1.前言
基于時間線一緻的高可用讀(Timeline-consistent High Available Reads),又稱 Region replica。其實早在 HBase-1.2 版本的時候,這個功能就已經開發完畢了, 但是還是不太穩定,離生産可用級别還有一段距離,後來社群又陸陸續續修複了 一些 bug,比如說 HBASE-18223。這些 bug 很多在 HBase-1.4 之後的版本才修 複,也就是說 region replica 功能基本上在 HBase-1.4 之後才穩定下來。介于 HBase-1.4 版本目前實際生産中使用的還比較少,把 region replica 功能說成是 HBase2.0 中的新功能也不為過。
2.為什麼需要 Region Replica
在 CAP 理論中,HBase 一直是一個 CP(Consistency&Partition tolerance)系統。 HBase 一直以來都在遵循着讀寫強一緻的語義。是以說雖然在存儲層,HBase 依 賴 HDFS 實作了資料的多副本,但是在計算層,HBase 的 region 隻能在一台 RegionServer 上線提供讀寫服務,來保持強一緻。如果這台伺服器發生當機時, Region 需要從 WAL 中恢複還緩存在 memstore 中未刷寫成檔案的資料,才能重新上線服務。
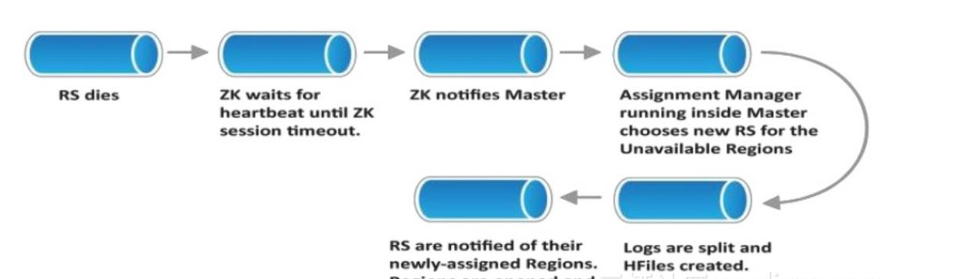
由于 HBase 的 RegionServer 是使用 Zookeeper 與 Master 保持 lease。而為了不讓 JVM GC 停頓導緻 RegionServer 被 master“誤判”死亡,這個 lease 時間通常都 會設定為 20~30s,如果 RegionServer 使用的 Heap 比較大時,這個 lease 可能還 會設的更長。加上當機後,region 需要 re-assign,WAL 可能需要 recoverlease 和被 replay 操作,一個典型的 region 當機恢複時間可能長達一分鐘!這就意味着在這一分鐘内,這個 region 都無法被讀寫。
由于 HBase 是一個分布式系統, 同一張表的資料可能分布在非常多的 RegionServer 和 region 裡。如果這是一個大 HBase 叢集,有 100 台 RegionServer 機器,那麼當機一台的話,可能隻有 1% 的使用者資料被影響了。但是如果這是小使用者的 HBase 叢集,一共就隻有 2 台
RegionServer,當機一台意味着 50%的使用者資料都在 1~2 分鐘之内無法服務,這是很多使用者都無法忍受的。
其實,很大一部分使用者對讀可用性的需求,可能比讀強一緻的需求還要高。在故 障場景下,隻要保證讀繼續可用,“stale read”,即讀到之前的資料也可以接受。 這就是為什麼我們需要 read replica 這個功能。
3.Region Replica 技術細節
Region replica 的本質,就是讓同一個 region host 在多個 regionserver 上。原來的 region,稱為 Default Replica(主 region),提供了與之前類似的強一緻讀寫體驗。而與此同時,根據配置的多少,會有一個或者多個 region 的副本,統稱為 region replica,在另外的 RegionServer 上被打開。并且由 Master 中的 LoadBalancer 來保證 region 和他們的副本,不會在同一個 RegionServer 打開,防止一台伺服器的當機導緻多個副本同時挂掉。

Region Replica 的設計巧妙之處在于,額外的 region 副本并不意味着資料又會多出幾個副本。這些 region replica 在 RegionServer 上 open 時,使用的是和主 region 相同的 HDFS 目錄。也就是說主 region 裡有多少 HFile,那麼在 region replica 中,這些資料都是可見的,都是可以讀出來的。region replica 相對于主 region,有一些明顯的不同。
首先,region replica 是不可寫的。這其實很容易了解,如果 region replica 也可以寫的話,那麼同一個 region 會在多個 regionserver 上被寫入,連主 region 上的強一緻讀寫都沒法保證了。
再次,region replica 是不能被 split 和 merge 的。region replica 是主 region 的附 屬品,任何發向 region replica 的 split 和 merge 請求都會被拒絕掉。隻有當主 region split/merge 時,才會把這些 region replica 從 meta 表中删掉,建立新生 成 region 的 region 的 replica。
4.replica 之間的資料同步
那麼,既然 region replica 不能接受寫,它打開之後,怎麼讓新寫入的資料變的 可見呢?這裡,region replica 有兩種更新資料的方案:
4.1. 定期的 StoreFile Refresher
