻是完全省略了括号(以及為了維護良好标準而使用的句末分号)并使用以下結構:
Python與C語言不同的另一個主要領域是動态類型的使用。在C中,必須始終明确聲明變量并給定其特定類型,如int或double。然後,此資訊用于執行程式的靜态編譯時檢查以及配置設定存儲變量值的記憶體位置。在Python中,變量隻是引用對象的名稱。
Python Package Index(PyPI)托管Python的第三方子產品。目前有91 625個添加包。
https://pypi.python.org/pypi 你可以按主題浏覽Python的添加包。 https://pypi.python.org/pypi?%3Aaction=browse
02 什麼是R
有關R的官方定義見主網站:
http://www.r-project.org/about.htmlR是用于資料處理、計算和圖形顯示的內建軟體工具套件。它包括一個有效的資料處理和存儲設施,一套其中包含用于計算數列(特别是矩陣)的算子,一個用于資料分析的大型、連貫、內建的中間工具集合,其中包含用于資料分析的圖形工具,可在螢幕上或硬拷貝上顯示,以及一種發展良好、簡單有效的程式設計語言,包括條件、循環、使用者定義的遞歸函數以及輸入和輸出設施。
“環境”一詞旨在将其描述為一個完全規劃和連貫的系統,而不是非常特殊和不靈活的工具的增量增長(這是其他資料分析軟體的常見情況)。
Comprehensive R Archive Network(CRAN)上托管了數千個添加包R包:
https://cran.r-project.org/web/packages/ GitHub也是如此,請參閱: https://github.com/search?utf8=%E2%9C%93&q=stars%3A%3E1+language%3AR
還有Bioconductor作為添加包庫。
你可以在這裡檢視來自這些存儲庫的所有包(截至2016年共有11 885個包):
http://www.rdocumentation.org/R既是統計學中的語言,也是計算機科學和分析軟體,在分析商務資料和應用資料科學方面非常有用。特别是R的吸引力仍然存在:它是一個免費的開源軟體,擁有大量的添加包可用于資料分析。
R的缺點仍然是生産環境中的記憶體處理,缺乏對R開發人員的激勵,以及它有時生成的是稍顯學術導向而不是企業使用者導向的粗略文檔。
03 什麼是資料科學
資料科學位于程式設計、統計和業務分析的交叉點。它是根據統計技術以系統和科學的方式分析資料的編輯工具的應用。Drew Conway的著名圖表将資料科學作為三者的交集,見:
http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram我将資料科學家定義如下:
資料科學家隻是一個能夠在硬體(本地機器、資料庫、雲、伺服器上)上高效快速地編寫代碼(使用R、Python、Java、SQL、Hadoop(Pig、HQL、MR)等語言)來處理資料(存儲、查詢、彙總、可視化)的人,同時了解足夠的統計資料以從資料中擷取洞察力,以便業務部門做出決策。
04 資料科學家的未來
權威的《哈佛商業評論》将資料科學家定義為21世紀最性感的工作:
