1.概述
不斷變化字首域名:是指域名的字尾不變,字首随機變化,例如:
aaaxbhzqegs.www.example.com.
aachbgunkyi.www.example.com.
aaazqppqiir.www.example.com.
aabkwblebrz.www.example.com.
aaaiwcdsrvf.www.example.com.
其中:www.example.com 是三級字尾,aaaxbhzqegs,aachbgunkyi,aaazqppqiir等都是www.example.com 的緊鄰下一級字首;example.com 是二級字尾,www是它的緊鄰下一級字首。
另外,還有一些不斷變化中綴域名:是指域名的字首、字尾不變,中綴随機變化,例如:
www.aaaxbhzqegs.example.com.
www.aachbgunkyi.example.com.
www.aaazqppqiir.example.com.
www.aabkwblebrz.example.com.
www.aaaiwcdsrvf.example.com.
其中:www是字首,example.com 是二級字尾,aaaxbhzqegs,aachbgunkyi等都是中綴,同時也是 example.com 二級字尾的緊鄰下一級字首。
不斷變化字首域名攻擊中,字首字元串是随機變化的,且數量龐大,不對它們進行遞歸請求很難判斷該域名是否存在,而遞歸能力一直是DNS系統的性能瓶頸,是以需要實時對此攻擊進行檢測,進而進行相應地防護。
2.難點
不斷變化字首域名攻擊檢測的一些已知難點有:
- 不斷變化的部分可能是任意級的字首、中綴;
- 攻擊有可能同時針對多個字尾,且每個字尾的字首變化次數都不顯著,而它們加起來的變化次數比較顯著;
- 泛解析幹擾:有些字尾配置了泛解析,則不管其字首如何變化,均不能被認為是攻擊;
- 攻擊域名與正常域名屬于相同的字尾,正常域名容易被誤殺,如 example.com 是攻擊域名,而 www.example.com 是正常域名,當檢測到字尾 example.com 遭受攻擊時,容易将 www.example.com 誤殺;
3.解決方案
針對上面遇到的問題,我們提出了一種基于在離線混合學習的随機域名攻擊檢測方案。該方案包括線上檢測與離線訓練兩個部分,如下圖所示:
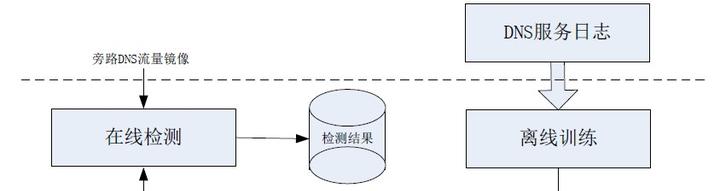
圖3-1 不斷變化字首域名攻擊檢測系統結構圖
線上檢測部分的功能是:根據離線訓練好的分類模型對實時流入的DNS查詢請求進行分類,分為疑似攻擊域名與正常域名兩類,再結合其響應結果分别統計,累計一段極短的時間後,根據門檻值檢測出攻擊的字尾,并輸出檢測結果;
離線訓練部分的功能是:對一段較長時間的DNS服務日志進行挖掘,分類訓練,得到分類模型,供線上檢測部分使用;
首先我們來看線上檢測的流程,如下圖所示:

圖3-2 線上檢測流程圖
- 定時更新分類模型:每天定時從外部更新分類模型;
- 旁路流入DNS查詢、響應:旁路鏡像流入DNS查詢、響應資料包;
- 查詢、響應組合:根據五元組(源IP、源端口、目的IP、目的端口、DNS_ID)将查詢包與響應報組合起來,得到每個查詢對應的響應狀态碼(如NoError, ServFail, NxDomain等);
- 過濾:過濾出沒有響應(逾時)或響應狀态碼是ServFail、NxDomain的查詢;
- 域名拆分組合:将查詢域名拆分成各級字尾與其緊鄰下一級字首的組合,如 example.com 被拆分成:一級字尾與其緊鄰下一級字首的組合:com + [example]、二級字尾與其緊鄰下一級字首的組合:example.com + [aaaxbhzq];
- 字元串判定:對各級字尾的緊鄰下一級字首字元串提取特征,根據分類模型判定其是否随機、無意義;
