前言
“手把手教你”系列将為Python初學者一一介紹Python在量化金融中運用最廣泛的幾個庫(Library): NumPy(數組、線性代數)、SciPy(統計)、pandas(時間序列、資料分析)、matplotlib(可視化分析)。建議安裝Anaconda軟體(自帶上述常見庫),并使用Jupyter Notebook互動學習。
Pandas的資料結構類型:
Series (序列:一維清單)
DataFrame (資料框:二維表)
-
Series
定義:資料表中的一列或一行,觀測向量為一維數組,對于任意一組個體某一屬性的觀測可抽象為Series的概念。Series預設由index和values構成。
import pandas as pd
import numpy as np 1.1 Series的建立
建立Series 建立一個Series的基本格式是s = Series(data, index=index, name=name)
np.random.seed(1) #使用随機種子,這樣每次運作random結果一緻,
A=np.random.randn(5)
print("A is an array:\n",A)
S = pd.Series(A)
print("S is a Series:\n",S)
print("index: ", S.index) #預設建立索引,注意是從0開始
print("values: ", S.values)
A is an array:
[ 1.62434536 -0.61175641 -0.52817175 -1.07296862 0.86540763]
S is a Series:
0 1.624345
1 -0.611756
2 -0.528172
3 -1.072969
4 0.865408
dtype: float64
index: RangeIndex(start=0, stop=5, step=1)
values: [ 1.62434536 -0.61175641 -0.52817175 -1.07296862 0.86540763] 可以在建立Series時添加index,并可使用Series.index檢視具體的index。需要注意的一點是,
當從數組建立Series時,若指定index,那麼index長度要和data的
長度一緻
np.random.seed(2)
s=Series(np.random.randn(5),index=['a','b','c','d','e'])
print (s)
s.index
a -0.416758
b -0.056267
c -2.136196
d 1.640271
e -1.793436
dtype: float64
Index(['a', 'b', 'c', 'd', 'e'], dtype='object') 通過字典(dict)來建立Series。
stocks={'中國平安':'601318','格力電器':'000651','招商銀行':'600036',
'中信證券':'600030','貴州茅台':'600519'}
Series_stocks = Series(stocks)
print (s)
中國平安 601318
格力電器 000651
招商銀行 600036
中信證券 600030
貴州茅台 600519
dtype: object 使用字典建立Series時指定index的情形(index長度不必和字典相同)。
Series(stocks, index=['中國平安', '格力電器', '招商銀行', '中信證券',
'工業富聯'])
#注意,在原來的stocks(dict)裡沒有‘工業富聯’,是以值為‘NaN’
中國平安 601318
格力電器 000651
招商銀行 600036
中信證券 600030
工業富聯 NaN
dtype: object 給資料序列和index命名:
Series_stocks.name='股票代碼' #注意python是使用.号來連接配接和調用
Series_stocks.index.name='股票名稱'
print(Series_stocks)
股票名稱
中國平安 601318
格力電器 000651
招商銀行 600036
中信證券 600030
貴州茅台 600519
Name: 股票代碼, dtype: object 1.2 Series資料的通路
Series對象的下标運算同時支援位置和标簽兩種方式
np.random.seed(3)
data=np.random.randn(5)
s = Series(data,index=['a', 'b', 'c', 'd', 'e'])
s
a 1.624345
b -0.611756
c -0.528172
d -1.072969
e 0.865408
dtype: float64
s[:2] #取出第0、1行資料
a -0.670228
b 0.488043
dtype: float64
s[[2,0,4]] #取出第2、0、4行資料
c -0.528172
a 1.624345
e 0.865408
dtype: float64
s[['e', 'a']] #取出‘e’、‘a’對應資料
e 0.865408
a 1.624345
dtype: float64 1.3 Series排序函數
np.random.seed(3)
data=np.random.randn(10)
s = Series(data,index=['j','a', 'c','b', 'd', 'e','h','f','g','i'])
s
j 1.788628
a 0.436510
c 0.096497
b -1.863493
d -0.277388
e -0.354759
h -0.082741
f -0.627001
g -0.043818
i -0.477218
dtype: float64
#排序
s.sort_index(ascending=True) #按index從小到大,False從大到小
a 0.436510
b -1.863493
c 0.096497
d -0.277388
e -0.354759
f -0.627001
g -0.043818
h -0.082741
i -0.477218
j 1.788628
dtype: float64
s.sort_values(ascending=True)