https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century/ 對工資的調查顯示,資料科學家的需求和薪水都在上漲,而且受過訓練的專業人員也面臨嚴重短缺,參見: http://www.forbes.com/sites/gilpress/2015/10/09/the-hunt-for-unicorn-data-scientists-lifts-salaries-for-all-data-analytics-professionals/ 事實上,這創造了一個新術語:獨角獸資料科學家(unicorn data scientist)。獨角獸資料科學家很難找到,因為他具備程式設計、統計和商業方面的所有技能。更新的圖1.1中的資料科學維恩圖可在上檢視。 http://www.anlytcs.com/2014/01/data-science-venn-diagram-v20.html
▲圖1.1 資料科學維恩圖,來源:Copyright©2014 Steven Geringer Raileigh, NC
此外,獨角獸是投資行業的術語,特别是風險投資行業,它代表一家初創公司,其估值超過10億美元。這個詞已經被Cowboy Ventures的Aileen Lee推廣。可以在這裡檢視:
http://graphics.wsj.com/billion-dollar-club /和 http://fortune.com/unicorns/ 毫不奇怪,資料科學也為這些初創企業提供了關鍵優勢。是以,我們可以同時滿足不斷增長的需求和資料科學家的短缺,創造更安全的工作環境。可以在Y Combinator上看到一份初創企業名單,其中包括與資料科學相關的初創企業: http://yclist.com/ 你可以在這裡檢視有關資料科學家工資的調查: http://www.burtchworks.com/2015/07/14/compensation-of-data-scientists-insights-from-the-past-year 年度Rexer Analytics調查有助于衡量資料挖掘者的技能和使用情況。你可以在這裡閱讀訪談: http://decisionstats.com/2013/12/25/karl-rexer-interview-on-the-state-of-analytics/或閱讀rexeranalytics上的報告:
www.rexeranalytics.com
是以,我們可以總結認為,具有合适技能的資料科學家在專業領域擁有美好的未來。
值得注意的是,資料科學家需要非常快速地更新技能,他們需要響應業務需求來建構資料科學解決方案。是以,過時的風險仍然能夠鼓勵資料科學家獲得多種技能。Insight在這裡提供了一個有趣的資料科學研究獎學金計劃:
http://insightdatascience.com/ GitHub上免費提供了資料科學的存儲庫: https://github.com/okulbilisim/awesome-datascience 言歸正傳,位于紐約的Byte學院提供基于Python的資料科學計劃,網址為: http://byteacademy.co/05 什麼是大資料
對于資料集而言,大資料是一個廣義的術語,它如此巨大或複雜,以至于傳統的資料處理應用程式不能滿足要求。3V模型有助于了解大資料,它們是:
數量(volume,資料的大小和規模)。
速度(velocity,流量或資料重新整理率)。
資料的多樣性(variety,結構化或非結構化類型)。
第四個V是準确性(veracity)。
處理大資料的典型方法是基于硬體,并且使用分布式計算、并行處理、雲計算和Hadoop堆棧等專用軟體。有關大資料的有趣觀點參見著名的R科學家Hadley Wickham博士的觀點:
https://peadarcoyle.wordpress.com/2015/08/02/interview-with-a-data-scientist-hadley-wickham/有兩個特别重要的過渡點:
