Accuracy: 準确率
機器學習的常用評價名額。定義如下:
Accuracy = (TruePositives + TrueNegatives) / 總樣本數
經常和準确率一起出現的,還有精确率和召回率。
- 精确率(Precision) = TP / (TP + FP)。它表示:預測為正的樣本中有多少是真正的正樣本,它是針對我們預測結果而言的。Precision又稱為查準率。
- 召回率(Recall) = TP / (TP + FN)。它表示:樣本中的正例有多少被預測正确了, 它是針對我們原來的樣本而言的。Recall又稱為查全率。
Activation function: 激活函數
一種函數(例如 ReLU 或 Sigmoid),将前一層所有神經元激活值的權重和輸入到一個非線性函數中,然後向下一層傳遞該函數的輸出值(典型的非線性)。
如下圖,在神經元中,輸入的 inputs 通過權重,求和後,還被作用了一個函數,這個函數就是激活函數 Activation Function。
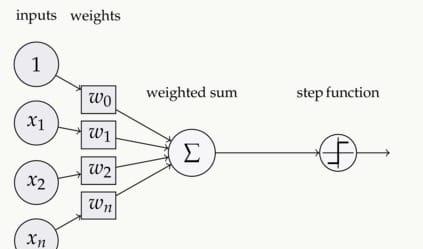
image
常見的激活函數有:sigmoid、Tanh、ReLU、softmax等
Adagrad:一種優化算法
Adagrad是一種複雜的優化算法(梯度下降算法),它能夠在疊代過程中不斷地自我調整學習率,并讓模型參數中每個元素都使用不同學習率。
AUC: 曲線下面積
AUC(Area Under Curve)也是一種常見的機器學習評價名額,和ROC(Receiver Operating Characteristic)曲線一起常被用來評價一個二值分類器(binary classifier)的優劣。相比準确率、召回率、F-score這樣的評價名額,ROC曲線有這樣一個很好的特性:當測試集中正負樣本的分布變化的時候,ROC曲線能夠保持不變。在實際的資料集中經常會出現類不平衡(class imbalance)現象,即負樣本比正樣本多很多(或者相反),而且測試資料中的正負樣本的分布也可能随着時間變化。
AUC值是一個機率值,當你随機挑選一個正樣本以及一個負樣本,目前的分類算法根據計算得到的Score值将這個正樣本排在負樣本前面的機率就是AUC值。AUC值越大,目前的分類算法越有可能将正樣本排在負樣本前面,即能夠更好的分類。
如果你覺得還有其他核心基礎詞彙,歡迎評論補充。
![查找算法之二分查找查找算法之二分查找[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)