在看源碼之前,先看幾遍論文《基于角色标注的中國人名自動識别研究》
關于命名識别的一些問題,可參考下列一些issue:
l ·名字識别的問題 #387
l ·機構名識别錯誤
l ·關于層疊HMM中文實體識别的過程
HanLP參考部落格:
詞性标注
層疊HMM-Viterbi角色标注模型下的機構名識别
分詞在HMM與分詞、詞性标注、命名實體識别中說:
分詞:給定一個字的序列,找出最可能的标簽序列(斷句符号:[詞尾]或[非詞尾]構成的序列)。結巴分詞目前就是利用BMES标簽來分詞的,B(開頭),M(中間),E(結尾),S(獨立成詞)
分詞也是采用了維特比算法的動态規劃性質求解的,具體可參考:文本挖掘的分詞原理
角色觀察以“唱首張學友的歌情已逝”為例,
先将起始頂點 始##始,角色标注為:NR.A 和 NR.K,頻次預設為1
iterator.next(); tagList.add(new EnumItem<NR>(NR.A, NR.K)); // 始##始 A K
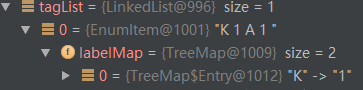
對于第一個詞“唱首”,它不存在于 nr.txt中,EnumItem<NR> nrEnumItem = PersonDictionary.dictionary.get(vertex.realWord);傳回null,于是根據它本身的詞性猜一個角色标注:
switch (vertex.guessNature()){
case nr:
case nnt:
default:{
nrEnumItem = new EnumItem<NR>(NR.A, PersonDictionary.transformMatrixDictionary.getTotalFrequency(NR.A));
}
}

由于"唱首"的Attribute為 nz 16,不是nr 和 nnt,故預設給它指定一個角色NR.A,頻率為nr.tr.txt中 NR.A 角色的總頻率。
此時,角色清單如下:
接下來是頂點“張”,由于“張”在nr.txt中,是以PersonDictionary.dictionary.get(vertex.realWord)傳回EnumItem對象,直接将它加入到角色清單中:
EnumItem<NR> nrEnumItem = PersonDictionary.dictionary.get(vertex.realWord);
tagList.add(nrEnumItem);
加入“張”之後的角色清單如下:
“唱首張學友的歌情已逝” 整句的角色清單如下:
至此,角色觀察 部分 就完成了。
總結一下,對句子進行角色觀察,首先是通過分詞算法将句子分成若幹個詞,然後對每個詞查詢人名詞典(PersonDictionary)。
若這個詞在人名詞典中(nr.txt),則記錄該詞的角色,所有的角色在com.hankcs.hanlp.corpus.tag.NR.java中定義。
若這個詞不在人名詞典中,則根據該詞的Attribute “猜一個角色”。在猜的過程中,有些詞在核心詞典中可能已經标注為nr或者nnt了,這時會做分裂處理。其他情況下則是将這個詞标上NR.A角色,頻率為 NR.A 在轉移矩陣中的總詞頻。
維特比算法(動态規劃)求解最優路徑在上圖中,給每個詞都打上了角色标記,可以看出,一個詞可以有多個标記。而我們需要将這些詞選擇一條路徑最短的角色路徑。參考隐馬爾可夫模型維特比算法詳解
List<NR> nrList = viterbiComputeSimply(roleTagList);
//some code....