從記憶體到磁盤。如果你的資料适合記憶體,那麼它就是小資料。現在你可以獲得1TB的記憶體,是以即使是小資料也很大!從記憶體遷移到磁盤是一個重要的過渡,因為通路速度是如此不同。你可以對記憶體資料進行非常樸素的計算,它會足夠快。而對于使用磁盤資料,你需要計劃(和索引)更多。
從一台計算機到多台計算機。當你的資料不再适合一台計算機上的一個磁盤時,會出現下一個重要門檻值。遷移到分布式環境會使計算變得更具挑戰性,因為你進行計算所需的所有資料不在同一個地方。設計分布式算法要困難得多,并且你會極大地受到資料在計算機之間分離方式的限制。
Wes McKinney,資料科學的主要Python添加包pandas的作者,提出此問題:
任何允許你使用以Python或R等語言編寫的使用者定義代碼做擴充的資料處理引擎必須解決至少這3個基本問題:
資料移動或通路:使用Python可以使用的形式通路運作時資料。不幸的是,這通常需要昂貴的序列化或反序列化,并可能主導系統運作時間。通過仔細建立共享位元組級記憶體布局可以避免序列化成本,但這樣做需要大量經驗豐富且報酬豐厚的人員同意為更大的成果進行重大工程投資。
向量化計算:啟用Python或R等解釋語言來分攤開銷并調用面向數組的快速編譯代碼(例如NumPy或pandas操作)。這些語言中的大多數添加包也希望使用數組/向量值而不是标量值。是以,如果你想使用自己喜歡的Python或R添加包,則需要此功能。
IPC開銷:調用外部函數的低級機制。這可能涉及通過UNIX socket發送帶有一些簡短指令的簡短消息。
http://wesmckinney.com/blog/the-problem-with-the-data-science-language-wars/對比小資料,我們将大資料定義為需要更多硬體(Cloud等)或更複雜的程式設計或專用軟體(Hadoop)的資料。
06 資料科學家可用的工具
資料科學家廣泛使用的一些(而不是全部)工具如下:
資料存儲:MySQL、Oracle、SQL Server、HBase、MongoDB和Redis。
資料查詢:SQL、Python、Java和R。
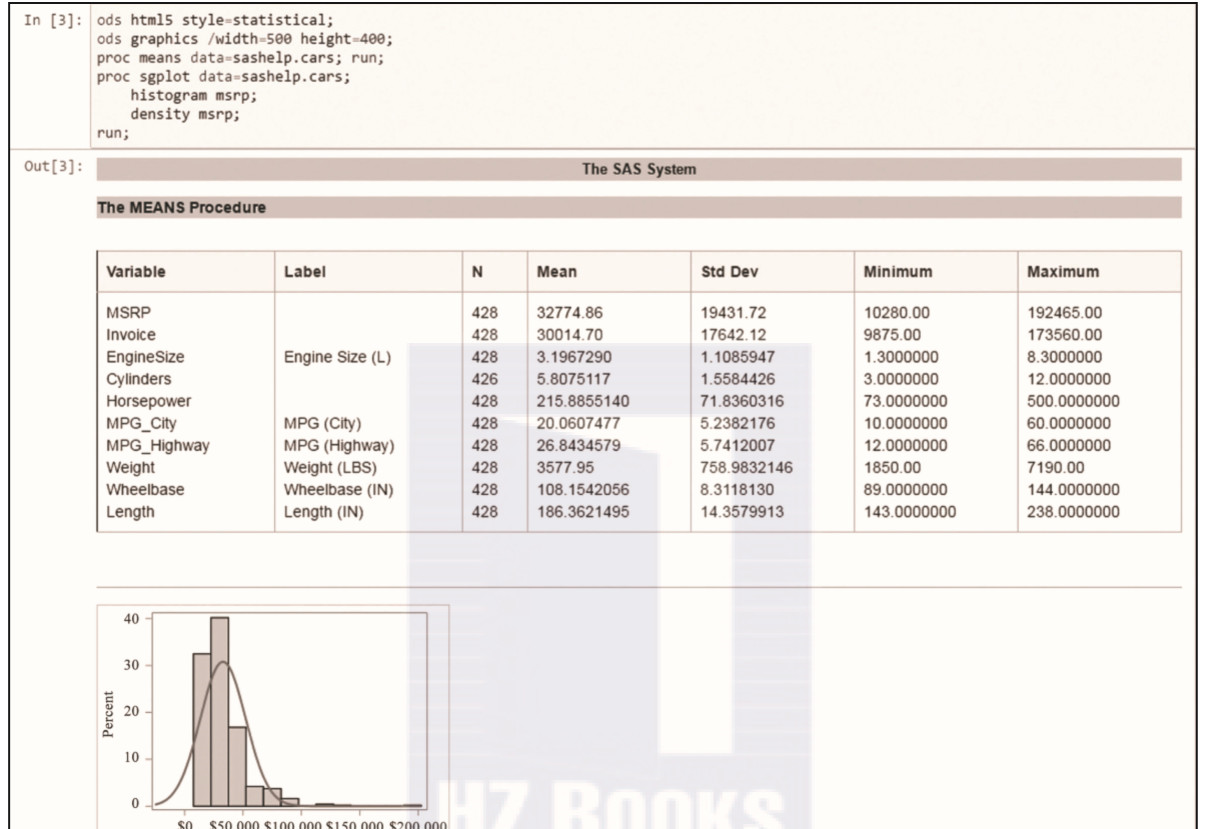
資料分析:SAS、R和Python。
資料可視化:JavaScript、R和Python。
資料挖掘:Clojure、R和Python。
雲:Amazon AWS、Microsoft Azure和Google Cloud。
Hadoop Big Data:Spark、HDFS MapReduce(Java)、Pig、Hive和Sqoop。
備忘單是一張帶有書面筆記的紙,旨在幫助記憶。它還可以定義為常用指令的彙總,以幫助你以更快的速度學習該語言的文法。為了幫助記住許多工具的文法,備忘單對于資料科學家來說非常有用。
我寫了一篇關于KDnuggets的文章,詳細闡述了我的哲學:什麼是或不是資料科學家。可見:
http://www.kdnuggets.com/2014/05/guide-to-data-science-cheat-sheets.html資料科學備忘單指南:
選擇最有用的資料科學備忘單,包括SQL、Python(包括NumPy、SciPy和Pandas)、R(包括回歸、時間序列、資料挖掘)、MATLAB等。
在過去的幾年裡,随着對資料科學家的需求不斷增長,人們渴望學習如何在這個看似有利可圖的職業中入門、學習、進步和茁壯成長。作為撰寫分析并偶爾教授分析的人,我經常被問到—如何成為資料科學家?