b -1.863493
f -0.627001
i -0.477218
e -0.354759
d -0.277388
h -0.082741
g -0.043818
c 0.096497
a 0.436510
j 1.788628
dtype: float64
s.rank(method='average',ascending=True,axis=0) #每個數的平均排名
j 10.0
a 9.0
c 8.0
b 1.0
d 5.0
e 4.0
h 6.0
f 2.0
g 7.0
i 3.0
dtype: float64
#傳回含有最大值的索引位置:
print(s.idxmax())
#傳回含有最小值的索引位置:
print(s.idxmin())
j
b 根據索引傳回已排序的新對象:
Series.sort_index(ascending=True)
根據值傳回已排序的對象,NaN值在末尾:
Series.sort_values(ascending=True)
為各組配置設定一個平均排名:
Series.rank(method='average',ascending=True,axis=0)
rank的method選項:
'average':在相等分組中,為各個值配置設定平均排名
'max','min':使用整個分組中的最小排名
'first':按值在原始資料中出現的順序排名
傳回含有最大值的索引位置:
Series.idxmax()
傳回含有最小值的索引位置:
Series.idxmin()
2 Pandas資料結構:DataFrame
DataFrame是一個二維的資料結構,通過資料組,index和columns構成
2.1 DataFrame資料表的建立
DataFrame是多個Series的集合體。
先建立一個值是Series的字典,并轉換為DataFrame。
#通過字典建立DataFrame
d={'one':pd.Series([1.,2.,3.],index=['a','b','c']),
'two':pd.Series([1.,2.,3.,4.,],index=['a','b','c','d']),
'three':range(4),
'four':1.,
'five':'f'}
df=pd.DataFrame(d)
print (df)
one two three four five
a 1.0 1.0 0 1.0 f
b 2.0 2.0 1 1.0 f
c 3.0 3.0 2 1.0 f
d NaN 4.0 3 1.0 f
#可以使用dataframe.index和dataframe.columns來檢視DataFrame的行和列,
#dataframe.values則以數組的形式傳回DataFrame的元素
print ("DataFrame index:\n",df.index)
print ("DataFrame columns:\n",df.columns)
print ("DataFrame values:\n",df.values)
DataFrame index:
Index(['a', 'b', 'c', 'd'], dtype='object')
DataFrame columns:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')
DataFrame values:
[[1.0 1.0 0 1.0 'f']
[2.0 2.0 1 1.0 'f']
[3.0 3.0 2 1.0 'f']
[nan 4.0 3 1.0 'f']]
#DataFrame也可以從值是數組的字典建立,但是各個數組的長度需要相同:
d = {'one': [1., 2., 3., 4.], 'two': [4., 3., 2., 1.]}
df = DataFrame(d, index=['a', 'b', 'c', 'd'])
print df
one two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0
#值非數組時,沒有這一限制,并且缺失值補成NaN
d= [{'a': 1.6, 'b': 2}, {'a': 3, 'b': 6, 'c': 9}]
df = DataFrame(d)
print df
a b c
0 1.6 2 NaN
1 3.0 6 9.0
#在實際處理資料時,有時需要建立一個空的DataFrame,可以這麼做
df = DataFrame()
print (df)
Empty DataFrame
Columns: []
Index: []
#另一種建立DataFrame的方法十分有用,那就是使用concat函數基于Series
#或者DataFrame建立一個DataFrame
a = Series(range(5)) #range(5)産生0到4
b = Series(np.linspace(4, 20, 5)) #linspace(a,b,c)
df = pd.concat([a, b], axis=1)
print (df)
0 1
0 0 4.0
1 1 8.0
2 2 12.0
3 3 16.0
4 4 20.0 其中的axis=1表示按列進行合并,axis=0表示按行合并,
并且,Series都處理成一列,是以這裡如果選axis=0的話,
将得到一個10×1的DataFrame。下面這個例子展示了如何按行合并
DataFrame成一個大的DataFrame:
df = DataFrame()
index = ['alpha', 'beta', 'gamma', 'delta', 'eta']
for i in range(5):
a = DataFrame([np.linspace(i, 5*i, 5)], index=[index[i]])
df = pd.concat([df, a], axis=0)
print (df)
0 1 2 3 4
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0 2.2 DataFrame資料的通路
#DataFrame是以列作為操作的基礎的,全部操作都想象成先從DataFrame裡取一列,
#再從這個Series取元素即可。
#可以用datafrae.column_name選取列,也可以使用dataframe[]操作選取列
