寫在前面
序列化是一個轉儲-恢複的操作過程,即支援将一個對象轉儲到臨時緩沖或者永久檔案中和恢複臨時緩沖或者永久檔案中的内容到一個對象中等操作,其目的是可以在不同的應用程式之間共享和傳輸資料,以達到跨應用程式、跨語言和跨平台的解耦,以及當應用程式在客戶現場發生異常或者崩潰時可以即時儲存資料結構各内容的值到檔案中,并在發回給開發者時再恢複資料結構各内容的值以協助分析和定位原因。
泛型程式設計是一個對具有相同功能的不同類型的抽象實作過程,比如STL的源碼實作,其支援在編譯期由編譯器自動推導具體類型并生成實作代碼,同時依據具體類型的特定性質或者優化需要支援使用特化或者偏特化及模闆元程式設計等特性進行具體實作。
Hello World
#include <iostream>
int main(int argc, char* argv[])
{
std::cout << "Hello World!" << std::endl;
return 0;
} 泛型程式設計其實就在我們身邊,我們經常使用的std和stl命名空間中的函數和類很多都是泛型程式設計實作的,如上述代碼中的
std::cout
即是模闆類
std::basic_ostream
的一種特化
namespace std
{
typedef basic_ostream<char> ostream;
} 從C++的标準輸入輸出開始
除了上述提到的
std::cout
和
std::basic_ostream
外,C++還提供了各種形式的輸入輸出模闆類,如
std::basic_istream
,
std::basic_ifstream
std::basic_ofstream
std::basic_istringstream
std::basic_ostringstream
等等,其主要實作了内建類型(
built-in
)的輸入輸出接口,比如對于
Hello World
可直接使用于字元串,然而對于自定義類型的輸入輸出,則需要重載實作操作符
>>
<<
,如對于下面的自定義類
class MyClip
{
bool mValid;
int mIn;
int mOut;
std::string mFilePath;
}; 如使用下面的方式則會出現一連串的編譯錯誤
MyClip clip;
std::cout << clip; 錯誤内容大緻都是一些
clip
不支援
<<
操作符并在嘗試将
clip
轉為
cout
支援的一系列的内建類型如
void*
int
等等類型時轉換操作不支援等資訊。
為了解決編譯錯誤,我們則需要将類
MyClip
支援輸入輸出操作符
>>
<<
,類似實作代碼如下
inline std::istream& operator>>(std::istream& st, MyClip& clip)
{
st >> clip.mValid;
st >> clip.mIn >> clip.mOut;
st >> clip.mFilePath;
return st;
}
inline std::ostream& operator<<(std::ostream& st, MyClip const& clip)
{
st << clip.mValid << ' ';
st << clip.mIn << ' ' << clip.mOut << ' ';
st << clip.mFilePath << ' ';
return st;
} 為了能正常通路類對象的私有成員變量,我們還需要在自定義類型裡面增加序列化和反序列化的友元函數(回憶一下這裡為何必須使用友元函數而不能直接重載操作符
>>
<<
?),如
friend std::istream& operator>>(std::istream& st, MyClip& clip);
friend std::ostream& operator<<(std::ostream& st, MyClip const& clip); 這種序列化的實作方法是非常直覺而且容易了解的,但缺陷是對于大型的項目開發中,由于自定義類型的數量較多,可能達到成千上萬個甚至更多時,對于每個類型我們則需要實作2個函數,一個是序列化轉儲資料,另一個則是反序列化恢複資料,不僅僅增加了開發實作的代碼數量,如果後期一旦對部分類的成員變量有所修改,則需要同時修改這2個函數。
同時考慮到更複雜的自定義類型,比如含有繼承關系和自定義類型的成員變量
class MyVideo : public MyClip
{
std::list<MyFilter> mFilters;
}; 上述代碼需要轉儲-恢複類
MyVideo
的對象内容時,事情會變得更複雜些,因為還需要轉儲-恢複基類,同時成員變量使用了STL模闆容器
list
與自定義類'MyFilter`的結合,這種情況也需要自己去定義轉儲-恢複的實作方式。
針對以上疑問,有沒有一種方法能減少我們代碼修改的工作量,同時又易于了解和維護呢?