return Viterbi.computeEnumSimply(roleTagList, PersonDictionary.transformMatrixDictionary);
而這個過程,其實就是:維特比算法解碼隐藏狀态序列。在這裡,五元組是:
l 隐藏狀态集合 com.hankcs.hanlp.corpus.tag.NR.java 定義的各個人名标簽
l 觀察狀态集合 已經分好詞的各個tagList中元素(相當于分詞結果)
l 轉移機率矩陣 由 nr.tr.txt 檔案生成得到。具體可參考:
l 發射機率 某個人名标簽(隐藏狀态)出現的次數 除以 所有标簽出現的總次數
Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur)
l 初始狀态(始##始) 和 結束狀态(末##末)
維特比解碼隐藏狀态的動态規劃求解核心代碼如下:
for (E cur : item.labelMap.keySet())
{
double now = transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] - Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur));
if (perfect_cost > now)
{
perfect_cost = now;
perfect_tag = cur;
}
}
transformMatrixDictionary.transititon_probability[pre.ordinal()][cur.ordinal()] 是前一個隐藏狀态 pre.ordinal()轉換到目前隐藏狀态cur.ordinal()的轉移機率。Math.log((item.getFrequency(cur) + 1e-8) / transformMatrixDictionary.getTotalFrequency(cur)是目前隐藏狀态的發射機率。二者“相減”得到一個機率 儲存在double now變量中,然後通過 for 循環找出 目前觀察狀态 對應的 最可能的(perfect_cost最小) 隐藏狀态 perfect_tag。
至于為什麼是上面那個公式來計算轉移機率和發射機率,可參考論文:《基于角色标注的中國人名自動識别研究》
在上面例子中,得到的最優隐藏狀态序列(最優路徑)K->A->K->Z->L->E->A->A 如下:
nrList = {LinkedList@1065} size = 8
"K" 始##始
"A" 唱首
"K" 張
"Z" 學友
"L" 的
"E" 歌
"A" 情已逝
"A" 末##末
例如:
隐藏狀态---觀察狀态
"K"----------始##始
最大比對有了最優隐藏序列:KAKZLEAA,接下來就是:後續的“最大比對處理”了。
PersonDictionary.parsePattern(nrList, pWordSegResult, wordNetOptimum, wordNetAll);
在最大比對之前,會進行“模式拆分”。在com.hankcs.hanlp.corpus.tag.NR.java 定義了隐藏狀态的具體含義。比如說,若最優隐藏序列中 存在 'U' 或者 'V',
U Ppf 人名的上文和姓成詞 這裡【有關】天培的壯烈
V Pnw 三字人名的末字和下文成詞 龔學平等上司, 鄧穎【超生】前
則會做“拆分處理”
switch(nr)
{
case U:
//拆分成K B
case V:
//視情況拆分
拆分完成之後,重新得到一個新的隐藏序列(模式)
String pattern = sbPattern.toString();
接下來,就用AC自動機進行最大模式比對了,并将比對的結果存儲到“最優詞網”中。當然,在這裡就可以自定義一些針對特定應用的 識别處理規則
trie.parseText(pattern, new AhoCorasickDoubleArrayTrie.IHit<NRPattern>(){
//.....
wordNetOptimum.insert(offset, new Vertex(Predefine.TAG_PEOPLE, name, ATTRIBUTE, WORD_ID), wordNetAll);
将識别出來的人名儲存到最優詞網後,再基于最優詞網調用一次維特比分詞算法,得到最終的分詞結果---細分結果。
if (wordNetOptimum.size() != preSize)
vertexList = viterbi(wordNetOptimum);
if (HanLP.Config.DEBUG)
System.out.printf("細分詞網:\n%s\n", wordNetOptimum);
總結源碼上的人名識别基本上是按照論文中的内容來實作的。對于一個給定的句子,先進行下面三大步驟處理:
l 角色觀察
l 維特比算法解碼求解隐藏狀态(求解各個分詞 的 角色标記)
l 對角色标記進行最大比對(可做一些後處理操作)
最後,再使用維特比算法進行一次分詞,得到細分結果,即為最後的識别結果。
這篇文章裡面沒有寫維特比分詞算法的詳細過程,以及轉移矩陣的生成過程,以後有時間再補上。看源碼,對隐馬模型的了解又加深了一點,感受到了理論的東西如何用代碼一步步來實作。由于我也是初學,對源碼的了解不夠深入或者存在一些偏差,歡迎批評指正。
關于動态規劃的一個簡單示例,可參考:動态規劃之Fib數列類問題應用。