通用技巧
有些技巧對你來說可能就是明擺着的事,但在某些時候可能卻并非如此,也可能存在不适用的情況,甚至對你的特定任務來說,可能不是一個好的技巧,是以使用時需要務必要謹慎!
使用 ADAM 優化器
确實很有效。與更傳統的優化器相比,如 Vanilla 梯度下降法,我們更喜歡用ADAM優化器。用 TensorFlow 時要注意:如果儲存和恢複模型權重,請記住在設定完AdamOptimizer 後設定 Saver,因為 ADAM 也有需要恢複的狀态(即每個權重的學習率)。
ReLU 是最好的非線性(激活函數)
就好比 Sublime 是最好的文本編輯器一樣。ReLU 快速、簡單,而且,令人驚訝的是,它們工作時,不會發生梯度遞減的情況。雖然 sigmoid 是常見的激活函數之一,但它并不能很好地在 DNN 進行傳播梯度。
不要在輸出層使用激活函數
這應該是顯而易見的道理,但如果使用共享函數建構每個層,那就很容易犯這樣的錯誤:是以請確定在輸出層不要使用激活函數。
請在每一個層添加一個偏差
這是 ML 的入門知識了:偏差本質上就是将平面轉換到最佳拟合位置。在 y=mx+b 中,b 是偏差,允許曲線上下移動到“最佳拟合”位置。
使用方差縮放(variance-scaled)初始化
在 Tensorflow 中,這看起來像tf.reemaner.variance_scaling_initializer()。根據我們的經驗,這比正常的高斯函數、截尾正态分布(truncated normal)和 Xavier 能更好地泛化/縮放。
粗略地說,方差縮放初始化器根據每層的輸入或輸出數量(TensorFlow中的預設值是輸入數量)調整初始随機權重的方差,進而有助于信号更深入地傳播到網絡中,而無須額外的裁剪或批量歸一化(batch normalization)。Xavier 與此相似,隻是各層的方差幾乎相同;但是不同層形狀變化很大的網絡(在卷積網絡中很常見)可能不能很好地處理每層中的相同方差。
歸一化輸入資料
對于訓練,減去資料集的均值,然後除以它的标準差。在每個方向的權重越少,你的網絡就越容易學習。保持輸入資料以均值為中心且方差恒定有助于實作這一點。你還必須對每個測試輸入執行相同的規範化,是以請確定你的訓練集與真實資料相似。
以合理保留其動态範圍的方式縮放輸入資料。這與歸一化有關,但應該在歸一化之前就進行。例如,真實世界範圍為 [0,140000000] 的資料 x 通常可以用 tanh(x) 或 tanh(x/C) 來控制,其中 C 是一些常數,它可以拉伸曲線,以适應 tanh 函數緩坡部分的動态範圍内的更多輸入範圍。特别是在輸入資料在一端或兩端可能不受限制的情況下,神經網絡将在(0,1)之間學習得更好。
一般不用學習率衰減
學習率衰減在 SGD 中更為常見,但 ADAM 很自然地處理了這個問題。如果你真的想把每一分表現都擠出去:在訓練結束時短時間内降低學習率;你可能會看到突然的、非常小的誤差下降,然後它會再次變平。
如果你的卷積層有 64 或 128 個過濾器,那就足夠了。特别是一個對于深度網絡而言。比如,128 個真的就已經很多了。如果你已經有了大量的過濾器,那麼再添加更多的過濾器未必會進一步提高性能。
池化用于平移不變性
池化本質上就是讓網絡學習圖像“那部分”的“總體思路”。例如,最大池化可以幫助卷積網絡對圖像中的特征的平移、旋轉和縮放變得更加健壯。
調試神經網絡
如果你的網絡沒能很好地進行學習(指在訓練過程中損失/準确率沒有收斂,或者沒有得到預期的結果),那麼可以試試以下的技巧:
過拟合
如果你的網絡沒有學習,那麼首先要做的第一件事就是對訓練點進行過拟合。準确率基本上應為 100% 或 99.99%,或誤差接近 0。如果你的神經網絡不能對單個資料點進行過拟合,那麼體系架構就可能有嚴重的問題,但這可能是微妙的。如果你可以對一個資料點進行過拟合,但是對較大的集合進行訓練仍然無法收斂,請嘗試以下建議:
降低學習率
你的網絡學習就會變得更慢一些,但是它可能會找到以前無法進入的最小化的方式,因為它的步長太大了。
提高學習率
