AI·OS技術棧
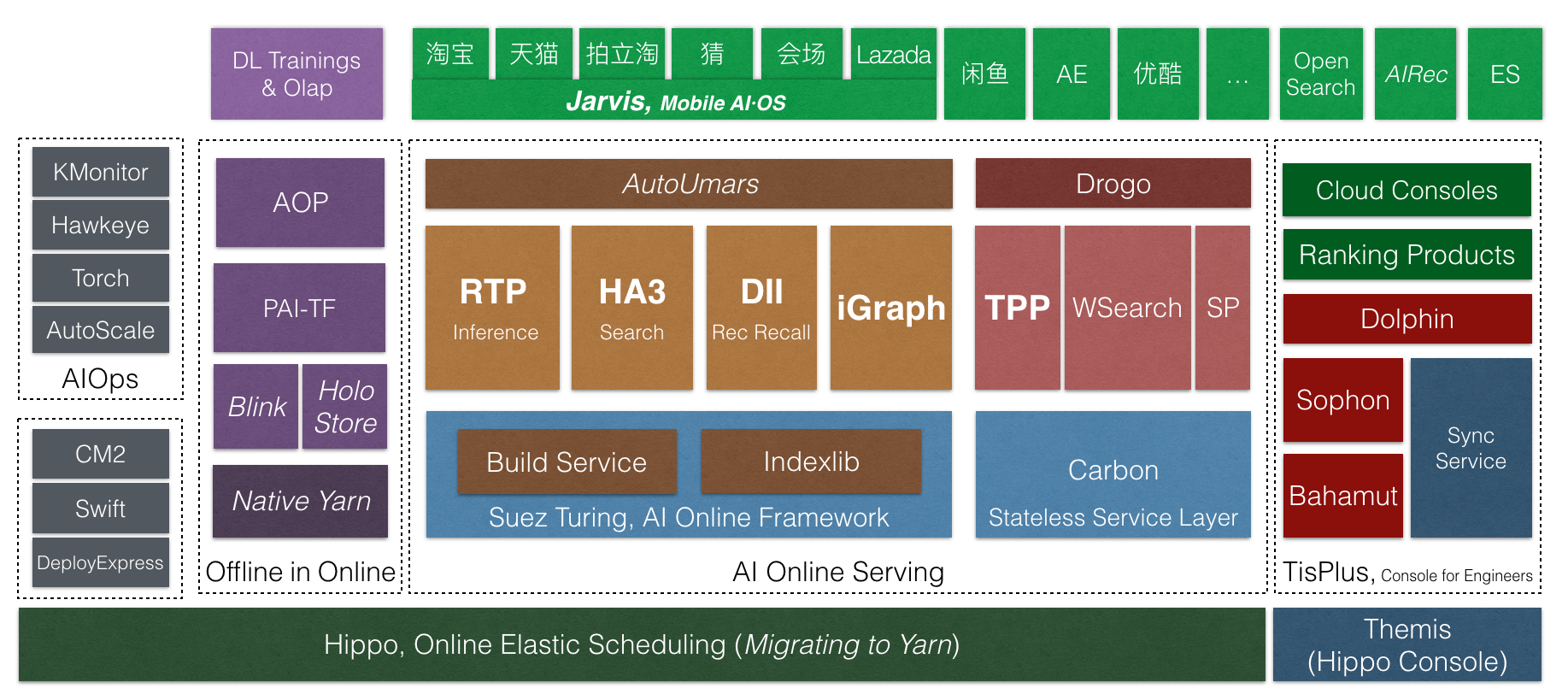
2018年9月底,搜尋事業部舉辦了一場十年技術峰會。在這場峰會上,我們正式将搜尋的線上服務由iSearch5更新到AI·OS大資料深度學習線上服務體系。這次名稱的變化,展現的是搜尋技術十年量變到質變的積累,展現的是搜尋人十年的堅持。
搜尋近十年的發展可以分為四個主要的階段。一是2008至2009年,iSearch 4.0版本,是搜尋技術獨立起航的第一個版本,它脫胎于iSearch 3.0,強調的是分布式、大規模、高可用,有很好的擴充能力,當時在B2B和淘寶同時上線,使搜尋技術趕上了業務的發展。二是2009年至2011年,引擎出現了Kingso和HA3兩個分支,Kingso以高性能聞名于世,HA3則是完全重構的版本,具有良好架構。這個階段主題是系統化和高性能,我們開始将引擎視為一個完整、閉環的系統,而不是一系列程序和腳本的拼接。三是2011年至2013的搜尋技術峰會,我們将集團搜尋引擎統一,提出了iSearch 5.0引擎平台。這個階段的關鍵是平台化,我們認為應當打造一個引擎平台支援全集團的搜尋業務,而不是為每個搜尋業務定制引擎,隻有這樣才能走得更快。當年在平台化與效率的問題上,搜尋内部有一波不小的争論,事實上,這種争論在集團很多平台上仍在重演。隻要有平台與業務之分,就會産生這種争論,平台如何抽象才能支援好業務的疊代、保證業務不被阻塞,業務又如何積累産生平台性的創新、保證平台的統一性,究竟應該統一版本還是分支發展。我個人是平台化堅定的支援者,但平台化不意味着不允許分支,平台化也不意味着不允許業務快速疊代創新,平台化更不意味着隻能有一個團隊開發平台功能。恰恰相反,平台團隊僅僅是代碼主線的維護者,是武林盟主而不是皇帝。一切以技術正确、而不是政治正确來衡量,隻要堅持這一點,萬流歸宗,所有的分支自然會回歸主線,這是中台應有的自信,充分開放才能成就中台。
2013年到現在的五年,是搜尋發展的第四個階段,搜尋技術面對了很多新的挑戰,其中最大兩個,一是推薦的崛起,二是深度學習的廣泛應用。這也是AI·OS産生的原因,我們面對的不再是搜尋一個單一引擎,而是多樣化的推薦引擎和深度學習引擎,這就需要更高層的服務架構抽象和更高效的執行引擎。
接下來,我來介紹一下引擎平台在最近一年的發展和創新。
Suez Turing線上服務架構
推薦業務與深度學習的發展都對線上服務架構提出了很大的挑戰。
