ELK+logback+kafka+nginx 搭建分布式日志分析平台
ELK(Elasticsearch , Logstash, Kibana)是一套開源的日志收集、存儲和分析軟體組合。而且不隻是java能用,其他的開發語言也可以使用,今天給大家帶來的是elk+logback+kafka搭建分布式日志分析平台。本文主要講解一下兩種流程,全程linux環境(模拟現實環境,可用記憶體一定要大于2G,當然也可以使用windows),至于elk這些元件的原理,百度太多了,我就不重複了,重在整合。
1.我們是通過logback列印日志,然後将日志通過kafka消息隊列發送到Logstash,經過處理以後存儲到Elasticsearch中,然後通過Kibana圖形化界面進行分析和處理。
2.我們使用Logstash讀取日志檔案,經過處理以後存儲到Elasticsearch中,然後通過Kibana圖形化界面進行分析和處理。例如我們讀取nginx的日志檔案,可以統計通路使用者的ip地域,請求位址等等。
一、文章案例環境
1.centos 7.2(linux)
2.elasticsearch / logstash / kibana 6.3.2
下載下傳位址3.nginx 1.12.2
4.kafka 2.12
5.logback/springboot 使用springboot2.0.4.RELEASE和預設的logback
6.zookeeper 3.4.12
二、安裝Elasticsearch
1.建立使用者
如果你是root使用者,要建立一個使用者,elasticsearch不允許root使用者登入,如果不是root登入請忽略這一步。
adduser elsearch
su elsearch
2.下載下傳安裝elasticsearch,以下簡稱es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
tar -zxvf elasticsearch-6.3.2.tar.gz
3.修改配置
進入es的config目錄,vi elasticsearch.yml,打開注釋并修改
#如果配置叢集的話,隻要name一樣就可以自動叢集了,不需要單獨配置
cluster.name: nelson
network.host: 0.0.0.0 #4個0表示外網可以通路
http.port: 9200 #預設http端口
transport.tcp.port: 9300 #預設tcp端口
vi jvm.options
修改一下記憶體配置,我這裡記憶體不是很多是以修改為450Mb,兩者保持一緻,如果你記憶體足夠,這個可以忽略。
-Xms450M
-Xmx450M
然後就可以啟動es,執行 /bin/elasticsearch 啟動的時候可能會有一些提示,比如修改一些配置等,複制提示然後百度就會找到解決方案。
4.測試
如果es啟動成功,可以通過浏覽器通路 ip:9200,下圖表示安裝成功,如果無法通路,檢查es是否成功啟動或者是否防火牆攔截
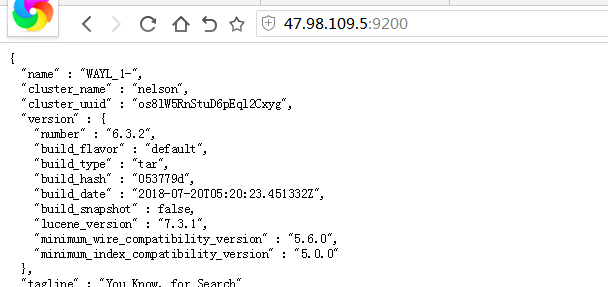
1.png
二、安裝Nginx
yum install -y nginx
然後
vi /etc/nginx/nginx.conf
修改nginx的日志預設輸出格式
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domian":"$host",'
'"host":"$server_addr",'
'"size":"$body_bytes_sent",'
'"responsetime":"$request_time",'
'"referer":"$http_referer",'
'"ua":"$http_user_agent"'
'}';
access_log /opt/access.log json;
安裝完成以後
service nginx start
啟動nginx服務
打開浏覽器通路 ip,nginx預設是80端口,如果可以通路表示成功安裝

2.png
三、安裝Logstash
1.下載下傳安裝 logstash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
tar -zxvf elasticsearch-6.3.2.tar.gz
2.修改記憶體
vi jvm.options
,記憶體足夠的話,跳過這一步
-Xms400M
-Xmx400M
3.配置輸入輸出
在config目錄下建立檔案nginx.conf
1)input表示輸入源,他這裡有好多插件,支援很多資料源包括檔案,http等,我們這裡首先收集nginx的日志。file表示讀取檔案;codec表示讀取的檔案格式,因為我們前邊配置了nginx的日志格式為json,是以這裡是json;start_position表示從那一行讀取,他會記錄上一次讀取到那個位置,是以就不用擔心遺漏日志了。type相當于一個tag一樣,可能這裡有很多輸入源,後面會根據這個type進行過濾。
2)filter表示處理輸入資料,因為我們前邊配置了nginx的日志裡邊記錄了使用者的ip,是以我們使用geoip元件,可以根據ip比對位置資訊,下面表示你将使用那些fields字段;source表示輸入json的那個屬性。
3)output表示輸出到哪裡,可以檔案、redis等,這裡我們儲存到es裡。利用elasticsearch插件,然後配置一下es的位址,索引我們是通過日期自動生成,表示每天建立一個索引
input {
file {
path => "/var/log/nginx/access.log"
type => "nginx"
codec => "json"
start_position => "beginning"
}
}
filter {
geoip {
fields => ["city_name", "country_name", "latitude", "longitude", "region_name","region_code"]
source => "client"
}
}
output {
if [type] == "nginx" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-nginx-%{+YYYY.MM.dd}"
}
stdout {}
}
}
4.啟動
進入到logstash 目錄執行以下指令,記得加-f