df = DataFrame()
index = ['alpha', 'beta', 'gamma', 'delta', 'eta']
for i in range(5):
a = DataFrame([np.linspace(i, 5*i, 5)], index=[index[i]])
df = pd.concat([df, a], axis=0)
print('df: \n',df)
print ("df[1]:\n",df[1])
df.columns = ['a', 'b', 'c', 'd', 'e']
print('df: \n',df)
print ("df[b]:\n",df['b'])
print ("df.b:\n",df.b)
print ("df[['a','b']]:\n",df[['a', 'd']])
df:
0 1 2 3 4
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
df[1]:
alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: 1, dtype: float64
df:
a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
df[b]:
alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: b, dtype: float64
df.b:
alpha 0.0
beta 2.0
gamma 4.0
delta 6.0
eta 8.0
Name: b, dtype: float64
df[['a','b']]:
a d
alpha 0.0 0.0
beta 1.0 4.0
gamma 2.0 8.0
delta 3.0 12.0
eta 4.0 16.0
#通路特定的元素可以如Series一樣使用下标或者是索引:
print (df['b'][2]) #第b列,第3行(從0開始算)
print (df['b']['gamma']) #第b列,gamma對應行
4.0
4.0
##### df.loc['列或行名'],df.iloc[n]第n行,df.iloc[:,n]第n列
#若需要選取行,可以使用dataframe.iloc按下标選取,
#或者使用dataframe.loc按索引選取
print (df.iloc[1]) #選取第一行元素
print (df.loc['beta'])#選取beta對應行元素
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: beta, dtype: float64
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: beta, dtype: float64
#選取行還可以使用切片的方式或者是布爾類型的向量:
print ("切片取數:\n",df[1:3])
bool_vec = [True, False, True, True, False]
print ("根據布爾類型取值:\n",df[bool_vec]) #相當于選取第0、2、3行
切片取數:
a b c d e
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
根據布爾類型取值:
a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
#行列組合起來選取資料:
print (df[['b', 'd']].iloc[[1, 3]])
print (df.iloc[[1, 3]][['b', 'd']])
print (df[['b', 'd']].loc[['beta', 'delta']])
print (df.loc[['beta', 'delta']][['b', 'd']])
b d
beta 2.0 4.0
delta 6.0 12.0
b d
beta 2.0 4.0
delta 6.0 12.0
b d
beta 2.0 4.0
delta 6.0 12.0
b d
beta 2.0 4.0
delta 6.0 12.0
#如果不是需要通路特定行列,而隻是某個特殊位置的元素的話,
#dataframe.at和dataframe.iat
#是最快的方式,它們分别用于使用索引和下标進行通路
print(df)
print (df.iat[2, 3]) #相當于第3行第4列
print (df.at['gamma', 'd'])
a b c d e
alpha 0.0 0.0 0.0 0.0 0.0
beta 1.0 2.0 3.0 4.0 5.0
gamma 2.0 4.0 6.0 8.0 10.0
delta 3.0 6.0 9.0 12.0 15.0
eta 4.0 8.0 12.0 16.0 20.0
8.0
8.0 2.3建立時間序列
pandas.date_range(start=None, end=None, periods=None, freq='D',
tz=None, normalize=False, name=None, closed=None, **kwargs)
dates=pd.date_range('20180101',periods=12,freq='m')
print (dates)
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31', '2018-09-30',
'2018-10-31', '2018-11-30', '2018-12-31'], dtype='datetime64[ns]',
freq='M')
np.random.seed(5)
df=pd.DataFrame(np.random.randn(12,4),index=dates,
columns=list('ABCD'))
df 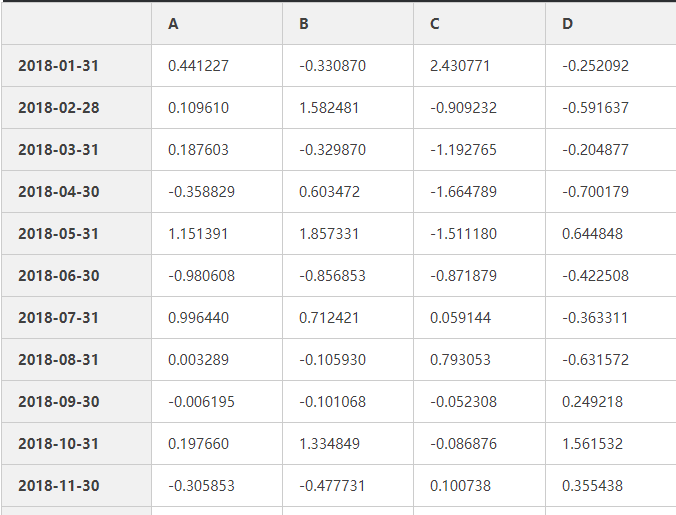
#檢視資料頭n行 ,預設n=5
df.head() 
#檢視資料最後3行
df.tail(3) #檢視資料的index(索引),columns (列名)和資料
print(df.index)