這個方案非常好了解,region replica 定期檢查一下它自己對應的 HDFS 目錄,如果發現檔案有變動,比如說 flush 下來新的檔案,檔案被 compaction 掉,它就刷 新一下自己的檔案清單,這個過程非常像 compaction 完成之後删除被 compact 掉的檔案和加入新的檔案的流程。StoreFile Refresher 方案非常簡單,隻需要在 RegionServer 中起一個定時執行的 Chroe,定期去檢查一下它上面的 region 哪
些是 region replica,哪些到了設定好的重新整理周期,然後重新整理就可以了。但這個方案缺點也十分明顯,主 region 寫入的資料,隻有當 flush 下來後,才能被 region replica 看到。而且 storeFile Refresher 本身還有一個重新整理的周期,設的太短了, list 檔案清單對 NN 的沖擊太頻繁,設的太長,就會造成資料長時間在 region replica 中都不可見
4.2. Internal Replication
我們知道,HBase 是有 replication 鍊路的,支援把一個 HBase 叢集的資料通過 replication 複制到另外一個叢集。那麼,同樣的原理,可以在 HBase 叢集内部建立一條 replication 通道,把一個 Server 上的主 region 的資料,複制到另一個 Server 的 region replica 上。那麼 region replica 接收到這些資料之後,會把他們寫入 memstore 中。對,你沒看錯,剛才我說了 region replica 是不接受寫的,這是指 replica 不接受來自用戶端的寫,如果來自主 region 的 replication 的資料, 它還是會寫入 memstore 的。但是,這個寫和普通的寫有很明顯的差別。第一個,replica region 在寫入來自主 region 的時候,是不寫 WAL 的,因為這些資料已經 在主 region 所在的 WAL 中持久化了,replica 中無需再次落盤。第二個,replica region 的 memstore 中的資料是不會被 flush 成 HFile。我們知道,HBase 的 replication 是基于複制 WAL 檔案實作的,那麼在主 region 進行 flush 時,也會寫入特殊的标記 Flush Marker。當 region replica 收到這樣的标記時,就直接會把所 有 memstore 裡的資料丢掉,再做一次 HDFS 目錄的重新整理,把主 region 剛剛刷下 去的那個 HFile include 進來。同樣,如果主 region 發生了 compaction,也會寫入相應的 Compaction Marker。讀到這樣的标記後,replica region 也會做類似的動作。
Internal replication 加快了資料在 region replica 中的可見速度。通過 replication 方案,隻要 replication 本身不發生阻塞和延遲,region replica 中的資料可以做到 和主 region 隻差幾百 ms。但是,replication 方案本身也存在幾個問題:
- META 表 無法通過 replication 來同步資料。如果給 meta 表開了 region replica 功能,meta 表主 region 和 replica 之間的資料同步,隻能通過定 期的 StoreFile Refresher 機制。因為 HBase 的 replication 機制中會過濾 掉 meta 表的資料。
- 需要消耗額外的 CPU 和網絡帶寬來做 Replication。由于 region replica 的資料同步需要,需要在 HBase 叢集内部建立 replication 通道,而且有幾個 replica,就意味着需要從主 region 發送幾份資料。這會增加 RegionServer 的 CPU 使用,同時在 server 之間複制資料還需要占用帶寬
- 寫 memstore 需要額外的記憶體開銷。為了讓 replica region 的資料缺失的内容盡量的少,主 region 的資料會通過 replication 發送到 replica 中,這些資料都會儲存在 memstore 中。也就是說同樣的一份資料,會同時存在主region 的 memstore 中,也會存在 replica region 的 memstore 中。replica 的數量是幾,那麼 memstore 的記憶體使用量就是幾倍。
下面的兩個問題雖然可以通過配置一些參數解決,但是列在這裡,仍然需要注意, 因為一旦參數沒有配對,就會産生這樣的問題。