Boost序列化庫
對于使用C++标準輸入輸出的方法遇到的問題,好在Boost提供了一種良好的解決方式,則是将所有類型的轉儲-恢複操作抽象到一個函數中,易于了解,如對于上述類型,隻需要将上述的2個友元函數替換為下面的一個友元函數
template<typename Archive> friend void serialize(Archive&, MyClip&, unsigned int const); 友元函數的實作類似下面的樣子
template<typename A>void serialize(A &ar, MyClip &clip, unsigned int const ver)
{
ar & BOOST_SERIALIZATION_NVP(clip.mValid);
ar & BOOST_SERIALIZATION_NVP(clip.mIn);
ar & BOOST_SERIALIZATION_NVP(clip.mOut);
ar & BOOST_SERIALIZATION_NVP(clip.mFilePath);
} 其中
BOOST_SERIALIZATION_NVP
是Boost内部定義的一個宏,其主要作用是對各個變量進行打包。
轉儲-恢複的使用則直接作用于操作符
>>
<<
,比如
// store
MyClip clip;
······
std::ostringstream ostr;
boost::archive::text_oarchive oa(ostr);
oa << clip;
// load
std::istringstream istr(ostr.str());
boost::archive::text_iarchive ia(istr);
ia >> clip; 這裡使用的
std::istringstream
std::ostringstream
即是分别從字元串流中恢複資料以及将類對象的資料轉儲到字元串流中。
對于類
MyFilter
MyVideo
則使用相同的方式,即分别增加一個友元模闆函數
serialize
的實作即可,至于
std::list
模闆類,
boost
已經幫我們實作了。
這時我們發現,對于每一個定義的類,我們需要做的僅僅是在類内部聲明一個友元模闆函數,同時類外部實作這個模闆函數即可,對于後期類的成員變量的修改,如增加、删除或者重命名成員變量,也僅僅是修改一個函數即可。
Boost序列化庫已經足夠完美了,但故事并未結束!
在用于端上開發時,我們發現引用Boost序列化庫遇到了幾個挑戰
- 端上的編譯資料很少,官方對端上編譯的資料基本沒有,在切換不同的版本進行編譯時經常會遇到各種奇怪的編譯錯誤問題
- Boost在不同的C++開發标準之間相容性不夠好,尤其是使用libc++标準進行編譯連結時遇到的問題較多
- Boost增加了端上發行包的體積
- Boost每次序列化都會增加序列化庫及版本号等私有頭資訊,反序列化時再重新解析,降低了部分場景下的使用性能
基于泛型程式設計的序列化實作方法
為了解決使用Boost遇到的這些問題,我們覺得有必要重新實作序列化庫,以剝離對Boost的依賴,同時能滿足如下要求
- 由于現有工程大量使用了Boost序列化庫,是以相容現有的代碼以及開發者的習慣是首要目标
- 盡量使得代碼修改和重構的工作量最小
- 相容不同的C++開發标準
- 提供比Boost序列化庫更高的性能
- 降低端上發行包的體積
為了相容現有使用Boost的代碼以及保持目前開發者的習慣,同時使用代碼修改的重構的工作量最小,我們應該保留模闆函數
serialize
,同時對于模闆函數内部的實作,為了提高效率也不需要對各成員變量重新打包,即直接使用如下定義
#define BOOST_SERIALIZATION_NVP(value) value 對于轉儲-恢複的接口調用,仍然延續目前的調用方式,隻是将輸入輸出類修改為
alivc::text_oarchive oa(ostr);
alivc::text_iarchive ia(istr); 好了,到此為止,序列化庫對外的接口工作已經做好,剩下的就是内部的事情,應該如何重新設計和實作序列化庫的内部架構才能滿足要求呢?
