雷鋒網 AI 科技評論按:如果每個人都有足夠的時間和熱誠,并樂意去大學拿個 AI 學位,那你大概就不會讀到這篇部落格了。 雖說 AI 的工作方式挺神秘的,但在處理技術問題的時候,以下這五個 AI 原則應該可以幫你規避一些錯誤。它們對于當代的基于統計學習的機器學習(Machine Learning)系統,尤其是深度學習(Deep Learning)系統尤其适用。
這篇來自 eloquent.ai 部落格的文章所說的,總結起來就是這 5 條 AI 原則:
利用未曾見過的資料評估AI系統
更多資料可以帶來更好的模型
有效資料的價值遠遠超過無效資料
從一個簡單的基線開始
人工智能并不是魔法
給大家一個小小的忠告——通過對機器學習的基本了解,這篇文章将更有意義。 之前的另一篇文章(https://blog.eloquent.ai/2018/08/30/machine-learning-for-executives/)對這些基礎知識有所解釋。當然了,不是說這篇文章你非讀不可,但是讀了的話肯定會對你後面的了解更有幫助!(也歡迎大家閱讀雷鋒網 AI 科技評論的其它文章)
1. 利用未曾見過的資料評估AI系統
在上一篇文章中,我們介紹了如何建構分類器以将圖像标記為貓(綠色圓圈)或狗(藍色三角形)。在将我們的訓練資料轉換為向量之後,我們得到了下面的圖表,其中紅線表示我們的“決策邊界”(即将訓練資料轉換為向量後,這條“邊界線”就将圖像劃分為貓和狗)。
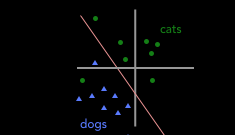
顯然,圖中的決策邊界錯誤地将一隻貓(綠色圓形)标記标記成了狗(藍色三角形),即遺漏了一個訓練個樣本。那麼,是什麼讓訓練算法沒有選擇下圖中的紅線作為決策邊界呢?

在這兩種情況下,我們對訓練集進行分類都得到了同樣的準确率——兩中決策邊界都标錯了一個例子。但是如圖示,當我們在資料中加上一隻未出現過的貓時,隻有左圖的決策邊界會正确地預測這個點為貓:
分類器可以在用來訓練它的資料集上工作得很順利,但它未必适用于訓練的時候沒有見過的資料。此外,即使分類器在特定類型的輸入(例如,室内場景中的貓)上工作良好,它對于相同任務的不同資料(例如,室外場景中的貓)也可能無法很好地工作。
盲目地購買 AI 系統而不對相關的未知資訊進行測試,可能會付出很大的代價。一種測試未知資料的實用方法是——先保留一部分資料不提供給開發人工智能系統的企業或個人,然後自己通過生成的系統運作這些保留資料。最不濟,也得保證你能自己試用才行。
2. 更多資料可以帶來更好的模型
如果給你下面的訓練資料集,你會把決策邊界畫在哪裡?
你想的可能沒錯——許多決策邊界可以準确地分割這些資料。 雖然下面的每個假設決策邊界都正确地分割了資料,但它們彼此之間的差别很大,正如我們上面所看到的,其中一些可能會在目前尚未見到的資料(也就是你真正關心的資料)上更糟糕:
從這個小資料集中,我們不知道這些彼此不同的決策邊界中,究竟哪一個最準确地代表了現實世界。缺乏資料會導緻不确定性,是以我們得收集更多資料點,并将其添加到初始圖表中,則可得到下圖:
額外的資料能幫助我們大幅縮小選擇範圍,立即畫出綠色和藍色間的決策邊界,是以決策邊界會是如下所示:
當機器學習模型表現異常時,潛在的問題通常是模型沒有經過足夠或正确的資料訓練。盡管更多的資料幾乎總是有幫助,但需要注意,資料越多可能得到的回報卻在減少。當我們将第一個圖的資料加倍時,準确度明顯增加。但是基于該圖表,如果将資料再加倍,則精度的提高不會有之前那麼大。準确度随着訓練資料的數量大緻呈對數增長,是以從 1k 到 10k 個樣本可能比從 10k 到 20k 個對準确性産生更大的影響。
對于我個人來說,這一條特别忌諱,尤其是對于預算緊張的創業公司:你們經常給ML工程師支付數高額薪水,但也請確定提供足夠的預算和時間來讓他們仔細收集資料。
3. 有效資料的價值遠遠超過無效資料
在上面的例子中,雖說有更多的資料會對訓練有所幫助,但前提是它們足夠準确才行。還是前面的例子,在收集了附加資料之後,可以得到一個這樣的圖形和一個決策邊界,如下所示:
但是,如果這些新資料點中的一些其實是被錯誤标記了,而真是情況是下面這樣的呢?
