Kubernetes是什麼?
Kubernetes項目是2014年由Google公司啟動的,是Google公司在15年生産環境經驗基礎上 ,結合了社群的一些優秀點子和實踐而建構的。
Kubernetes是一個以容器為中心的基礎
架構,可以實作在實體叢集或虛拟機叢集上排程和運作容器,提供容器自動部署、擴充和管理的開源平台。滿足了應用程式在生産環境中的一些通用需求:應用執行個體副本、水準自動擴充、命名與發現、負載均衡、滾動更新、資源監控等。
使用Kubernetes可以:
- 自動化容器的部署和複制
- 随時擴充或收縮容器規模
- 将容器組織成組,并且提供容器間的負載均衡
- 很容易地更新應用程式容器的新版本
- 提供容器彈性,如果容器失效就替換它,等等
Kubernetes不提供:
- 中間件(例如消息總線)、資料處理架構(如 Spark )、 資料庫 (如 MySQL ),也不提供叢集存儲系統(如Ceph)。
- 源代碼到鏡像的處理,即不部署 源代碼也不會建構的應用,持續內建(Continuous Integration: CI)的工作也需要由使用者按自己項目決定。
- 不提供應用配置系統。
- 不提供機器配置、維護、管理。
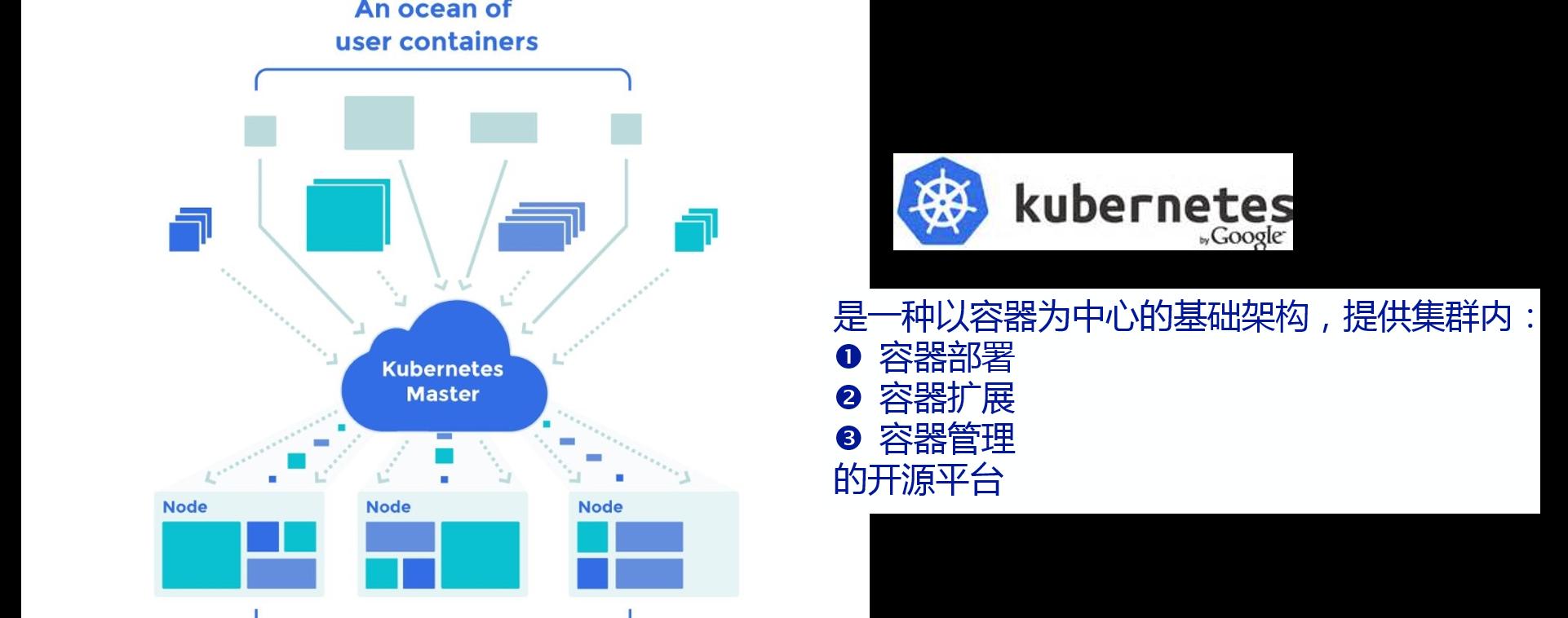
Kubernetes架構

Kubernetes叢集由2類節點組成:Master和Node。
在Master上運作etcd、kube-apiserver、kube-scheduler、kube-controller-magager四個元件,其中後3個元件構成了Kubernetes的總控中心,負責對叢集中所有資源進行管控和排程。
在Node上運作kubelet、kube-proxy、dockerdaemon三個元件,其中前2個元件負責對本節點上的Pod的生命周期進行管理,以及實作服務代理的功能。
另外在所有結點上都可以運作kubectl指令行工具,它提供了Kubernetes的叢集管理工具集。
etcd:是一個高可用的key/value存儲系統,用于持久化K8s叢集内中的所有資源對象,例如叢集中的Node、Service、Pod、RC、Namespace等。
kube-apiserver:封裝了操作etcd的接口,以REST的方式對外提供服務,這些接口基本上都是叢集資源對象的增删改查以及監聽資源變化的接口,如建立Pod、建立RC,監聽Pod變化的接口。kube-apiserver是連接配接其它服務元件的樞紐。
kube-scheduler:叢集中的排程器,負責Pod在叢集節點中的排程配置設定。
kube-controller-manager:叢集内部的管理控制中心,主要實作Kubernetes叢集的故障檢查和恢複自動化的工作。比如endpoints控制器負責Endpoints對象的建立,更新。node控制器負責節點的發現,管理和監控。複制控制器負責pod的數量符合預期定義。
kubelet:負責本Node上的Pod建立、修改、監控、删除等全生命周期管理,以及Pod對應的容器、鏡像、卷的管理,同時定時上報本Node的狀态資訊給kube-apiserver。
kube-proxy:實作了Service的代理以及軟體模式的負載均衡器。
Kubernetes基本概念
Pod
Pod是Kubernetes的裡可部署的和管理的最小單元,一個或多個容器構成一個Pod,通常Pod裡的容器運作相同的應用。Pod包含的容器都運作在同一個主控端上,看作一個統一管理單元。
每個Pod中都有一個pause容器,pause容器做為Pod的網絡接入點,Pod中其他的容器會使用容器映射模式啟動并接入到這個pause容器。屬于同一個Pod的所有容器共享網絡的namespace。
一個Pod可以被一個容器化的環境看做是應用層的邏輯主控端(Logical Host),每個Pod中有多個容器,同一個Pod中的多個容器通常是緊密耦合的。同一個pod中的容器共享如下資源:
PID 名字空間:Pod中不同應用程式可以看到其它應用程式的程序ID。
