DataWorks基于MaxCompute作為核心的計算、存儲引擎,提供了海量資料的離線加工分析、資料挖掘的能力。通過DataWorks,可對資料進行資料傳輸、資料轉換等相關操作,從不同的資料存儲引入資料,對資料進行轉化處理,最後将資料提取到其他資料系統。在本文中,阿裡巴巴計算平台産品專家祎休為大家介紹了通過DataWorks進行新增排程資源、排程資源管理、配置不同周期任務依賴等最佳實踐。
直播視訊回看,戳這裡! 分享資料下載下傳,戳這裡! 更多精彩内容傳送門: 大資料計算技術共享計劃 — MaxCompute技術公開課第二季 以下内容根據演講視訊及PPT整理而成。大家在使用MaxCompute的時候更多地是在DataWorks上面實作基于ETL加工、排程、配置以及雲上數倉的建構任務。本文将與大家分享DataWorks背景強大排程系統的實作邏輯以及一些具體的實作案例,希望能夠對大家在做雲上數倉相關工作時有所幫助。
本次分享主要分成3個部分,在第一部分是排程的基本介紹,主要為大家分享DataWorks的基本概念,這部分将幫助大家了解後續的依賴關系。第二部分将與大家分享依賴關系的簡介,比如自依賴、跨周期依賴以及版本依賴等,以及這些依賴之間會在背景生成什麼樣的執行個體等。最後一部分将與大家分享依賴關系的實戰,為大家剖析兩個案例,并回顧本次分享的内容。總體上而言,通過本次分享希望能夠幫助大家區分DataWorks和MaxCompute的不同點,讓大家更好地了解DataWorks的定位是MaxCompute之上雲上數倉的開發工具。
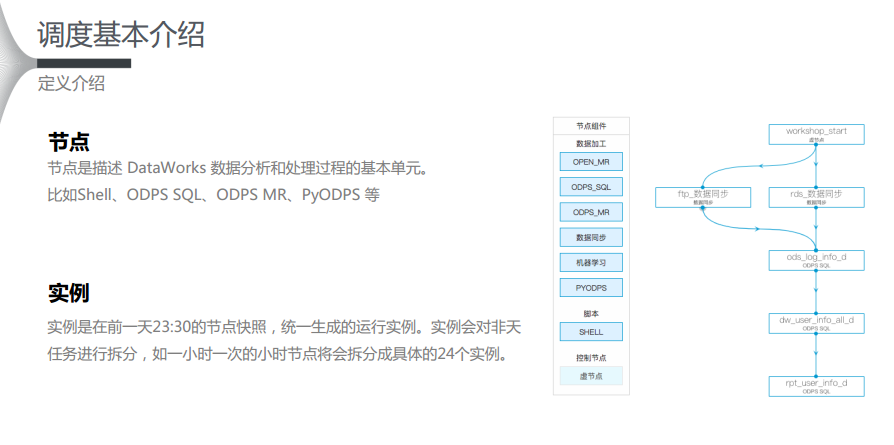
一、排程基本介紹首先需要明确兩個概念:節點和執行個體。如下圖左側所示,節點是描述DataWorks資料分析和處理過程的基本單元,比如Shell、ODPS SQL、ODPS MR、PyODPS等。而在Dataworks背景前一天23:30的節點會生成快照,統一生成的運作執行個體。對于使用者而言,在配置排程上的最大感觸就是在23:30分之前送出的排程配置,會在23:30分之後生效,而在23:30分之後配置的一些依賴關系隻能夠間隔一天再統一地生成執行個體。執行個體會對非天任務進行拆分,如一小時一次的小時節點将會拆分成具體的24個執行個體。
此外,還需要明白兩個關系,就是排程規則和依賴關系。對于排程規則而言,首先需要滿足依賴關系,即上遊節點必須完成,才能排程下遊節點;其次,需要判斷定時的時間是否已經到了,如果到了就立即執行,如果沒有到,就需要等待時間。對于依賴關系而言,正如下圖中右側所示,是描述兩個或多個節點之間的語義連接配接關系,其中上遊節點的狀态将影響其他下遊節點的運作狀态,反之則不成立。

此外,還需要為大家介紹跨周期依賴和自依賴關系。在如下圖右側的欄目去打開就能看到,跨周期的依賴有很多選項,在這些選項背後有很多的概念。第一個就是跨周期依賴,這其實也分了跨周期和跨版本的兩個概念,如何了解呢?其實,跨周期依賴是針對小時任務的,也就是小時任務依賴同一天的上一個周期。比如每個節點按照小時進行排程,那目前的節點能否排程起來需要依賴于上一個周期是否成功傳回了。另外一部分就是跨版本依賴,這種依賴就是針對于天依賴的任務做的,比如今天任務能否成功運作依賴于昨天的任務能否成功傳回,這裡更多的會有一些資料的先後依賴關系,是以在這部分需要做跨版本的依賴配置。而自依賴可以了解成為跨周期和跨版本的依賴,針對于天任務,如果配置了自依賴,那麼就是會依賴于昨天版本的執行個體。針對于小時任務,就會依賴于每天的最後一個周期。