./bin/logstash -f ./config/nginx.conf
然後我們在浏覽器通路nginx,輸入ip就可以,這時候可以在控制台看到如下輸出。
3.png
四、安裝Kibana
1.下載下傳解壓
我買的伺服器記憶體隻有2G,是以我用的windows安裝的Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz
tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz
windows下載下傳位址,我這裡用的是windows
https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-windows-x86_64.zip2.修改配置
進入到config下,修改kibana.yml檔案,如果你的kibana和es在一台機器上請忽略這一步,如果不在一台機器上,放開注釋修改位址,我這裡是在windows上運作的。
elasticsearch.url: "http://localhost:9200"
//我的配置
//elasticsearch.url: "http://47.98.109.5:9200"
3.啟動
進入到kibana目錄下
//linux
./bin/kibana
//windows 輕按兩下運作bin目錄下的kibana.bat檔案
4.實戰
打開浏覽器通路
ip:5601
第一次進來我們要建立
index pattern
,因為我們的日志是按照日期每天存儲的,是以要将這些日志聚合到一起。按照下圖進行設定,因為我已經有4天的日志了,是以過濾後有四條滿足。
4.png
5.png
可以根據時間段過濾,檢視資料的錄入量,這也表示網站通路量。
6.png
當然也可以通過rest api查詢資料,支援複雜查詢。索引也可以使用通配符
7.png
5.統計使用者區域分布
我們要建立一個統計,然後選擇餅狀圖,下一步選擇你要統計的
index pattern
,這個在上一步已經建立成功
8.png
9.png
添加子查詢
10.png
最後我們來一個很複雜的統計,按照國家->城市->浏覽器類型,但是用kibana是很簡單的,而且速度超快。
11.png
到這裡利用elk分析nginx的日志就算完成了,剩下的自己研究,基本類似,一些基本概念還是要自己去百度了。
接下來是通過logback+kafka儲存程式日志。因為生産環境中,分布式系統,你的服務可能有N個,例如基于docker,我們不可能給每個docker容器裡安裝一個logstash,是以需要通過網絡向logbash傳輸資料。這裡是通過logback産生日志,然後通過kafka消息隊列傳輸到logstash。
五、安裝Zookeeper
kafka 是需要zookeeper的,下面簡稱zk。
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
tar -zxvf zookeeper-3.4.12.tar.gz
#複制配置
cp zoo_sample.cfg zoo.cfg
修改配置
vi zoo.cfg
dataDir=/root/zk/data #改為你zk目錄/data
然後進入zk目錄啟動,如果不儲存說明就啟動成功了。
./bin/zkServer.sh start
六、安裝Kafka
安裝解壓
wget http://mirror.bit.edu.cn/apache/kafka/2.0.0/kafka_2.12-2.0.0.tgz
tar -zxvf kafka_2.12-2.0.0.tgz
cd kafka_2.12-2.0.0
然後修改config目錄吓得server.properties,如果你的zk和你的kafka不在一台機器的話,你要修改zk的位址。
還有一點要注意的是如果你使用阿裡雲這一類産品的時候一定要注意下面配置,特别坑:
listeners=PLAINTEXT://172.31.167.25:9092 #阿裡雲内網位址
advertised.listeners=PLAINTEXT://47.104.255.217:9092 #阿裡雲外網位址
啟動kafka server
bin/kafka-server-start.sh config/server.properties
建立一個 名稱為applog 的topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic applog
檢視所有topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
消息的生産者,啟動以後,在控制台輸入資訊,然後回車發送
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic applog
消息的消費者,如果生産者那裡給applog這個top輸入資訊發送,消費者這邊就會在收到,然後在控制台列印出來。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic applog --from-beginning
接下來開發,我們隻需要啟動kafka server即可。上面這個消費者和生産者隻是為了測試。
七、程式中使用logback
我們建立一個springboot項目,然後加入如下依賴。coding位址:
點選通路compile('org.springframework.boot:spring-boot-starter-webflux')
compile('org.springframework.kafka:spring-kafka')
compile group: 'net.logstash.logback', name: 'logstash-logback-encoder', version: '5.2'
compile group: 'com.github.danielwegener', name: 'logback-kafka-appender', version: '0.1.0'
因為springboot自帶logback,是以我們也不需要手動增加依賴。然後我們在
resource
目錄下建立檔案
logback-spring.xml
,這樣話,springboot自動讀取配置檔案優先順序比較高,具體文章可以去springboot文檔去檢視。
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>logback</contextName>