網絡名字空間:Pod中的多個容器通路同一個IP和端口空間。
IPC名字空間:Pod中的應用能夠使用SystemV IPC和POSIX消息隊列進行通信。
UTS名字空間:Pod中的應用共享一個主機名。
Volumes:Pod中的各個容器應用還可以通路Pod級别定義的共享卷。
Pod的生命周期,通過模闆定義Pod,然後配置設定到一個Node上運作,在Pod所包含的容器運作結束後Pod也結束。
在整個過程中,Pod的狀态:
挂起 ︰ Pod已被送出到Master,但一個或多個容器鏡像尚未建立。包括排程和下載下傳鏡像,可能需要一段時間。
運作 ︰ Pod已綁定到的節點,和所有容器鏡像已建立完成。至少一個容器是仍在運作,或正在啟動或重新啟動。
成功 ︰ Pod的所有容器已經成功的終止,并不會重新啟動。
失敗 ︰ Pod的所有容器已經都終止,至少一個容器已都終止失敗 (以非零退出狀态退出)。
未知 ︰ 出于某種原因的Pod狀态無法獲得,通常由于在與主機的Pod通信錯誤。
容器探測的診斷方式:
ExecAction :在
Container中執行指定的指令。當其執行成功時,将其退出碼設定為0;
TCPSocketAction :執行一個TCP檢查使用container的IP位址和指定的端口作為socket。如果端口處于打開狀态視為成功;
HTTPGetAcction :執行一個HTTP預設請求使用container的IP位址和指定的端口以及請求的路徑作為url,使用者可以通過host參數設定請求的位址,通過scheme參數設定協定類型(HTTP、HTTPS)如果其響應代碼在200~400之間,設為成功。
探測的結果有:
Success :表示通過檢測
Failure :表示沒有通過檢測
Unknown :表示檢測沒有正常進行
探測的種類:
LivenessProbe :表示container是否處于live狀态。如果LivenessProbe失敗,LivenessProbe将會通知kubelet對應的container不健康了。随後kubelet将kill掉container,并根據RestarPolicy進行進一步的操作。預設情況下LivenessProbe在第一次檢測之前初始化值為Success,如果container沒有提供LivenessProbe,則也認為是Success;
ReadinessProbe :表示container是否以及處于可接受service請求的狀态了。如果ReadinessProbe失敗,endpointscontroller将會從service所比對到的endpoint清單中移除關于這個container的IP位址。是以對于Service比對到的endpoint的維護其核心是ReadinessProbe。預設Readiness的初始值是Failure,如果一個container沒有提供Readiness則被認為是Success。
對容器實施配額,隻要在Pod的定義檔案中設定resources的屬性就可以為容器指定配額,目前容器支援的CPU和Memory兩種資源的配額。requests指定必須保證的最小資源,limits限制最大資源。
LabelandSelector
Label以key/value鍵值對的形式附加到各種對象上,如Pod、Node等。Label定義了這些對象的可識别屬性,用來對它們進行管理和選擇。Label可以在建立對象時指定也可以在對象建立後通過api進行添加。
在為對象定義好了Label後,其它對象就可以使用Label Selector來選擇還有指定Label的對象。
有效的Label key有兩個部分︰可選字首和名稱,以一個正斜杠(/)分隔。名稱部分是必須的并且長度為 63 個字元或更少,開始和結束以字母數字字元 ([a-z0-9A-Z]) 中間可以有破折号(-),下劃線 (_),圓點(.)和字母數字。字首是可選的。如果指定,字首必須是 DNS 子域︰一系列的 DNS 标簽分隔用點(.),不長于 253 個字元總數,其次是斜杠(/)。如果省略字首,則标簽鍵是須推定為私人使用者。kubernetes.io/ 字首為 Kubernetes 核心元件保留。