在依賴關系裡面,可以通過整體的架構圖來看。在WorkFlow裡面可以看到,屬性裡面有一個當機的概念,周期執行個體中的當機隻針對目前執行個體,且正在運作中的執行個體,當機操作無實際效果,并不會殺掉正在運作的執行個體。當機狀态的任務會生成執行個體,但是不會運作,可以了解為空跑狀态。如果需要運作當機的執行個體,需要解凍執行個體,單擊重跑,執行個體才會開始運作。
在公共雲上,如果開啟了出錯機制,那麼預設會重試3次,每次間隔2分鐘,如果經曆了3次重試還是失敗,那麼就會傳回失敗狀态。
對于排程屬性而言,DataWorks有5種排程周期,分别是分鐘、小時、日、周和月。如果周期大于天的,那麼由于排程的執行個體劃分時按天生成的,是以周月任務在不運作的哪一天實際是按照空跑處理的。如果選擇日排程,而且不勾標明時排程的,定時時間統一按照0點處理。
此外,跨周期依賴裡面有4個選項,他們分别對應了不同的概念。比如“不依賴上一排程周期”就是其不會形成跨周期和版本的依賴關系,而如果勾選了“自依賴”,那麼就會依賴目前節點的上一周期,隻有當上一周期運作結束并且傳回成功,目前節點才能運作。另外一部分,如果選擇了如圖所示的,依賴于“一層子節點”或者等待“下遊任務的上一周期結束”才能運作。此外,還能自定義一些節點,當然在節點裡面可以輸入節點ID或者名稱與一些自定義的任務進行依賴關系配置。而如果勾選了“等待自定義任務的上一周期結束,才能繼續運作”,這樣目前的工作流任務就會等待依賴的任務節點結束才會運作。
如下圖所示,大家可以在DataWorks運維中心裡面看到每天生成的運作執行個體的圖。這與開發面闆不太一樣,如果存在實作的上下遊依賴關系,那麼就是正常的依賴關系,而有虛線的就是跨周期或者自依賴的關系。從這些可以判斷,一些使用者配置了自依賴,如果發現今天的任務沒有跑起來,就需要去追溯昨天的任務是否運作正常,如果昨天的任務也沒有正常運作就需要繼續向上追溯。
如下所示的整頁圖裡面是天任務的互相依賴,箭頭表示的資料流向。如果根據下圖将箭頭反方向調整就可以了解成依賴關系,也就是下遊會依賴上遊。現在箭頭則表示資料的流向,假設現在有兩個天排程的任務,兩個都是淩晨開始運作的,那麼當上遊任務成功運作了,下遊才會運作起來,而且如果上遊任務沒有運作完成,下遊任務即使定時時間到了也無法運作。
在下圖中可以看出,天任務可以互相依賴,上遊存在跨周期依賴。如果下遊任務想要成功執行,就需要上遊任務成功運作作為前提。下圖中可以看出,2014年和2015年的兩個執行個體分别存在互相依賴關系,上遊的任務會依賴上一周期的一層子節點,如果上遊昨天的任務未成功運作,那麼就會阻塞昨天的任務和今天的下遊任務。