這樣做将會加快訓練,有助于收緊回報,這意味着無論你的網絡是否正常工作,你都會很快地知道你的網絡是否有效。雖然網絡應該更快地收斂,但其結果可能不會很好,而且“收斂”實際上可能會跳來跳去。(對于 ADAM 優化器,我們發現在很多經曆中,學習率大約為 0.001 時,表現很不錯。)
減少批量處理規模
将批處理大小減小到 1,可以為你提供與權重更新相關的更細粒度的回報,你應該使用TensorBoard(或其他一些調試/可視化工具)展示出來。
删除批歸一化層
随着批處理大小減少到 1,這樣做會暴露出梯度消失或梯度爆炸的問題。我們曾有過一個網絡,在好幾周都沒有收斂,當我們删除了批歸一化層之後,我們才意識到第二次疊代時輸出都是 NaN。就像是Ok繃上的吸水墊,它也有它可以發揮效果的地方,但前提是你知道網絡沒有 Bug。
增加批量處理的規模
一個更大的批處理規模,如果可以的話,整個訓練集減少梯度更新中的方差,使每個疊代更準确。換句話說,權重更新将朝着正确的方向發展。但是!它的可用性和實體記憶體限制都有一個有效的上限。通常,我們發現這個建議不如上述兩個建議有用,可以将批處理規模減少到1并删除批歸一化層。
檢查你的重構
大幅度的矩陣重構(如改變圖像的X、Y 次元)會破壞空間局部性,使網絡更難學習,因為它也必須學會重塑。(自然特征變得支離破碎。事實上,自然特征在空間上呈局部性,也是為什麼卷積神經網絡能如此有效的原因!)如果使用多個圖像/通道進行重塑,請特别小心;使用 numpi.stack()進行适當的對齊操作。
仔細檢查你的損失函數
如果使用一個複雜的函數,請嘗試将其簡化為 L1 或 L2。我們發現L1對異常值不那麼敏感,在發出噪聲的批或訓練點時,不會做出太大的調整。
如果可以的話,仔細檢查你的可視化。你的可視化庫(matplotlib、OpenCV等)是調整值的比例呢,還是它們進行裁剪?可考慮使用一種視覺上均勻的配色方案。
實戰分析
為了使上面所描述的過程更容易讓讀者了解,我們這兒有一些用于描述我們建構的卷積神經網絡的真實回歸實驗的損失圖(通過TesnorBoard)。
起初,這個網絡根本沒有學習:
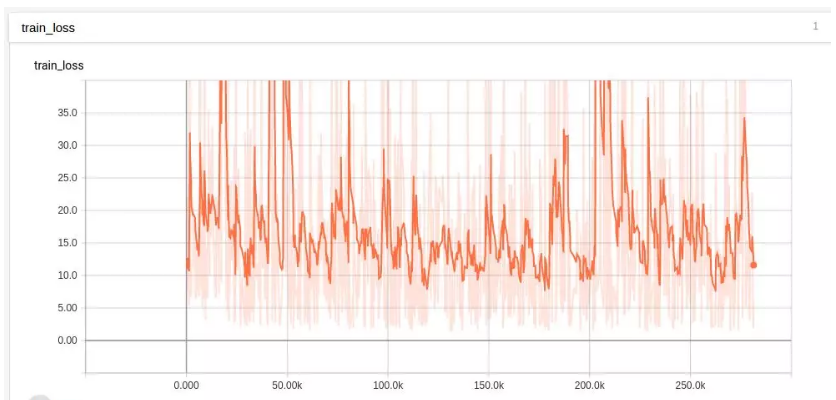
我們試圖裁剪這些值,以防止它們超出界限:

嗯。看看不平滑的值有多瘋狂啊!學習率是不是太高了?我們試着在一個輸入資料上降低學習率并進行訓練:
你可以看到學習率的前幾個變化發生的位置(大約在 300 步和 3000 步)。顯然,我們衰減得太快了。是以,給它更多的衰減時間,它表現得會更好:
你可以看到我們在 2000 步和 5000 步的時候衰減了。這樣更好一些了,但還不夠好,因為它沒有趨于 0。
然後我們禁用了 LR 衰減,并嘗試将值移動到更窄的範圍内,而不是通過 tanh 輸入。雖然這顯然使誤內插補點小于 1,但我們仍然不能對訓練集進行過拟合:
這裡我們發現,通過删除批歸一化層,網絡在一到兩次疊代之後迅速輸出 NaN。我們禁用了批歸一化,并将初始化更改為方差縮放。這些改變了一切!我們能夠對隻有一兩個輸入的測試集進行過拟合了。當底部的圖示裁剪Y軸時,初始誤內插補點遠高于 5,表明誤差減少了近 4 個數量級:
上面的圖表是非常平滑的,但是你可以看到它非常快地拟合了測試輸入,随着時間的推移,整個訓練集的損失降低到了 0.01 以下。這沒有降低學習速度。然後我們将學習速率降低一個數量級後繼續訓練,得到更好的結果:
這些結果好得多了!但是,如果我們以幾何方式降低學習率,而不是将訓練分成兩部分,會發生什麼樣的結果呢?
通過在每一步将學習率乘以 0.9995,結果就不那麼好了:
大概是因為學習率衰減太快了吧。乘數為 0.999995 會表現的更好,但結果幾乎相當于完全沒有衰減。我們從這個特定的實驗序列中得出結論,批歸一化隐藏了由槽糕的初始化引起的爆炸梯度,并且 ADAM 優化器對學習率的衰減并沒有什麼特别的幫助,與批歸一化一樣,裁剪值隻是掩蓋了真正的問題。我們還通過 tanh 來控制高方差輸入值。
我們希望,本文提到的這些基本技巧能夠在你建構深度神經網絡時有所幫助。通常,正式因為簡單的事情才改變了這一切。
原文釋出時間為:2018-09-19
本文來自雲栖社群合作夥伴“C
DA資料分析師”,了解相關資訊可以關注“
”。