有效的Label value必須是 63 個字元或更少,必須為空或開始和結束以字母數字字元 ([a-z0-9A-Z])中間可以有破折号(-),下劃線 (_),圓點(.)和字母數字。
有2種Label Selector:基于等式的(Equality-based requirement)和基于集合的(Set-based requirement),在使用時可以将多個Label進行組合來選擇。
基于等式的Label Selector使用等式的表達式來進行選擇。
· name=
Redis:選擇所有包含Label中key=“name”且value=“redis”的對象。
· tier!=frontend:選擇所有包含Label中key=“tier”且value!=“frontend”的對象。
基于集合的Label Selector使用集合操作的表達式來進行選擇。
· name in(redis-master, redis-slave):選擇所有包含Label中key=“name”且value=“redis-master”或”redis-slave”的對象。
· tier notin(frontend):選擇所有包含Label中key=“tier”且value不等于”frontend”的對象。
可以将多個Label Selector進行組合,使用”,”進行分割。基于等于的Label Selector和基于集合的Label Selector可以任意組合。例如:
name=redis,tier!=frontend
name in(redis-master, redis-slave), tier=backend
使用Label可以給對象建立多組标簽,Service,RC元件通過Label Selector來選擇對象範圍,Label 和 Label Selector共同構成了Kubernetes系統中最核心的應用模型,使得對象能夠被精細的分組管理,同時實作了高可用性。
ReplicationController
Replication Controller核心作用是確定在任何時候叢集中一個RC所關聯的Pod都保持一定數量的副本處于正常運作狀态。如果該Pod的副本數量太多,則Replication Controller會銷毀一些Pod副本;反之Replication Controller會添加副本,直到Pod的副本數量達到預設的副本數量。
最好不要越過RC直接建立Pod,因為Replication Controller會通過RC管理Pod副本,實作自動建立、補足、替換、删除Pod副本,這樣就能提高應用的容災能力,減少由于節點崩潰等意外狀況造成的損失。即使應用程式隻有一個Pod副本,也強烈建議使用RC來定義Pod。
當Pod通過RC建立後,即使修改RC的模闆定義,也不會影響到已經建立的Pod。此外Pod可以通過修改标簽來實作脫離RC的管控,該方法可以用于将Pod從叢集中遷移、資料修複等調試。對于被遷移的Pod副本,RC會自動建立一個新副本替換被遷移的副本。需要注意的是,通過kubectl删除RC時會一起删掉RC所建立的Pod副本,但是通過REST API删除時,需要将replicas設定為0,等到Pod删除後再删除RC。
重新排程:如前面所說,不論是想運作1個副本還是1000個副本,Replication Controller都能確定指定數量的副本存在于叢集中,即使發生節點故障或Pod副本被終止運作等意外情況。
伸縮:修改Replication Controller的replicas的屬性值,可以非常容易的實作擴大或縮小副本的數量。例如,通過下列指令可以實作手工修改名為foo的RC副本數量為3:kubectl scale –replicas=3 rc/foo