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31', '2018-09-30',
'2018-10-31', '2018-11-30', '2018-12-31'], dtype='datetime64[ns]',
freq='M')
print(df.columns)
Index(['A', 'B', 'C', 'D'], dtype='object')
print(df.values)
[[ 0.44122749 -0.33087015 2.43077119 -0.25209213]
[ 0.10960984 1.58248112 -0.9092324 -0.59163666]
[ 0.18760323 -0.32986996 -1.19276461 -0.20487651]
[-0.35882895 0.6034716 -1.66478853 -0.70017904]
[ 1.15139101 1.85733101 -1.51117956 0.64484751]
[-0.98060789 -0.85685315 -0.87187918 -0.42250793]
[ 0.99643983 0.71242127 0.05914424 -0.36331088]
[ 0.00328884 -0.10593044 0.79305332 -0.63157163]
[-0.00619491 -0.10106761 -0.05230815 0.24921766]
[ 0.19766009 1.33484857 -0.08687561 1.56153229]
[-0.30585302 -0.47773142 0.10073819 0.35543847]
[ 0.26961241 1.29196338 1.13934298 0.4944404 ]]
#資料轉置
# df.T 根據索引排序資料排序:(按行axis=0或列axis=1)
df.sort_index(axis=1,ascending=False) #按某列的值排序
df.sort_values('A') #按A列的值從小到大排序 #資料選取loc和iloc
df.loc[dates[0]]
A 0.441227
B -0.330870
C 2.430771
D -0.252092
Name: 2018-01-31 00:00:00, dtype: float64
df.loc['20180131':'20180430',['A','C']] #根據标簽取數 df.iloc[1:3,1:4] #根據所在位置取數,注意從0開始數 資料篩選isin()
df2=df.copy() #複制df資料
df2['E']=np.arange(12)
df2 df2[df2['E'].isin([0,2,4])] -
缺失值處理
缺失值用NaN顯示
date3=pd.date_range('20181001',periods=5)
np.random.seed(6)
data=np.random.randn(5,4)
df3=pd.DataFrame(data,index=date3,columns=list('ABCD'))
df3 df3.iat[3,3]=np.NaN #令第3行第3列的數為缺失值(0.129151)
df3.iat[1,2]=np.NaN #令第1行第2列的數為缺失值(1.127064)
df3 填充缺失值
fillna 還可以使用 method 參數
method 可以使用下面的方法
1 . pad/ffill:用前一個非缺失值去填充該缺失值
2 . backfill/bfill:用下一個非缺失值填充該缺失值
4、統計
date4=pd.date_range('20181001',periods=5)
np.random.seed(7)
data4=np.random.randn(5,4)
df4=pd.DataFrame(data4,index=date3,columns=list('ABCD'))
df4 描述性統計 df.describe()
df4.describe() df4.mean() #均值,預設按列axis=0
A 0.595828
B -0.000170
C -0.112358
D -0.899704
dtype: float64
df4.mean(axis=1) #按行
2018-10-01 0.416231
2018-10-02 -0.635618
2018-10-03 0.205295
2018-10-04 -0.363012
2018-10-05 -0.143401
Freq: D, dtype: float64 對資料使用函數df.apply()
5、資料合并
#Concat()
d1=pd.Series(range(5))
print(d1)
d2=pd.Series(range(5,10))
print(d2)
0 0
1 1
2 2
3 3
4 4
dtype: int64
0 5
1 6
2 7
3 8
4 9
dtype: int64
pd.concat([d1,d2],axis=1) #預設是縱向合并即axis=0 6、資料可視化(畫圖)
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文标簽
mpl.rcParams['axes.unicode_minus']=False # 用來正常顯示負号
%matplotlib inline
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000',
periods=1000))
ts = ts.cumsum()
ts.plot(figsize=(12,8))
#利用tushare包抓取股票資料并畫圖
#得到的是DataFrame的資料結構
import tushare as ts
df=ts.get_k_data('sh',start='1990-01-01')
import pandas as pd
df.index=pd.to_datetime(df['date'])
df['close'].plot(figsize=(12,8))
plt.title("上證指數走勢") 原文釋出時間為:2019-1-3
本文作者:CuteHand
本文來自雲栖社群合作夥伴“
Python愛好者社群”,了解相關資訊可以關注“python_shequ”微信公衆号