從推薦業務來看,與搜尋類似,也是query處理、召回、排序、後處理幾個階段,但每個階段都有自己的特點。比如推薦的召回廣泛使用多路召回混排的模式,細節每個場景還會略有不同。如此之多的種類群組合,很難用一個固定的引擎支援,而簡單把這些邏輯丢給算法同學,又會回到TPP上一坨複雜低效java代碼的老路。我們需要一個高性能、易定制、高抽象的線上服務架構。
從深度學習的應用來看,模型已經無孔不入,不僅僅是排序時才需要運作深度模型。在query處理、召回甚至是取摘要時都可能有模型。從性能優化的角度考慮,我們還有可能在離線Build階段運作模型。是以,深度模型的計算,不是一個割裂的、另類的需求。是必須内置到執行引擎,與正常的召回、過濾、排序、統計對等的功能。
基于這些考慮,今年我們更新了Suez服務架構,提出了Suez Turing全圖化線上服務架構。今年,Suez Turing引擎在架構上實作了HA3、BE、RTP的整合,并在雙11成功應用到了主搜、店鋪内、猜你喜歡BE、海神、菜鳥等業務線。主搜上實作了HA3和RTP合圖并支援了粗排深度模型;猜你喜歡BE上實作了算子并行使得latency降低一半;codegen技術使菜鳥包裹引擎統計性能提升一倍。經曆雙11,Suez Turing架構的穩定性和性能均得到了驗證。
RTP深度學習預測服務
今年雙11,各種業務場景上深度學習應用仍然處于井噴狀态。搜尋與推薦各種業務場景紛紛上線大模型,特别是AOP一站式算法平台推出後,大幅降低了算法同學實驗和上線模型的難度。RTP上的模型複雜度大幅增加。
在CPU計算上,我們主要的兩個優化手段是online2offline和fg codegen技術,将CPU端性能提升一倍以上。在異構計算加速上,今年我們大規模應用了GPU和FPGA異構計算技術,使用FPGA的數量超過了GPU。特别是我們與AIS合作FPGA加速方案,是FPGA在阿裡集團内首個深度學習大規模生産應用的場景。在去年雙11灰階驗證的基礎上,今年FPGA成為支撐搜尋雙11的主力,在中小batch場景下,FPGA帶來的提升明顯。FPGA全鍊路軟硬體都可掌控、可優化,未來潛力巨大。
另一方面,RTP平台上業務大幅增長,而且業務都是使用者自助建立的。如何自動為使用者選擇最合适的叢集,如何保證這麼多的業務安全穩定的更新和更新。我們在叢集治理方面也做了不少工作,大大減輕了RTP平台的維護代價。
搜尋混部
今年雙11,搜尋混部仍然保持持續工作,在包括11日淩晨最高峰的時段都保持不降級。混部上10日晚間至11日淩晨計算的算法模型,在11日當天上線,為提升使用者體驗發揮了巨大的作用。在雙11的30小時内,搜尋事業部國内所有機房的平均負載做到了40%,峰值做到50%。最大的一個混部機房做到平均負載57%,峰值70%。