- 重複字首判定:對于每一個字尾,維護一個集合,用于緩存出現過的字首,重複字首被丢棄;
- 累計緩存:把字首追加到對應字尾的緩存集合裡,對應字尾的計數器加1;
- 視窗判定:統計時間視窗設定為一個極短的時間(如30秒);
- 攻擊判定:字尾計數器大于攻擊門檻值T0;
- 輸出攻擊的字尾:此時不通知防禦;
- 防禦判定:所有攻擊字尾的計數器之和大于防禦門檻值T1;
- 通知開啟防禦:及時通知外部開啟防禦,給出攻擊字尾清單;
- 清空緩存集合、計數器;
然後我們再來看一下離線訓練的流程,如下圖所示:
圖3-3 離線訓練流程圖
- 日志預處理:将DNS服務日志處理成<查詢域名,是否攻擊>的二進制組;
- 樣本采集:随機選擇大量(如100萬)的是攻擊的二進制組作為正樣本、大量(如30萬)的不是攻擊的二進制組作為負樣本;
- 樣本劃分:所有正負樣本一起按一定的比例(如6:4)随機劃分為訓練集和測試集;
- 計算變化字首所在級數L及對應的資訊熵均值h:在訓練集上,周遊域名若幹級字尾,提取其緊鄰下一級字首字元串的資訊熵(見第6步中(b)資訊熵),統計其均值,使得均值最大的級數即為所求的L,對應的均值記為h;
- 資訊熵均值是否大于門檻值H;
- 特征提取并歸一化:對字首字元串提取特征向量,它由三個特征組成:
1) 最長元音距(mvd):即字元串中元音之間的最長間隔,如“alibaba-inc”的最長元音距是最後的“nc”2個字元長度(字元串中的連字元‘-’也當作元音處理,字元串結尾也當作有一個元音)。
元音距表征了字元串中各音節的長度,展現了發音的節奏。正常有意義的單詞或短語的音節比較短,節奏比較均勻,以友善發出聲音,相應地,其最長元音距偏短,如“alibaba-inc”的元音距為[1,1,1,2],最長元音距為2;而無意義的随機字元串的音節比較長,沒有節奏,相應地,其最長元音距偏長,如“aaaxbhzqegs-2”的元音距為[5,2,1],最長元音距為5;
2)資訊熵(entropy):表征字元串的随機程度,其計算公式為:
其中, Pi為每個字母(或數字)在字元串中出現的機率。
正常有意義的單詞或短語,其字元排列遵從書寫規範,不能任意排列,随機化程度不高,資訊熵偏低,如“alibaba-inc”的資訊熵為2.44;而無意義的随機字元串的字元排列則沒有限制,随機化程度比較高,資訊熵偏高,如“aaaxbhzqegs-2”的資訊熵為3.19;
3)長度(len):字元串的長度。觀察中發現,攻擊字元串的長度在一段短時間内都比較穩定,且長度比較大;而正常的域名字元串則無此規律。
圖3-4顯示了這三種特征分别在攻擊域名、正常域名中的分布情況,可以看出,它們在攻擊域名與正常域名中的分布都具有較大差異,主要在于:在攻擊域名中,均值都偏大。
特征歸一化采用Z-score歸一化法,其計算公式為:
其中u為樣本均值,o~為樣本标準差;
- 訓練分類模型:在訓練集上進行模型訓練,分類模型采用線性SVM(Support Vector Machine 支援向量機),其公式為:
其中x為特征向量(最長元音距,資訊熵,長度), wT為系數向量, b為截距,如若結果大于0,則判定為正樣例(攻擊),否則判定為負樣例(非攻擊)。訓練過程即是要找到一個最合适的wT和b;另外,還需要擷取訓練集的樣本均值向量u、标準差向量o~;
- 模型評估:在測試集上評估訓練好的SVM模型,得到總體準确率;
- 模型準确率是否大于門檻值T;
- 輸出模型:模型包括SVM參數wT, b與歸一化參數u, o~ 。
圖3-4 最長元音距(mvd)、資訊熵(entropy)、長度(len)分别在攻擊域名(positive)、正常域名(negative)中的分布情況。
從圖中可以看出,三種特征在攻擊域名中的均值較正常域名大。