我們要注意,雖然這些标記錯誤的點與第一個圖中的點坐标相同,但它們代表的意義已經改變。這導緻了一個完全不同的決策邊界:
即使隻有四分之一的資料集被錯誤标記,但很明顯,錯誤的資料會對我們的模型建構有重大影響。我們可以在訓練期間使用一些技術來減少标記資料時的錯誤,但這些技術作用有限。在大多數情況下,清理基礎資料更加容易和可靠。
這裡的要點是“有效資料”至關重要,有效資料意味着資料準确标記,意味着資料合理涵蓋了我們想關注的範圍,也意味着訓練集中同時存在簡單案例和困難案例等等。因而決策邊界沒有那麼多的擺動空間,隻有一個“正确”的答案。
4. 從一個簡單的基線開始
這并不是說你應該嘗試了一點簡單的東西就覺得滿意然後停下來。即便你最終的方法既現代又複雜,通過這條原則,你也會開發得更快,并且最終的結果也會更好。
我可以舉一個關于我自己的真執行個體子,當我讀研一時,我們實驗室的同學兼 Eloquent 的研究員 Angel 和我參與了一個項目,我們各自将語言裡描述時間的詞轉化成可供機器閱讀的格式。本質上來說,就是試圖讓計算機了解諸如“上周五”或“明天中午”之類的短語。
由于這些項目是申基金所必需的,Angel 緻力于一個實用性強,有确定性的規則系統。她為了讓這個系統能實用起來而絞盡腦汁。而我當時隻是一個在實驗室輪崗的學生,團隊讓我自主選擇任何花哨的方法,就像糖果店裡的孩子一樣。我探索了最時髦、最動人的語義解析方法。在我的項目中,我運用了 EM、共轭先驗、一個完整的自定義語義解析器等等新奇的方法。
差不多十年之後,我很高興還留下了一篇受到好評并且引用數還行的論文。然而,Angel 的項目 SUTime 呢,現在是斯坦福流行的 CoreNLP 工具包中最常用的元件之一——簡單的方法擊敗了時髦的方法。
你可能以為我已經吸取了教訓,然而幾年之後,當我成為一名高年級研究所學生時,我要讓另一個系統啟動并用于另一個基金項目。我再一次試圖訓練一個花哨的機器學習模型,但幾乎沒有做出什麼成果。有一天我覺得無比失敗和沮喪,以至于我甚至開始寫“模式”。“模式”就是一些簡單的确定性規則。比如,當一個句子包含“出生于”這個詞時,則假設這是一個出生地。模式不會學習,作用有限,但它們易于編寫且用起來合理。
最後,基于模式的系統不僅勝過我們原來的系統,它後來還被加到了 NIST 排名前 5 的系統中,并深深影響了那些基于機器學習的模型高性能系統。
結論就是:先做簡單的事。當然了,我們還有其他更好的理由:
它會給你的最終模型的性能提供一個安全的最低值。當你做出一個簡單的基準模型之後,你會希望任何聰明的東西都會擊敗它。幾乎不會有什麼模型會比一個基于規則的模型表現還要差。這給你的更進階的方法提供了一個比較,如果你的進階方法的表現更差,那意味着你有什麼東西徹底做錯了,并不是任務太過艱巨。
通常,簡單的方法需要較少的(或不用!)訓練資料,這就使你可以在沒有大量資料投資的情況下進行原型設計。
