1.背景
**
1.1 對接業務類型**
HBase 是建立在 Hadoop 生态之上的 Database,源生對離線任務支援友好,又因為 LSM 樹是一個優秀的高吞吐資料庫結構,是以同時也對接了很多線上業務。 線上業務對通路延遲敏感,并且通路趨向于随機,如訂單、客服軌迹查詢。離線 業務通常是數倉的定時大批量處理任務,對一段時間内的資料進行處理并産出結果,對任務完成的時間要求不是非常敏感,并且處理邏輯複雜,如天級别報表、 安全和使用者行為分析、模型訓練等。
1.2 多語言支援
HBase 提供了多語言解決方案,并且由于滴滴各業務線 RD 所使用的開發語言各 有偏好,是以多語言支援對于 HBase 在滴滴内部的發展是至關重要的一部分。我 們對使用者提供了多種語言的通路方式:HBase Java native API、Thrift Server(主 要應用于 C++、PHP、Python)、JAVA JDBC(Phoenix JDBC)、Phoenix QueryServer (Phoenix 對外提供的多語言解決方案)、MapReduce Job(Htable/Hfile Input)、 Spark Job、Streaming 等。
1.3 資料類型**
HBase 在滴滴主要存放了以下四種資料類型:
- 統計結果、報表類資料:主要是營運、運力情況、收入等結果,通常需要配合 Phoenix 進行 SQL 查詢。資料量較小,對查詢的靈活性要求高,延遲要求一般。
- 原始事實類資料:如訂單、司機乘客的 GPS 軌迹、日志等,主要用作線上和離線的資料供給。資料量大,對一緻性和可用性要求高,延遲敏感,實時寫入,單點或批量查詢。
- 中間結果資料:指模型訓練所需要的資料等。資料量大,可用性和一緻性要求一般,對批量查詢時的吞吐量要求高。
- 線上系統的備份資料:使用者把原始資料存在了其他關系資料庫或檔案服務, 把 HBase 作為一個異地容災的方案。
2. 使用場景介紹
2.1 場景一:訂單事件
這份資料使用過滴滴産品的使用者應該都接觸過,就是 App 上的曆史訂單。近期 訂單的查詢會落在 Redis,超過一定時間範圍或者當 Redis 不可用時,查詢會落在 HBase 上。業務方的需求如下:
- 線上查詢訂單生命周期的各個狀态,包括 status、event_type、order_detail 等資訊。主要的查詢來自于客服系統。
- 線上曆史訂單詳情查詢。上層會有 Redis 來存儲近期的訂單,當 Redis 不可用或者查詢範圍超出 Redis,查詢會直接落到 HBase。
- 離線對訂單的狀态進行分析。
- 寫入滿足每秒 10K 的事件,讀取滿足每秒 1K 的事件,資料要求在 5s 内可用。
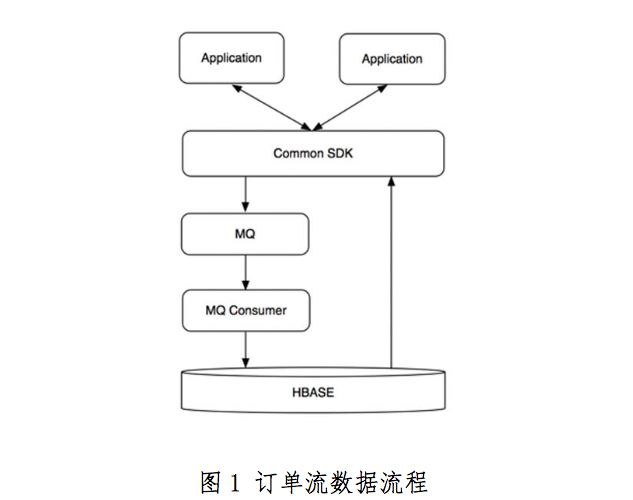
按照這些要求,我們對 Rowkey 做出了下面的設計,都是很典型的 scan 場景。
訂單狀态表
Rowkey:reverse(order_id) + (MAX_LONG - TS) Columns:該訂單各種狀态
訂單曆史表
Rowkey:reverse(passenger_id | driver_id) + (MAX_LONG - TS) Columns:使用者在時間範圍内的訂單及其他資訊
2.2 場景二:司機乘客軌迹
這也是一份滴滴使用者關系密切的資料,線上使用者、滴滴的各個業務線和分析人員都會使用。舉幾個使用場景上的例子:使用者檢視曆史訂單時,地圖上顯示所經過的路線;發生司乘糾紛,客服調用訂單軌迹複現場景;地圖部門使用者分析道路擁堵情況。

使用者們提出的需求:
- 滿足 App 使用者或者後端分析人員的實時或準實時軌迹坐标查詢;
- 滿足離線大規模的軌迹分析;
