一、re子產品
re中文為正規表達式,是字元串處理的常用工具,通常用來檢索和替換符合某個模式的文本。
注:要搜尋的模式和字元串都可以是unicode字元串(str)和8位字元串(bytes),但是不能将unicode字元串與位元組模式比對。
用途:1.資料驗證:測試輸入的字元串是否符合規定的模式
2.替換文本:識别文檔中的特定文本,删除或替代
3.提取字元串
常用比對模式:
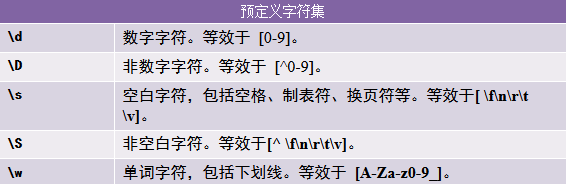

貪婪模式與非貪婪模式:
貪婪模式:總是比對盡可能多的字元
非貪婪模式:比對盡可能少的字元
使用findall的方式示範:
# 小寫w 比對【a-zA-Z0-9_】 大寫W 比對非字母數字下劃線 【^a-zA-Z0-0】
print(re.findall('\w','hello eg-on 1_23')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
print(re.findall('\W','hello egon 123')) #[' ', ' ']
#小寫\s 比對任意空白字元【\t\r\n\f】 大寫\S 比對任意非空字元
print(re.findall('\s','hello eg-on 1_23')) #[' ', ' ', ' ', ' ']
print(re.findall('\s','hello \n eg-on \t 1_23')) #[' ', '\n', ' ', ' ', '\t', ' ']
print(re.findall('\S','hello eg-on 1_23')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
#\n與\t 比對一個換行符和一個制表符
print(re.findall(r'\n','hello egon \n123')) #['\n']
print(re.findall(r'\t','hello egon\t123')) #['\n']
#\d比對任意數字【0-9】 \D比對任意非數字
print(re.findall('\d','hello \n e_g-on 123')) #['1', '2', '3']
print(re.findall('\D','hello \n e_g-on 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' ']
# \A==>^ \Z==>$
print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^
print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$
#^ 開頭 $結尾
print(re.findall('^h','hello egon 123')) #['h']
print(re.findall('3$','hello egon 123')) #['3']
# .比對除\n外的任意字元
print(re.findall('a.b','a1b')) #['a1b']
print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab']
print(re.findall('a.b','a\nb')) #[]
print(re.findall('a.b','a\nb',re.S)) #['a\nb']
print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一條意思一樣
#* 比對前一個字元>=0次
print(re.findall('ab*','bbbbbbb')) #[]
print(re.findall('ab*','a')) #['a']
print(re.findall('ab*','abbbb')) #['abbbb']
#+比對前一個字元>=1次
print(re.findall('ab+','a')) #[]
print(re.findall('ab+','abbb')) #['abbb']
#? 比對一個字元0或者一次
print(re.findall('ab?','a')) #['a']
print(re.findall('ab?','abbb')) #['ab']
#比對所有包含小數在内的數字
print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3']
#.*預設為貪婪比對
print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b']
#.*?為非貪婪比對:推薦使用
print(re.findall('a.*?b','a1b22222222b')) #['a1b']
#{n,m}
print(re.findall('ab{2}','abbb')) #['abb']
print(re.findall('ab{2,4}','abbb')) #['abb']
print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+'
print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*'
#[]
print(re.findall('a[1*-]b','a1b a*b a-b'))#['a1b', 'a*b', 'a-b']
print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,是以結果為['a=b']
print(re.findall('a[0-9]b','a1b a*b a-b a=b'))
print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb'))
print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb'))
#():分組
print(re.findall('ab*','abababsaa123')) #['ab', 'ab', 'ab']
print(re.findall('(ab)+123','ababab123')) #['ab'],比對到末尾的ab123中的ab
print(re.findall('(?:ab)+123','ababab123')) #findall的結果不是比對的全部内容,而是組内的内容,?:可以讓結果為比對的全部内容
print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">點選</a>'))#['http://www.baidu.com']
print(re.findall('href="(?:.*?)"','<a href="http://www.baidu.com">點選</a>'))#['href="http://www.baidu.com"'] re常用方法:
import re
#1
print(re.findall('e','alex make love') ) #['e', 'e', 'e'],傳回所有滿足比對條件的結果,放在清單裡
#2
print(re.search('e','alex make love').group()) #e,隻到找到第一個比對然後傳回一個包含比對資訊的對象,該對象可以通過調用group()方法得到比對的字元串,如果字元串沒有比對,則傳回None。
#3
print(re.match('e','alex make love')) #None,同search,不過在字元串開始處進行比對,完全可以用search+^代替match
#4
print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再對''和'bcd'分别按'b'分割