它經常會揭示出手頭任務的難度,這通常會向你指明如何選擇更好的機器學習方法來處理這些困難的部分。此外,它還能向你指明如何給需要更多資料的方法收集資料。
簡單的方法一般隻需要很少的額外努力就可以泛化到未見過的資料上。(記住:總是用模型沒有見過的資料來評估模型!)更簡單的模型往往更容易解釋,這使得它們更具可預測性,是以讓它們向沒有見過的資料上泛化的過程也更明了。
5. 人工智能并不是魔法
這句話是我經常挂在嘴邊的。大家雖然表面上都表示贊同,但心裡未必真的服氣,因為人工智能看起來就像魔術一樣。在談到 Eloquent 人工智能的宏偉未來計劃時,我對曾經反複強調這個錯誤觀念感到内疚。我從訓練機器學習模型的細節中得到的越多,模型看起來就越看起來不像是曲線的拟合,它們看起來更像一個黑匣子,我可以付出一些代價來進行操控。
人們很容易忘記,現代機器學習領域還很年輕——隻有二三十歲。與現代機器學習工具包的成熟度和複雜性相比,整個領域仍然相當不成熟。它的快速進步使人們很容易忘記這一點。
機器學習的一部分邪惡之處在于它具有内在的機率性。它在技術上無所不能,但不一定達到你想要的準确度。我懷疑在許多機構中,在組織結構圖上添加新東西時,“準确度”的細微差别被漏下,隻留下“人工智能可以做任何事情”的叙述部分。
你如何将不可能與可能分開?我嘗試遵循一些最佳做法:
與實際訓練模型的人交談。不是團隊上司,不是部門主管,而是讓模型訓練代碼運作起來的人。他們通常可以更好地了解模型的工作原理及其限制。確定他們願意随時告訴你,你的模型有限制并且在某些方面表現不佳。我敢保證,無論他們是否告訴你,你的模型總會有一些不行的方面。
至少對于 NLP 項目,你通常可以使用一個快速又繁雜的基于規則的系統來檢查任務的可行性。機器學習是一種很好的方式,可以用來生成一個非常大且模糊的、很難用人工的方法寫下來的規則集。但如果一開始你就很難寫下一套合理的規則來完成你的任務,那這通常是一個不好的迹象。然後,收集一個小資料集并嘗試使用你學習到的系統。接下來是一個稍微大一點的資料集,并且在你獲得表現提升時繼續這樣做。一個重要的經驗法則就是:準确度随着資料集大小的對數而增長。
永遠不要相信高得出奇的準确性:任何超過 95 或 97% 的數值。同樣地,不要相信任何高于人類輸出平的準确性,或者高于一緻性評價。很大機率上,要麼是資料集有缺失,有麼是評估不完善。兩者都經常發生,即使是對于經驗豐富的研究人員
你在網上看到的所有和機器學習有關的内容(新聞,部落格,論文),如果沒有其它作證那它們都是有歧義或錯誤的——包括現在這篇。
謝謝你的閱讀! 另外再說一下,謝謝大家給我們上一篇文章的留言。看到社群中的大家一起參與進來真的感覺很棒。
和往常一樣,如果你有任何問題、意見或回報,請發送電子郵件至 [email protected]。填寫系統資料庫格訂閱,我們将直接發送這些文章到你的郵箱,并通路我們的首頁 eloquent.ai。如果能這麼做的話我就很滿足了。回聊!
via blog.eloquent.ai,雷鋒網(公衆号:雷鋒網) AI 科技評論編譯