- 滿足給出一個指定的地理範圍,取出範圍内所有使用者的軌迹或範圍内出現過的使用者。
其中,關于第三個需求,地理位置查詢,我們知道 MongoDB 對于這種地理索引有源生的支援,但是在滴滴這種量級的情況下可能會發生存儲瓶頸,HBase 存儲 和擴充性上沒有壓力但是沒有内置類MongoDB 地理位置索引的功能,沒有就需要我們自己實作。通過調研,了解到關于地理索引有一套比較通用的 GeohHash 算法 。
GeoHash 是将二維的經緯度轉換成字元串,每一個字元串代表了某一矩形區域。 也就是說,這個矩形區域内所有的點(經緯度坐标)都共享相同的 GeoHash 字元串,比如說我在悠唐酒店,我的一個朋友在旁邊的悠唐購物廣場,我們的經緯 度點會得到相同的 GeoHash 串。這樣既可以保護隐私(隻表示大概區域位置而 不是具體的點),又比較容易做緩存。
但是我們要查詢的範圍和 GeohHash 塊可能不會完全重合。以圓形為例,查詢時會出現如圖 4 所示的一半在 GeoHash 塊内,一半在外面的情況(如 A、B、C、 D、E、F、G 等點)。這種情況就需要對 GeoHash 塊内每個真實的 GPS 點進行第 二次的過濾,通過原始的 GPS 點和圓心之間的距離,過濾掉不符合查詢條件的資料。
最後依據這個原理,把 GeoHash 和其他一些需要被索引的次元拼裝成 Rowkey, 真實的 GPS 點為 Value,在這個基礎上封裝成用戶端,并且在用戶端内部對查詢 邏輯和查詢政策做出速度上的大幅優化,這樣就把 HBase 變成了一個 MongoDB 一樣支援地理位置索引的資料庫。如果查詢範圍非常大(比如進行省級别的分析), 還額外提供了 MR 的擷取資料的入口。
兩種查詢場景的 Rowkey 設計如下:
- 單個使用者按訂單或時間段查詢: reverse(user_id) + (Integer.MAX_LONG- TS/1000)
- 給定範圍内的軌迹查詢:reverse(geohash) + ts/1000 + user_id
2.3 場景三:ETA
ETA 是指每次選好起始和目的地後,提示出的預估時間和價格。提示的預估到達 時間和價格,最初版本是離線方式運作,後來改版通過 HBase 實作實時效果,把 HBase 當成一個 KeyValue 緩存,帶來了減少訓練時間、可多城市并行、減少人工幹預的好處。
整個 ETA 的過程如下:
- 模型訓練通過 Spark Job,每 30 分鐘對各個城市訓練一次;
- 模型訓練第一階段,在 5 分鐘内,按照設定條件從 HBase 讀取所有城市資料;
- 模型訓練第二階段在 25 分鐘内完成 ETA 的計算;
- HBase 中的資料每隔一段時間會持久化至 HDFS 中,供新模型測試和新的特征提取。
Rowkey:salting+cited+type0+type1+type2+TS
Column:order, feature
2.4 場景四:監控工具 DCM**
用于監控 Hadoop 叢集的資源使用(Namenode,Yarn container 使用等),關系 資料庫在時間次元過程以後會産生各種性能問題,同時我們又希望可以通過 SQL 做一些分析查詢,是以使用 Phoenix,使用采集程式定時錄入資料,生産成報表, 存入 HBase,可以在秒級别傳回查詢結果,最後在前端做展示。
圖 7、圖 8、圖 9 是幾張監控工具的使用者 UI,數字相關的部分做了模糊處理。
3. 滴滴在 HBase 對多租戶的管理
我們認為單叢集多租戶是最高效和節省精力的方案,但是由于 HBase 對多租戶基本沒有管理,使用上會遇到很多問題:在使用者方面比如對資源使用情況不做分 析、存儲總量發生變化後不做調整和通知、項目上線下線沒有計劃、想要最多的 資源和權限等;我們平台管理者也會遇到比如線上溝通難以了解使用者的業務、對 每個接入 HBase 的項目狀态不清楚、不能判斷出使用者的需求是否合理、多租戶在 叢集上發生資源競争、問題定位和排查時間長等。