<property name="log.path" value="logs/elk.log" />
<!--輸出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<!-- <filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>-->
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!--輸出到檔案-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logback.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!--輸出到kafka-->
<appender name="KafkaAppender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="com.github.danielwegener.logback.kafka.encoding.LayoutKafkaMessageEncoder">
<layout class="net.logstash.logback.layout.LogstashLayout" >
<includeContext>false</includeContext>
<includeCallerData>true</includeCallerData>
<customFields>{"system":"test"}</customFields>
<fieldNames class="net.logstash.logback.fieldnames.ShortenedFieldNames"/>
</layout>
<charset>UTF-8</charset>
</encoder>
<!--kafka topic 需要與配置檔案裡面的topic一緻 否則kafka會沉默并鄙視你-->
<topic>applog</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<producerConfig>bootstrap.servers=47.104.255.217:9092</producerConfig>
</appender>
<!--你可能還需要加點這個玩意兒-->
<logger name="Application_ERROR">
<appender-ref ref="KafkaAppender"/>
</logger>
<root level="info">
<appender-ref ref="console" />
<appender-ref ref="file" />
<appender-ref ref="KafkaAppender" />
</root>
</configuration>
然後我們建立controller
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
// 注意導包,不要導錯
@RestController
public class IndexController {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@RequestMapping("/")
public void index(){
logger.trace("日志輸出 trace");
logger.debug("日志輸出 debug");
logger.info("日志輸出 info");
logger.warn("日志輸出 warn");
logger.error("日志輸出 error");
}
}
這個時候我們需要,修改一下logback的配置檔案了,要加入kafka的輸入。修改logbstash的config目錄吓得nginx.conf
input {
#nginx日志的輸入
file {
path => "/opt/access.log"
type => "nginx"
codec => "json"
start_position => "beginning"
}
#kafka日志輸入
kafka {
topics => "applog"
type => "kafka"
bootstrap_servers => "47.104.255.217:9092"
codec => "json"
}
}
filter {
if [type] == "nginx" {
geoip {
fields => ["city_name", "country_name", "latitude", "longitude", "region_name","region_code"]
source => "client"
}
}
}
output {
#都輸出到es中,但是索引不一樣
if [type] == "nginx" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-nginx-%{+YYYY.MM.dd}"
}
stdout {}
}
if [type] == "kafka" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-applogs-%{+YYYY.MM.dd}"
}
stdout {}
}
}
然後執行
../bin/logstash -f ./nginx.conf
,啟動logstash,這時候我們的logstash就有兩個輸入源了。
通路項目中controller位址,看日志是否列印出來。
idea的控制台列印了日志
12.png
這是logstash列印出來的日志,如果這個出來基本可以說明成功了。
13.png
最後我們在kibana中通過rest請求es,這裡表示查到資料。
14.png
要是想統計日志,可以參考上邊kibanam那一塊,類似。
到這裡,本篇文章就結束了,elk+nginx 和 elk+logback+kafka都已經實作了,考慮篇幅,是以這裡沒有細講這些概念。這些呢就自行百度吧,不重複造輪子了,隻要能串通,剩下的用到啥看官方文檔或者百度。
關注
如果有問題,請在下方評論,或者加群讨論
200909980
關注下方微信公衆号,可以及時擷取到各種技術的幹貨哦,如果你有想推薦的文章,也可以聯系我們的。