滾動更新:副本控制器被設計成通過逐個替換Pod的方式來輔助服務的滾動更新。推薦的方法是建立一個新的隻有一個副本的RC,若新的RC副本數量加1,則舊的RC副本數量減1,直到這個舊的RC副本數量為0,然後删除舊的RC。這樣即使在滾動更新的過程中發生了不可預測的錯誤,Pod集合的更新也都在可控範圍之内。在理想情況下,滾動更新控制器需要将準備就緒的應用考慮在内,保證在叢集中任何時刻都有足夠數量的可用的Pod(
https://github.com/kubernetes/kubernetes/issues/1353)
Service
雖然每個Pod都會被配置設定一個單獨的IP位址,但這個IP位址會随着Pod的銷毀而消失。引出的一個問題是:如果有一組Pod組成一個應用叢集來提供服務,那麼該如何通路它們呢?
Service就是用來解決這個問題的,一個Service可以看作一組提供相同服務的Pod的對外接口,Service是通過LabelSelector選擇一組Pod作用後端服務提供者。
舉個例子:redis運作了2個副本,這兩個Pod對于前端程式來說沒有差別,是以前端程式并不關心是哪個後端副本在提供服務。并且後端Pod在發生變化時,前端也無須跟蹤這些變化。Service就是用來實作這種解耦的抽象概念。
Pod的IP位址是由
DockerDaemon根據docker0網橋的IP位址段進行配置設定的,但Service的Cluster IP位址是Kubernetes系統中的虛拟IP位址,由系統動态配置設定。
Service的Cluster IP相對于Pod的IP位址來說相對穩定,Service被建立時即被配置設定一個IP位址,在銷毀該Service之前,這個IP位址都不會再變化了。而Pod在Kubernetes叢集中生命周期較短,可能被Replication Controller銷毀、再次建立,新建立的Pod就會被配置設定一個新的IP位址。
如何通過Service Cluster IP通路到後端的Pod呢?Kubernetes群集中的每個節點運作kube-proxy。該程式負責對Service實作虛拟IP的實作。在 Kubernetes v1.0,代理即是純粹在使用者空間。在Kubernetes v1.1添加了iptables代理,但是并不是預設的操作模式。在Kubernetes v1.2預設用iptables代理模式。在iptables代理模式下kube-proxy會觀察Kubernetes Master節點添加和删除Service對象和Endpoint對象的行為,對于每個服務,kube-proxy會在本機的iptables中安裝相應的規則,iptables通過這些規則将會捕獲到該Service的流量并将他們重定向到一個後端的Pod。預設情況下後, 後端的選擇是随機的。
但是也可以選擇基于用戶端IP的sessionaffinity,可以通過設定service.spec.sessionAffinity=ClientIP(預設值為“None”)來選擇該方式。與使用者空間的代理一樣,用戶端不知道Kubernetes或Service或Pod,任何對于Service的IP:Port的通路都會被代理到後端。但是iptables的代理比使用者空間代理是更快、 更可靠。
Kubernetes支援兩種主要的模式來找到Service:一個是容器的Service環境變量,另一個是DNS。在建立一個Pod時,kubelet在該Pod的所有容器中為目前所有Service添加一系列環境變量。
Kubernetes支援形如“{SVCNAME}SERVICE_HOST”和“{SVCNAME}_SERVICE_PORT”的變量。其中“{SVCNAME}”是大寫的ServiceName,同時Service Name包含的“-”符号會轉化為“”符号。例如,已存在名稱為“redis-master”的Service,它對外暴露6379的TCP端口,且叢集IP為10.0.0.11。kubelet會為建立的容器添加以下環境變量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