資料科學似乎是一個多學科領域,這使得這個問題的答案更加複雜,而大學的統計、計算機科學和管理部門處理資料的方式完全不同。
但是為了削減營銷創造的術語,資料科學家隻是一個人可以用幾種語言(主要是R、Python和SQL)編寫代碼,用于資料查詢、操作、聚合和可視化,使用足夠的統計知識為商務市場決策提供可操作的見解。
由于工作網站上附帶的詞彙“資料科學家”強調了其相當實用的定義,是以這裡有一些用于學習資料科學中的主要語言的工具—Python、R和SQL。
備忘單或參考卡是主要使用的指令的彙總,可幫助你以更快的速度學習該語言的文法。包含SQL可能會讓一些人感到驚訝(這不是NoSQL時代嗎?),但這是出于合乎邏輯的原因。PIG和Hive查詢語言都與SQL(原始結構化查詢語言)密切相關。
另外,你可以單獨使用R中的sqldf添加包(以及Pythonic資料科學家不太廣泛使用的python-sql或python-sql-parse添加包),甚至可以使用曾經的冠軍語言SAS中的Proc SQL指令,并完成資料科學家應該完成的大部分工作(至少在資料調整中)。
Python備忘單是一個相當有争議的清單,因為Python是資料科學家最通用的語言,可以用于完成很多事情。但對于資料科學家來說,NumPy、SciPy、pandas和scikit-learn的添加包似乎是最相關的。
成千上萬的R添加包對有抱負的資料科學家有用嗎?沒有。
是以,我們為你選擇了合适的備忘單。請注意,這是清單的策劃清單。如果在資料科學領域有任何可以假設的東西,那麼零假設應該是資料科學家足夠聰明,可以根據資料及其背景做出自己的決定。隻需三次列印就可以加速有抱負的資料科學家的旅程。
你還可以在這裡檢視Slide-Share上的示範文稿,其中擁有超過8000個視圖。
http://www.slideshare.net/ajayohri/cheat-sheets-for-data-scientist07 用于資料科學的Python添加包
一些在Python中對資料科學家有用的包如下:
pandas:為Python中的資料結構、資料操作和分析編寫的添加包。
NumPy:為大型多元數組和矩陣添加Python支援,以及在這些數組上運作進階數學函數的大型添加包。
IPython Notebook:示範面向資料分析的Python功能。
SciPy:用于科學計算的基礎庫。
Matplotlib:用于圖形和資料可視化的全面2D繪圖。
Seaborn:基于matplotlib的Python可視化庫。它提供了一個進階界面,用于繪制有吸引力的統計圖形。
scikit-learn:一個機器學習庫。
statsmodels:用于建構統計模型。
Beautiful Soup:用于網絡爬蟲。
Tweepy:用于Twitter抓取。
Bokeh :一個Python互動式可視化庫,面向現代Web浏覽器進行示範。它的目标不僅是以D3.js的風格提供優雅、簡潔的新穎圖形結構,而且還通過非常大或連續傳播的資料集提供高性能互動功能。它有Python、Scala、Julia以及現在的R接口。
http://bokeh.pydata.org/en/latest/ ggplot:基于R的ggplot2和圖形文法的Python繪圖系統。它專為使用最少的代碼快速制作具有專業外觀的圖而建構。 http://ggplot.yhathq.com/ 對于R,檢視添加包的最佳方法是檢視CRAN任務視圖,其中,添加包按使用類型聚合。 https://cran.r-project.org/web/views/ 例如,有關高性能計算的CRAN任務視圖,請通路: https://cran.r-project.org/web/views/HighPerformanceComputing.html08 Python和R之間的異同
Python用于各種用例,而R主要是統計學的語言。
Python有兩個版本:Python 2(或2.7)和Python 3(3.4)。具有一個主要版本的R則不是這樣的。
R在資料可視化和資料挖掘方面具有非常好的添加包,Python也是如此。然而,R有大量的添加包可以做同樣的事情,而Python通常專注于向同一個包添加函數。這在可用選項方面是有益的,并且使初學者不易混淆。Python擁有相對較少的添加包(如用于資料挖掘的statsmodels和scikit-learn)。
社群在溝通和互動方面有所不同。R社群使用Twitter上的#rstats進行溝通。請參閱:
https://twitter.com/hashtag/rstats R期刊: https://journal.r-project.org/ Python在Python Papers上有期刊: http://ojs.pythonpapers.org/ 此外還有一個統計軟體期刊Journal of Statistical Software: http://www.jstatsoft.org/index- 為什麼R使用者應該了解有關Python的更多資訊
專業資料科學家不應該依賴于一種統計計算語言來面對他的職業生涯。我們學習一門新語言的難易程度确實會随着年齡的增長而降低,最好将你的職業生涯建立在不僅僅掌握R的基礎上。四十年來,SAS語言确實引領世界,大資料交流分享扣qun 74零零加【4yi381】但在快速變化的世界中,最好不要輕易打賭,R技能是你在十年職業生涯中從事統計計算所需要的。