如下圖所示的小時任務比較流行,大家可能會經常配置6個小時或者8個小時的任務,這樣會生成3至4個執行個體,這樣隻要一個周期未成功,後續的所有周期都會阻塞,并且可以有效避免一個周期任務運作慢了導緻後續周期定時到了之後并發運作。
從下圖中可以看出,是小時任務依賴天任務。在左側中是2014年12月31日的情況,執行個體B1、B2和B3都會依賴執行個體A,執行個體A是12點運作,而執行個體B1、B2以及B3都是小時任務,是以需要依賴天任務,需要等待天任務完成之後才能運作。而當定時的時間到了,這些任務才會并發地執行,在這裡就是上遊執行個體A成功運作了,下遊的B1、B2和B3才能同時并發地執行。
執行個體A是執行個體B1、B2和B3的下遊節點,也就是說執行個體A依賴于上遊的幾個小時任務節點。這樣一來,天任務就需要等待小時任務的所有周期都完成了才能去排程這樣的天任務,是以如果按照每8個小時跑一個小時任務,這樣就能夠拆分成3個執行個體,隻有當這些小時執行個體都成功運作之後,下遊的天任務才能在時間已經到了的情況下運作起來。
比如上遊節點是小時任務,下遊的節點也是小時任務,當這兩個小時任務都是按照每幾個小時生成時,其生成的執行個體數是一樣的,在這種情況下可以了解為父子節點都是小時任務,同時其周期數也是一樣的。而每一個運作的執行個體都會形成一個一一對應的關系。當然,若下遊的定時晚于上遊的定時,在下遊定時時間到了的時候也不能排程,需要等待上遊對應的周期完成之後才能開始排程。
在這種情況下,可能上遊按照12個小時運作一次,那麼一天可能會生成兩個執行個體,下遊則可能每天按照6個小時,那麼這個時候可能生成6個執行個體。其實,可以從圖中看出其是如何依賴的關系,小時任務依賴小時任務,如果其周期數不同,如果下遊周期數大于上有的周期數,則會依據就近原則挂依賴,也就是時間小于或者等于自己且不重複的依賴。
在如下圖所示的任務依賴中,箭頭表示了資料的流向。之前案例也講到,如果上遊天任務完成時下遊有多個周期定時時間已到,會導緻這些周期被并發排程起來,如果不希望下遊并發排程起來,則需要将下遊小時任務設定成自依賴,即依賴上一周期,也就是本節點,這樣形成一個自依賴。需要注意的是,自依賴會依賴跨版本(跨天),如果昨天最後一個周期未完成,會導緻今天的任務無法排程。如下圖所示,執行個體A屬于天任務,而下遊執行個體B則是每8小時執行一次的小時任務,執行個體B之間則會有一些虛線的依賴關系。比如執行個體A在12點運作成功了,那麼執行個體B在運作的時候需要先去判斷執行個體A的狀态與自己的定時時間,生成完之後才會依次執行B2、B3,而當出現了跨天的情況,比如執行到B4的時候,需要去判斷昨天最後一個執行個體的狀态。
在下圖裡面,箭頭表示依賴關系。如果天任務依賴小時任務,需要等待小時任務的所有周期都完成了才能開始排程。比如在上遊按照每小時運作一次的資料,等所有資料都落入到對應的分區之後,再按照一定的資料彙總24小時的資料。如果需要天任務盡量按照定時時間開始排程。則可以配置上遊小時任務自依賴,待上遊小時任務定時時間最近(且小于)的周期完成後,下遊天任務就會被排程。
小時任務依賴天任務且天任務存在跨周期依賴,則小時任務的所有周期都會依賴昨天的天任務。
