監控告警原型圖
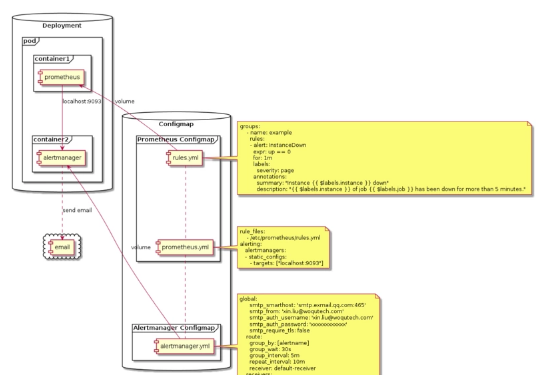
原型圖解釋
prometheus與alertmanager作為container運作在同一個pods中并交由Deployment控制器管理,alertmanager預設開啟9093端口,因為我們的prometheus與alertmanager是處于同一個pod中,是以prometheus直接使用localhost:9093就可以與alertmanager通信(用于發送告警通知),告警規則配置rules.yml以Configmap的形式挂載到prometheus容器供prometheus使用,告警通知對象配置也通過Configmap挂載到alertmanager容器供alertmanager使用,這裡我們使用郵件接收告警通知,具體配置在alertmanager.yml中
測試環境
環境:Linux 3.10.0-693.el7.x86_64 x86_64 GNU/Linux
平台:Kubernetes v1.10.5
Tips:prometheus與alertmanager完整的配置在文檔末尾
建立告警規則
在prometheus中指定告警規則的路徑, rules.yml就是用來指定報警規則,這裡我們将rules.yml用ConfigMap的形式挂載到/etc/prometheus目錄下面即可:
rule_files:
- /etc/prometheus/rules.yml 這裡我們指定了一個InstanceDown告警,當主機挂掉1分鐘則prometheus會發出告警
rules.yml: |
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes." 配置prometheus與alertmanager通信(用于prometheus向alertmanager發送告警資訊)
alertmanager預設開啟9093端口,又因為我們的prometheus與alertmanager是處于同一個pod中,是以prometheus直接使用localhost:9093就可以與alertmanager通信
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] alertmanager配置告警通知對象
我們這裡舉了一個郵件告警的例子,alertmanager接收到prometheus發出的告警時,alertmanager會向指定的郵箱發送一封告警郵件,這個配置也是通過Configmap的形式挂載到alertmanager所在的容器中供alertmanager使用
alertmanager.yml: |-
global:
smtp_smarthost: 'smtp.exmail.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxxxxxxxx'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 30s
group_interval: 5m
repeat_interval: 10m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: '[email protected]' 原型效果展示
在prometheus web ui中可以看到 配置的告警規則

為了看測試效果,關掉一個主機節點:
在prometheus web ui中可以看到一個InstanceDown告警被觸發
在alertmanager web ui中可以看到alertmanager收到prometheus發出的告警
指定接收告警的郵箱收到alertmanager發出的告警郵件
全部配置
node_exporter_daemonset.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
labels:
app: node_exporter
spec:
selector:
matchLabels:
name: node_exporter
template:
metadata:
labels:
name: node_exporter
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: node-exporter
image: alery/node-exporter:1.0
ports:
- name: node-exporter
containerPort: 9100
hostPort: 9100
volumeMounts:
- name: localtime
mountPath: /etc/localtime
- name: host
mountPath: /host
readOnly: true
volumes:
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: host
hostPath:
path: / alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: kube-system
data:
alertmanager.yml: |-
global:
smtp_smarthost: 'smtp.exmail.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxxxxxxxx'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 30s
group_interval: 5m
repeat_interval: 10m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: '[email protected]' prometheus-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
namespace: kube-system
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system prometheus-cm.yaml
kind: ConfigMap
apiVersion: v1
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
scrape_configs:
- job_name: 'node'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_ip]
action: replace
target_label: __address__
replacement: $1:9100
- source_labels: [__meta_kubernetes_pod_host_ip]
action: replace
target_label: instance
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: node_name
- action: labelmap
regex: __meta_kubernetes_pod_label_(name)
- source_labels: [__meta_kubernetes_pod_label_name]
regex: node_exporter
action: keep
rules.yml: |
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
metadata:
name: prometheus-config-v0.1.0
namespace: kube-system prometheus.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
namespace: kube-system
name: prometheus
labels:
name: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
name: prometheus
labels:
app: prometheus
spec:
serviceAccountName: prometheus
nodeSelector:
node-role.kubernetes.io/master: ""
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master 本文轉自SegmentFault-
Kubernetes中使用prometheus+alertmanager實作監控告警