- 在 replica region failover 後,讀到的資料可能會回退。我們假設一個情 況。用戶端寫入 X=1,主 region 發生 flush,X=1 刷在了 HFile 中,然後客 戶端繼續寫入 X=2,X=3,那麼在主 region 的 memstore 中 X=3。同時,通過 replication,X=2,X=3 也被複制到了 replica region 的 memstore 中。如 果用戶端去 replica 中去讀取 X 的資料,也能讀到 3。但是由于 replica region memstore 中的資料是不寫 WAL 的,也不刷盤。那麼當 replica 所在 的機器當機後,它是沒有任何資料恢複流程的,他會直接在其他 RegionServer 上線。上線後它隻能讀取 HFile,無法感覺主 region memstore 裡的資料。這時如果用戶端來 replica 上讀取資料,那麼他隻會讀到 HFile 中的 X=1。也就是說之前用戶端可以讀到 X=3,但後來卻隻能讀到 X=1 了, 資料出現了回退。為了避免出現這樣的問題,可以配置一個 hbase.region.replica.wait.for.primary.flush=true 的參數,配置之後, replica region 上線後,會被标記為不可讀,同時它會去觸發一次主 region 的 flush 操作。隻有收到主 region 的 flush marker 之後,replica 才把自 己标記為可讀,防止讀回退
-
replica memstore 過大導緻寫阻塞。上面說過,replica 的 region 中 memstore 是不會主動 flush 的,隻有收到主 region 的 flush 操作,才會去 flush。同一台 RegionServer 上可能有一些 region replica 和其他的主 region 同時存在。這些 replica 可能由于複制延遲(沒有收到 flush marker), 或者主 region 沒有發生 flush,導緻一直占用記憶體不釋放。這會造成整體 的記憶體超過水位線,導緻正常的寫入被阻塞。為了防止這個問題的出現, HBase 中 有 一 個 參 數 叫 做
hbase.region.replica.storefile.refresh.memstore.multiplier,預設值是 4。這個參數的意思是說,如果最大的 replica region 的 memstore 已經 超過了最大的主region memstore的記憶體的4倍,就主動觸發一次StoreFile Refresher 去更新檔案清單,如果确實發生了 flush,那麼 replica 記憶體裡 的資料就能被釋放掉。但是,這隻是解決了 replication 延遲導緻的未 flush 問題,如果這個 replica 的主 region 确實沒有 flush 過,記憶體還是不能被釋放。寫入阻塞還是會存在。
5.Timeline Consistency Read
無論是 StoreFile Refresher 還是 Internal replication,主 region 和 replica 之間的資料更新都是異步的,這就導緻在 replica region 中讀取資料時,都不是強一緻的。read replica 的作者把從 region replica 中讀資料的一緻性等級定為 Timeline Consistency。隻有使用者明确表示能夠接受 Timeline consistency,用戶端的請求才會發往 replica 中。
比如說上圖中,如果用戶端是需要強一緻讀,那麼用戶端的請求隻會發往主 region,即 replica_id=0 的 region,他就會讀到 X=3.如果他選擇了 Timeline consistency 讀,那麼根據配置,他的讀可能落在主上,那麼他仍然會讀到 X=3, 如果他的讀落在了 replica_id=1 的 region 上,因為複制延遲的存在,他就隻能讀 到 X=2.如果落在了 replica_id=2 上,由于 replication 鍊路出現了問題,他就隻能 讀到 X=1。
6.Region replica 的使用方法
6.1 服務端配置
hbase.regionserver.storefile.refresh.period
如果要使用 StoreFile Refresher 來做為 Region replica 之間同步資料的政策,就 必須把這個值設定為一個大于 0 的數,即重新整理 storefile 的間隔周期(機關為 ms) 上面的章節講過,這個值要不能太大,也不能太小。
hbase.regionserver.meta.storefile.refresh.period
由于 Meta 表的 region replica 不能通過 replication 來同步,是以如果要開啟 meta 表的 region replica,必須把這個參數設成一個不為 0 的值,具體作用參見上一個參數,這個參數隻對 meta 表生效。
hbase.region.replica.replication.enabled
hbase.region.replica.replication.memstore.enabled
如果要使用 Internal replication 的方式在 Region replica 之間同步資料的政策, 必須把這兩個參數都設定為 true
hbase.master.hfilecleaner.ttl
在主 region 發生 compaction 之後,被 compact 掉的檔案會放入 Achieve 檔案夾内,超過 hbase.master.hfilecleaner.ttl 時間後,檔案就會被從 HDFS 删除掉。而此時,可能 replica region 正在讀取這個檔案,這會造成使用者的讀取抛錯傳回。 如果不想要這種情況發生,就可以把這個參數設為一個很大的值,比如說 3600000(一小時),總沒有讀操作需要讀一個小時了吧?