對于這樣的情況需要配置依賴一層子節點,比如上遊的小時任務跨周期依賴下遊的定時天任務,效果即上遊小時任務會在每一周期都會依賴上一版本的下遊任務。
這種情況比較複雜,圖中的實線表示依賴關系,虛線則表示自依賴關系。為了實作這樣的依賴關系,需要在下遊節點設定依賴自定義節點(父節點ID)。在這個case比較特别,即可看出其實這個依賴圖中存在兩個概念,既有跨周期(依賴上遊小時任務的上一周期),又存在跨版本(依賴上遊小時任務的上一版本的所有周期)。
首先對于定義關系圖而言,上遊三個節點,下遊一個節點這樣的情況而言,在每天23:30分會生成一個節點快照,生成一個可運作的執行個體。當執行個體運作的時候,會依次運作上遊的各個節點,當各個節點全部運作成功了之後,下遊節點就會判斷是否已經到了自己能夠執行的時間,如果符合執行條件就會去執行。而如果上遊任何一個節點執行失敗了,就會導緻下遊節點一直處于等待狀态。
和之前的依賴關系對比,可以看到有了自依賴後,跨周期依賴的邊少了很多。這是因為如果有了自依賴,目前周期成功的前提必須是前一個周期成功了,于是下遊跨周期并跨版本依賴就減少成了跨周期依賴。
在天任務依賴小時任務的場景下,系統需求統計截止到每小時的業務資料增量,然後在最後一個小時的資料彙總完成後,需要一個任務進行一整天的彙總。對于這樣的場景進行需求分析得到以下兩點:
1)每個小時的增量,即每整點起任務統計上個小時時間段的資料量。需要配置一個每天每整點排程一次的任務,每天最後一個小時的資料是在第二天第一個執行個體進行統計。
2)最後的彙總任務為每天執行一次,且必須是在每天最後一個小時的資料統計完成之後才能執行,那麼需要配置一個天任務,依賴小時任務的第一個執行個體。
如下圖中左側所示,可能期望的結果就是在排程任務的定義時,上遊是小時任務,每個小時運作一次,下遊是天任務,每天淩晨開始運作,就形成了這樣的依賴關系。而對于綠色的圖而言,對應的任務執行個體的狀況,隻有當每天最後一個小時任務處理完成之後,才會去處理天任務。而當真正按照這種依賴關系進行配置,直接挂靠這種依賴關系,在排程系統中會生成右側所示的執行個體,但是這是不符合預期的。
而如果想要達到整體的需求,就需要配置上遊小時任務的自依賴。如果上遊的小時任務形成自依賴,那麼上遊的24個小時任務執行個體就會按照下圖左側中的執行個體進行依賴,當小時任務都生成之後才會去運作天任務。對于這樣的依賴關系,隻需要去DataWorks裡面選擇跨周期依賴的自依賴就可以了。
對于小時任務依賴分鐘任務而言,有這樣的一種業務場景:已經有任務每30分鐘進行一次同步,将前30分鐘的系統資料增量導入到MaxCompute,任務定時為每天的每個整點和整點30分運作。現在需要配置一個小時任務,每6個小時進行一次統計,即每天分别統計0點到6點之間、6點到12點之間、12點到18點之間、18點到明天0點整之間的資料。從分析來看,我們期望的效果就是如下圖中左側所示,上遊的分鐘任務,每隔30分鐘排程一次,下遊是小時任務,每隔6個小時排程一次,那麼對應的執行個體裡面就會産生對應的依賴關系。
在進行配置時需要選擇上遊的節點進行自依賴,在如下所示的依賴圖中可以看出,分鐘級别的依賴任務有自依賴,它會依賴上一周期的成功,并觸發下遊的小時任務的統計。