- 為什麼Python使用者應該了解有關R的更多資訊
R将繼續擁有統計資料科學和可視化中的最大數量的添加包。由于R也是開源和免費的,是以最好在R中進行原型設計,而不是使用Python在生産環境中進行擴充。
一個有趣的觀點在DataCamp建立的kdnuggets上:
http://www.kdnuggets.com/2015/05/r-vs-python-data-science.html和這裡:
http://multithreaded.stitchfix.com/blog/2015/03/17/grammar-of-data-science/09 教程
有關代碼和輸出的Python資料科學的Radim Rehurek筆記本可在這裡找到:
http://radimrehurek.com/data_science_python/GitHub上還提供了适用于Python資料科學的筆記本清單。
https://github.com/donnemartin/data-science-ipython-notebooks有關Python中與資料科學相關的活動的更多常識,請通路:
有關資料科學的更多知識,請參閱:
http://datasciencespecialization.github.io/它擁有約翰霍普金斯大學Coursera資料科學專業的所有九門課程:
資料科學家的工具箱
R程式設計
擷取和清洗資料
探索性資料分析
可重複的研究
統計推斷
回歸模型
實用機器
學習開發資料産品
10 如何将Python和R用于大資料分析
大資料是Hadoop的代名詞。要将Python與Hadoop一起使用,你可以使用以下添加包:
Hadoop Streaming
mrjob
dumbo
hadoopy
pydoop
▲圖1.3 在Jupyter Notebook中使用SAS,資料來源:Chris Hemedinger,SAS研究所SAS Dummy,經SAS Institute Inc.許可轉載
這裡給出了一個例子:
https://blog.cloudera.com/blog/2013/01/a-guide-to-python-frameworks-for-hadoop/最近的一項創新是Apache Arrow,參見:
https://blog.cloudera.com/blog/2016/02/introduction-apache-arrow-a-fast-interoperable-in-memory-columnar-data-structure-standard/文章中提到:“對于Python和R社群,Arrow非常重要,因為資料互操作性是與大資料系統(主要在JVM上運作)更緊密內建的最大障礙之一。”
下一個創新是Feather,參見:
https://blog.rstudio.org/2016/03/29/feather/Feather是一種快速、輕量且易于使用的二進制檔案格式,用于存儲資料框,而Feather檔案無論是用Python還是R代碼編寫都是相同的。Python接口使用Cython向使用者公開Feather的C++11核心,而R接口使用Rcpp執行相同的任務。
11 什麼是雲計算
雲計算的官方定義見:
http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf
雲計算是一種用于提供支援的模型:
在按需網絡通路方面友善、無處不在。
可配置計算資源的共享池(例如,網絡、伺服器、存儲、應用程式和服務),可以通過最少的管理工作或服務提供商互動快速配置和釋出。
亞馬遜(EC2)、谷歌、甲骨文、IBM和Microsoft Azure是雲提供商的一些例子。對于資料科學家來說,了解作為服務的基礎設施、平台和軟體之間的差異非常重要(圖1.4)。

▲圖1.4 作為服務的基礎設施、平台和軟體之間的差別,資料來源:
https://blogs.technet.microsoft.com/kevinremde/2011/04/03/saas-paas-and-iaas-oh-my-cloudy-april-part-3/12 如何在雲上使用Python和R
如果你想在雲中托管和運作Python,這些實作可能适合你:PythonAnywhere(免費增值托管的Python安裝,允許你在浏覽器中運作Python,例如,用于教程、展示等)。它還有一個額外的教育用例。
PythonAnywhere提到,Python是一種很好的教學語言,但在所有學生的計算機上安裝和設定它可能并不容易。PythonAnywhere提供了一個随時可用的環境,包括文法高亮、錯誤檢查編輯器和Python2和3控制台。
https://www.pythonanywhere.com/details/education你可以在雲上使用Python抓取網頁:
http://scrapinghub.com/scrapy-cloud/Scrapy是Python最流行和最先進的Web爬蟲架構。它使編寫Web爬蟲變得快速、簡單和有趣。但是,你仍需要定期部署和運作爬蟲程式,管理伺服器,監控性能,檢視已删除的資料,并在爬蟲中斷時收到通知。這就是Scrapy Cloud的用武之地。
此外,如果你更喜歡使用RStudio接口,可以根據這裡的說明,在雲上運作RStudio Server:
http://www.louisaslett.com/RStudio_AMI/