針對這些問題,我們開發了 DHS 系統(Didi HBase Service)進行項目管理,并且在 HBase 上通過 Namespace、RS Group 等技術來分割使用者的資源、資料和權 限。通過計算開銷并計費的方法來管控資源配置設定。
DHS 主要有下面幾個子產品和功能:
- 項目生命周期管理:包括立項、資源預估和申請、項目需求調整、需求讨論; 2. 使用者管理:權限管理,項目審批;
- 叢集資源管理;
- 表級别的使用情況監控:主要是讀寫監控、memstore、blockcache、locality。
當使用者有使用 HBase 存儲的需求,我們會讓使用者在 DHS 上注冊項目。介紹業務 的場景和産品相關的細節,以及是否有高 SLA 要求。
之後是建立表以及對表性能需求預估,我們要求使用者對自己要使用的資源有一個準确的預估。如果使用者難以估計,我們會以線上或者線下讨論的方式與使用者讨論 幫助确定這些資訊。然後會生成項目概覽頁面,友善管理者和使用者進行項目進展的跟蹤。
HBase 自帶的 jxm 資訊會彙總到 Region 和 RegionServer 級别的資料,管理者會 經常用到,但是使用者卻很少關注這個級别。根據這種情況我們開發了 HBase 表級别的監控,并且會有權限控制,讓業務 RD 隻能看到和自己相關的表,清楚自己項目表的吞吐及存儲占用情況。
通過 DHS 讓使用者明确自己使用資源情況的基礎之上,我們使用了 RS Group 技術,把一個叢集分成多個邏輯子叢集,可以讓使用者選擇獨占或者共享資源。共享和獨占各有自己的優缺點,如表 1。
根據以上的情況,我們在資源配置設定上會根據業務的特性來選擇不同方案:
- 對于通路延遲要求低、通路量小、可用性要求低、備份或者測試階段的資料: 使用共享資源池;
-
對于延遲敏感、吞吐要求高、高峰時段通路量大、可用性要求高、線上業務: 讓其獨占一定機器數量構成的 RegionServer Group 資源,并且按使用者預估 的資源量,額外給出 20%~30%的餘量。
最後我們會根據使用者對資源的使用,定期計算開銷并向使用者發出賬單。
4. RS Group
RegionServer Group,實作細節可以參照 HBase HBASE-6721 這個 Patch。滴滴在這個基礎上作了一些配置設定政策上的優化,以便适合滴滴業務場景的修改。RS Group 簡單概括是指通過配置設定一批指定的 RegionServer 清單,成為一個 RS Group, 每個 Group 可以按需挂載不同的表,并且當 Group 内的表發生異常後,Region 不會遷移到其他的 Group。這樣,每個 Group 就相當于一個邏輯上的子叢集,通 過這種方式達到資源隔離的效果,降低管理成本,不必為每個高 SLA 的業務線單獨搭叢集。
5. 總結
在滴滴推廣和實踐 HBase 的工作中,我們認為至關重要的兩點是幫助使用者做出 良好的表結構設計和資源的控制。有了這兩個前提之後,後續出現問題的機率會大大降低。良好的表結構設計需要使用者對 HBase 的實作有一個清晰的認識,大多 數業務使用者把更多精力放在了業務邏輯上,對架構實作知之甚少,這就需要平台管理者去不斷幫助和引導,有了好的開端和成功案例後,通過這些使用者再去向其他的業務方推廣。資源隔離控制則幫助我們有效減少叢集的數量,降低運維成本, 讓平台管理者從多叢集無止盡的管理工作中解放出來,将更多精力投入到元件社群跟進和平台管理系統的研發工作中,使業務和平台都進入一個良性循環,提升使用者的使用體驗,更好地支援公司業務的發展。