hbase.meta.replica.count
mata 表的 replica 份數,預設為 1,即不開啟 meta 表的 replica。如果想讓 meta表有額外的一個 replica,就可以把這個值設為 2,依次類推。此參數隻影響 meta 表的 replica 份數。使用者表的 replica 份數是在表級别配置的,這個我後面會講
hbase.region.replica.storefile.refresh.memstore.multiplier
這個參數我在上面的章節裡有講,預設為 4
hbase.region.replica.wait.for.primary.flush
這個參數我在上面的章節裡有講,預設為 true
需要注意的是,開啟 region replica 之後,Master 的 balancer 一定要用預設的 StochasticLoadBalancer,隻有這個 balancer 會盡量使主 region 和他的 replica 不在同一台機器上。其他的 balaner 會無差別對待所有的 region。
6.2 用戶端配置
hbase.ipc.client.specificThreadForWriting
因為當存在 region replica 時,當用戶端發往主 region 的請求逾時後,會發起一個請求到 replica region,當其中一個請求放回後,就無需再等待另一個請求的結果了,通常要中斷這個請求,使用專門的的線程來發送請求,比較容易進行中斷。 是以如果要使用 region replica,這個參數要配為 true。
hbase.client.primaryCallTimeout.get
hbase.client.primaryCallTimeout.multiget
hbase.client.replicaCallTimeout.scan
分别對應着,get、multiget、scan 時等待主 region 傳回結果的時間。如果把這 個值設為 1000ms,那麼用戶端的請求在發往主 region 超過 1000ms 還沒傳回後, 就會再發一個請求到 replica region(如果有多個 replica 的話,就會同時發往多個 replica)
hbase.meta.replicas.use
如果服務端上開啟了 meta 表的 replica 後,用戶端可以使用這個參數來控制是否使用 meta 表的 replica 的 region。
6.3 建表
在 shell 建表時
create 't1', 'f1', {REGION_REPLICATION => 2}
Replica 的份數支援動态修改,但修改之前必須 disable 表
diable 't1'
alter 't1', {REGION_REPLICATION => 1}
enable 't1'
6.4 通路有 replica 的表
如果可以按請求設定一緻性級别,如果把請求的一緻性級别設為 Consistency.TIMELINE,即有可能讀到 replica 上
另外,使用者可以通過 Result.isStale()方法來獲得傳回的 result 是否來自主 region,
如果為 isStale 為 false,則結果來自主 region。
7.總結和建議
Region Replica 功能給 HBase 使用者帶來了高可用的讀能力,提高了 HBase 的可用 性,但同時也存在一定的缺點:
- 高可用的讀基于 Timeline consistency,使用者需要接受非強一緻性讀才能 開啟這個功能
- 使用 Replication 來做資料同步意味着額外的 CPU,帶寬消耗,同時根據 replica 的多少,可能會有數倍的 memstore 記憶體消耗
- 讀取 replica region 中的 block 同樣會進 block cache(如果表開啟了 block cache 的話),這意味着數倍的 cache 開銷
- 用戶端 Timeline consistency 讀可能會把請求發往多個 replica,可能帶 來更多的網絡開銷
Region Replica 隻帶來了高可用的讀,當機情況下的寫,仍然取決于主 region 的 恢複時間,是以 MTTR 時間并沒有随着使用 Region replica 而改善。雖然說 region replica 的作者在規劃中有寫計劃在當機時把一個 replica 提升為主,來優化 MTTR 時間,但截至目前為止,還沒有實作。
個人建議,region replica 功能适合于使用者叢集規模較小,對讀可用性非常在意, 同時又可以接受非強一緻性讀的情況下開啟。如果叢集規模較大,或者讀寫流量 非常大的叢集上開啟此功能,需要留意記憶體使用和網絡帶寬。Memstore 占用内 存過高可能會導緻 region 頻繁刷盤,影響寫性能,同時 cache 容量的翻倍會導 緻一部分讀請求擊穿 cache 直接落盤,導緻讀性能的下降。
作者:楊文龍 阿裡巴巴 技術專家 HBase Committer&HBase PMC