今年我們與計算平台事業部合作,推出了AliYarn,将搜尋線上多年積累的線上排程和隔離能力輸出到Yarn中。通過這個版本,我們在去年混部深度學習訓練任務的基礎上,做到了與Flink實時計算任務的混部。雙11後,AliYarn将會在搜尋線上上線,成為Sigma上同時支援離線任務、流式任務、線上服務的排程器。
線上服務計算存儲分離
不論是搜尋還是推薦,還是深度學習,都離不開資料,計算和存儲是線上服務要解決的兩個永恒的問題。搜尋排程系統統一後,可以發現上層業務非常多樣,有極端重計算輕索引的應用,也有極少流量索引巨大的應用。不論是那種線上服務,對latency的要求都是一樣的。對大資料量的應用,普遍存在着搬移慢,故障恢複慢的問題。而為了支援這些大資料量的應用,即使他們隻運作在少數機器上,為了成本,我們的機型也要做普遍的适配,實際上是加大了整體成本。再加上索引切換之類的額外預留,實際有效存儲使用不到一半。
今年阿裡集團普遍推廣使用計算存儲分離技術,搜尋也不例外,但搜尋的場景非常特殊。一是,搜尋分離的資料量并不大,因為我們是線上服務,最大也不過是PB級,這與大資料離線計算相比,資料量不值一提。二是,搜尋的服務品質要求極高,我們要求4個9穩定的讀latency,而且是在一個并不小的寫背景下,這與追求吞吐的離線計算和作為普通log存儲的場景完全不同。三是,搜尋對服務的可用性要求極高,要做到線上服務級别的可用性。
今年雙11我們在兩個業務場景實驗了線上服務計算存儲分離。一是一個推薦場景,存儲分離節省了45T記憶體,結合Suez Turing全圖化架構,大幅縮列提升性能,以73%的伺服器支撐了262%的流量。另一個是摘要服務場景,這在搜尋與推薦鍊路都是至關重要的服務,存儲分離叢集穩定承擔了20%的流量。叢集延遲和性能表現穩定。雙11後,我們将在搜尋全面推廣計算存儲分離技術。
展望
接下來,AI·OS引擎平台會繼續推進線上服務架構的疊代演進,推進Suez Turing上層引擎的統一,做更大範圍的合圖。最終我們希望能讓使用者很友善地定制背景引擎,同時保持高性能和高可用。
叢集排程和管理方面,我們會推廣計算存儲分離技術,将大量大索引有狀态的服務無狀态化,加速排程決策執行速度和故障恢複的速度。同時,我們還會進一步統一搜尋的在離線排程,做更大範圍的統一排程。
在異構計算加速方面,我們要積極嘗試新的密度更高的異構硬體型号,在FPGA軟硬體協同和GPU的新型号引入方面也要投入更大的精力。
![241 Different Ways to Add Parentheses(C代碼版)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)