先來看一下目前的設計架構的處理流程圖
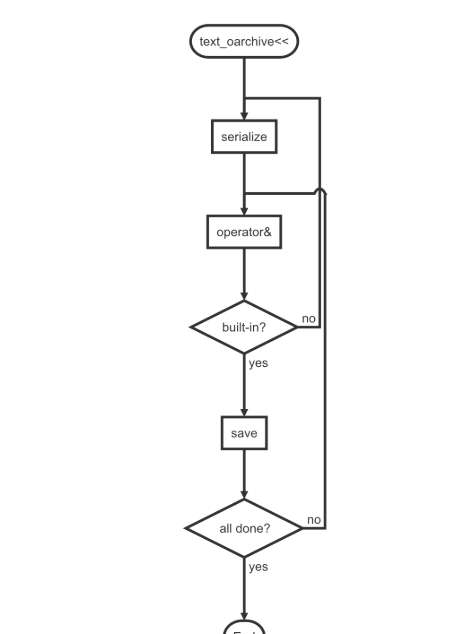
比如對于轉儲類
text_oarchive
,其支援的接口必須包括
explicit text_oarchive(std::ostream& ost, unsigned int version = 0);
template <typename T> text_oarchive& operator<<(T& v);
template <typename T> text_oarchive& operator&(T& v); 開發者調用操作符函數
<<
時,需要首先回調到相應類型的模闆函數
serialize
中
template <typename T>
text_oarchive& operator<<(T& v)
{
serialize(*this, v, mversion);
return *this;
} 當開始對具體類型的各個成員進行操作時,這時需要進行判斷,如果此成員變量的類型已經是内建類型,則直接進行序列化,如果是自定義類型,則需要重新回調到對應類型的模闆函數
serialize
template <typename T>
text_oarchive& operator&(T& v)
{
basic_save<T>::invoke(*this, v, mversion);
return *this;
} 上述代碼中的basic_save::invoke則會在編譯期完成模闆類型推導并選擇直接對内建類型進行轉儲還是重新回調到成員變量對應類型的
serialize
函數繼續重複上述過程。
由于内建類型數量有限,是以這裡我們選擇使模闆類basic_save的預設行為為回調到相應類型的
serialize
函數中
template <typename T, bool E = false>
struct basic_load_save
{
template <typename A>
static void invoke(A& ar, T& v, unsigned int version)
{
serialize(ar, v, version);
}
};
template <typename T>
struct basic_save : public basic_load_save<T, std::is_enum<T>::value>
{
}; 這時會發現上述代碼的模闆參數多了一個參數
E
,這裡主要是需要對枚舉類型進行特殊處理,使用偏特化的實作如下
template <typename T>
struct basic_load_save<T, true>
{
template <typename A>
static void invoke(A& ar, T& v, unsigned int version)
{
int tmp = v;
ar & tmp;
v = (T)tmp;
}
}; 到這裡我們已經完成了重載操作符
&
的預設行為,即是不斷進行回溯到相應的成員變量的類型中的模闆函數
serialize
中,但對于碰到内模組化型時,我們則需要讓這個回溯過程停止,比如對于
int
類型
template <typename T>
struct basic_pod_save
{
template <typename A>
static void invoke(A& ar, T const& v, unsigned int)
{
ar.template save(v);
}
};
template <>
struct basic_save<int> : public basic_pod_save<int>
{
}; 這裡對于
int
類型,則直接轉儲整數值到輸出流中,此時
text_oarchive
則還需要增加一個終極轉儲函數
template <typename T>
void save(T const& v)
{
most << v << ' ';
} 這裡我們發現,在
save
成員函數中,我們已經将具體的成員變量的值輸出到流中了。
對于其它的内建類型,則使用相同的方式處理,要以參考C++
std::basic_ostream
的源碼實作。
相應的,對于恢複操作的
text_iarchive
的操作流程如下圖

測試結果
我們對使用
Boost
以及重新實作的序列化庫進行了對比測試,其結果如下
- 代碼修改的重構的工作非常小,隻需要删除
Boost
boost
alivc
BOOST_SERIALIZATION_FUNCTION
BOOST_SERIALIZATION_NVP
- Android端下的發行包體積大概減少了500KB
- 目前的消息處理架構中,處理一次消息的平均時間由100us降低到了25us
- 代碼實作約300行,更輕量級
未來還能做什麼
由于目前項目的原因,重新實作的序列化還沒有支援轉儲-恢複指針所指向的記憶體資料,但目前的設計架構已經考慮了這種拓展性,未來會考慮支援。
總結
- 泛型程式設計能夠大幅提高開發效率,尤其是在代碼重用方面能發揮其優勢,同時由于其類型推導及生成代碼均在編譯期完成,并不會降低性能
- 序列化對于需要進行轉儲-恢複的解耦處理以及協助定位異常和崩潰的原因分析具有重要作用
- 利用C++及模闆自身的語言特性優勢,結合合理的架構設計,即易于拓展又能盡量避免過度設計