#5
print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,預設替換所有
print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love
print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love
print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex
print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),結果帶有總共替換的個數
#6
obj=re.compile('\d{2}')
print(obj.search('abc123eeee').group()) #12
print(obj.findall('abc123eeee')) #['12'],重用了obj 同樣的表達式,search和findall的結果不同:
print(re.search('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))").group()) #(-40.35/5)
print(re.findall('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))")) #['/5', '*3']
#看這個例子:(\d)+相當于(\d)(\d)(\d)(\d)...,是一系列分組
print(re.search('(\d)+','123').group()) #group的作用是将所有組拼接到一起顯示出來
print(re.findall('(\d)+','123')) #findall結果是組内的結果,且是最後一個組的結果
search與findall View Code
補充:
在 python 的字元串中,\ 是被當做轉義字元的。在正規表達式中,\ 也是被當做轉義字元。這就導緻了一個問題:如果你要比對 \ 字元串,那麼傳遞給 re.compile() 的字元串必須是"\\\\"。
由于字元串的轉義,是以實際傳遞給 re.compile() 的是"\\",然後再通過正規表達式的轉義,"\\" 會比對到字元"\"。這樣雖然可以正确比對到字元 \,但是很麻煩,而且容易漏寫反斜杠而導緻 Bug。
原始字元串很好的解決了這個問題,通過在字元串前面添加一個r,表示原始字元串,不讓字元串的反斜杠發生轉義。那麼就可以使用
r"\\"
來比對字元
\
了。
二、subprocess子產品
用于執行系統指令
常用方法:
run:傳回一個表示執行結果的對象
call:傳回的執行的狀态碼
總結:subprocess的好處是可以擷取指令的執行結果
subprocess執行指令時,可以在子程序中 這樣避免造成主程序卡死
補習内容:
import re
# 1)普通的字元
# res = re.match(r'a', 'abc')
# print(res.group())
# 2)單個(非換行\n)任意字元 .
# res = re.match(r'.', 'abc')
# print(res.group())
# 3)字元集(單個) [...] eg: [abc] [a-z] [a-zA-Z0-9_]
# res = re.match(r'[a-zA-Z0-9_]', 'babc') #a-z或A-Z或0-9或_ == \w
# print(res.group())
# 4)非\w的所有字元\W 拓展:\d \D \s \S
# res = re.match(r'\W', '$babc')
# print(res.group())
# 5)開頭、結尾(隻适用于單行比對) ^ $
ts = """abc
123
a1d
"""
res = re.match(r'^a', ts)
print(res)
# match 不與 $結合使用:比對整個字元串的開頭,隻比對一次
# search 可以與 $結合使用:比對整個字元串(不限定從頭開始),隻比對一次
# res = re.search(r'd$', ts)
# print(res)
# res = re.match(r'^a[\w]c$', "a_c")
# print(res)
# 6) 次數
# *[0, +œ) 盡可能多的比對
# *? 盡可能少的比對
# +[1, +œ) | ?[0, 1] | +? | ??
res = re.match(r'ab*?', "abbbbbc")
print(res)
# {m} 比對m次 {m,n} 比對m~n {m,n}?
# res = re.match(r'ab{2,5}', "abbbbb")
# print(res)
# 7)或 | a|b == [ab]
# res = re.match(r'a|b', "cbabc")
# print(res) # 方法
# match
# search
# findall
# sub
# split
import re
# 從頭開始,比對一次(沒有比對到傳回None)
# res = re.match(r'a', "abc")
# print(res)
# 比對一次,無關位置,從前往後索引比對(沒有比對到傳回None)
res = re.search(r'a', "baca")
print(res)
# 從前往後索引比對,比對所有,傳回清單(沒有比對到傳回[])
res = re.findall(r'a', "baca")
print(res)
# 正則 替換字元串 目标字元串
# 不修改目标字元串,傳回替換後的字元串
# ts = "abcdea"
# res = re.sub(r'[0-9]', "呵", "a2b12e9a")
# print(res)
# 以正則拆分成資料清單
# ts = "老男孩:python,Linux、H5、Java GO C++ AR VR"
# res = re.split(r' |:|,|、', ts)
# print(res) # 分組()
# 1)分組不影響比對結果 ((a(b)c)d(efg)) ==> abcdefg
# 2)0分組代表整體,第幾個(就是第幾位分組
import re
reg = r"((a(b)c)d(efg))"
ts = "abcdefg"
res = re.match(reg, ts)
print(res.group()) # abcdefg
print(res.group(0)) # abcdefg
print(res.group(1)) # abcdefg
print(res.group(2)) # abc
print(res.group(3)) # b
print(res.group(4)) # efg
# \num:num為分組号 \1 == book>
# reg = r"<(book>)(\w+)</\1"
# ts = "<book>國文</book>"
# res = re.match(reg, ts)
# print(res)
# (?P<mark>主體) (?P=mark)不占有分組
# reg = r"<(?P<tag>book>)(\w+)</(?P=tag)"
# ts = "<book>國文</book>"
# res = re.match(reg, ts)
# print(res.group(2))
# (?:) 取消分組
# [('國文', '</book>'), ('數學', '</book>')]
# reg = r"(?:<book>)(\w+)(</book>)"
# ts = "<book>國文</book><book>數學</book>"
# res = re.findall(reg, ts)
# print(res) 焚膏油以繼晷,恒兀兀以窮年。