通過環境變量來建立Service會帶來一個不好的結果,即任何被某個Pod所通路的Service,必須先于該Pod建立,否則和這個後建立的Service相關的環境變量,将不會被加入該Pod的容器中。
另一個通過名字找到服務的方式是DNS。DNS伺服器通過Kubernetes API Server監控與Service相關的活動。當監控到添加Service的時,DNS伺服器為每個Service建立一系列DNS記錄。例如:有個叫做”my-service“的service,他對應的kubernetesnamespace為”my-ns“,那麼會有他對應的dns記錄,叫做”my-service.my-ns“。那麼在my-ns的namespace中的pod都可以對my-service做name解析來輕松找到這個service。在其他namespace中的pod解析”my-service.my-ns“來找到他。解析出來的結果是這個service對應的cluster ip。
Service的ClusterIP位址隻能在叢集内部通路,如果叢集外部的使用者希望Service能夠提供一個供叢集外使用者通路的IP位址。Kubernetes通過兩種方式來實作上述需求,一個是“NodePort”,另一個是“LoadBalancer”。
每個service都有個type字段,值可以有以下幾種:
· ClusterIP:使用叢集内的私有ip —— 這是預設值。
· NodePort:除了使用cluster ip外,也将service的port映射到每個node的一個指定内部port上,映射的每個node的内部port都一樣。
· LoadBalancer:使用一個ClusterIP & NodePort,但是會向cloud provider申請映射到service本身的負載均衡。
如果将type字段設定為NodePort,kubernetesmaster将會為service的每個對外映射的port配置設定一個”本地port“,這個本地port作用在每個node上,且必須符合定義在配置檔案中的port範圍(為–service-node-port-range)。這個被配置設定的”本地port“定義在service配置中的spec.ports[*].nodePort字段,如果為這個字段設定了一個值,系統将會使用這個值作為配置設定的本地port 或者 提示你port不符合規範。
Namespace
Kubernetes 支援在一個實體叢集上建立多個虛拟群集。這些虛拟群集被稱為命名空間。大多數Kubernetes資源(例如: pods, services, replication controllers, and others) 在名稱空間中。但是namespace資源本身不在名稱空間中。還有一些底層資源如Node, PersistentVolumes不在名稱空間中。
Kubernetes叢集啟動後,會建立一個名為“default”的Namespace,如果不特别指明Namespace,則建立的Pod、RC、Service都将被建立到“default”的Namespace中。
當你建立一個服務時,它将建立相應的 DNS 條目。此條目是窗體..svc.cluster.local,這意味着如果一個容器隻是使用 它将解析為命名空間的本地的服務。這是用于跨多個命名空間,比如開發、分期和生産使用相同的配置。如果你想要達到整個命名空間,您需要使用完全限定的域名稱(FQDN)。
使用Namespace來組織Kubernetes的各種對象,可以實作對使用者的分組,即“多租戶”的管理。對不同的租戶還可以進行單獨的資源配額設定和管理,使得整個叢集的資源配置非常靈活、友善。一個叢集中的資源總是有限的,當這個叢集被多個租戶的應用同時使用時,為了更好地使用這種有限的共享資源,需要将資源配額的管理單元提升到租戶級别,通過在不同租戶對應的Namespace上設定對應的ResourceQuota即可達到目的。
本文轉自開源中國-
Kubernetes掃盲