幾行代碼,抱上IBM爸爸大腿,實作音頻快速轉文字~用到了IBM Waston的Speech to text(目前還是個demo)
碎碎念的廢話~
前幾天工作中遇到需要把音頻轉為文字稿的任務,順便學了個新詞語:扒詞。
扒詞:根據視訊資訊獲得文字資訊,即根據錄音或者台詞,然後轉字幕。
拿音頻找導演聯系扒詞,結果導演居然說視訊扒詞可以,音頻就算了吧,算了吧……!
我可是有30個音頻,每個雖然才2-5分鐘,但轉成文字每個也有近千字吧,總和就是30000字!難道純手打嗎!踹翻導演啊!
科技這麼發達,難道找不到音頻轉文字的軟體嗎!我于是搜了一下:
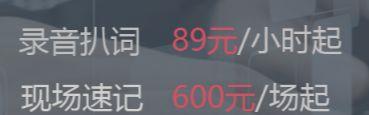
……天下沒有免費的午餐。
感謝萬能的知乎!讓我找到了IBM 爸爸的Speech to text!
Speech to text官網在這裡:
https://speech-to-text-demo.ng.bluemix.net/準備好你的音頻,以及Python,開始吧!!(推薦Anaconda,關于Anaconda安裝、Python包的安裝,可以看文末我的兩篇小筆記~)
第一步
點選首頁紫色的那個「Star for free in IBM Cloud」按鈕,注冊IBM Cloud并登陸(注冊不了的親,記得科學上網)。
第二步
添加服務(因為我已經加了服務,沒法給大家截圖了,自己找找吧),添加後是這樣的:

看到頁面下方顯示服務憑證,且username和password都是加密符号表示。點選右側的「顯示」,打開眼睛,把username和password記下來(複制到記事本裡啦不要翻小本本了!)
好了,官網任務完成,可以關掉了。
第三步
Python安裝SpeechRecognition包。
包的官網:
https://pypi.org/project/SpeechRecognition/ 運作-cmd,打開指令提示符。輸入pip install SpeechRecognition,耐心等待一會兒(我家裡網速比較捉急,花了10分鐘……網速好的話幾秒鐘吧,吐血),安裝完成即可。 第四步
打開Jupyter Notebook開始寫代碼啦!
import speech_recognition as sr #加載包
r = sr.Recognizer() with sr.WavFile("E://1.mp3") as source: #請把引号内改成你自己的音頻檔案路徑
audio = r.record(source)
運作這一步發現報錯了。
原來要wav格式。推薦一個好用的神器:格式工廠。音頻視訊檔案轉格式我都用它,友善小巧。
轉格式後把引号裡的内容改成1.wav就可以運作了。
接着定義賬号密碼,把引号裡的XXX改成你自己的。
IBM_USERNAME = 'XXXXXXXX'
IBM_PASSWORD= 'XXXXXXXX'
以及調用IBM的Speech to text。
text = r.recognize_ibm(audio, username = IBM_USERNAME, password = IBM_PASSWORD, language = 'zh-CN')
我2分多鐘的音頻大概運作了半分鐘左右吧。這個text,就是你音頻轉過來的文字了。讓我們來試試:
print(text)
嗯……雖然準确率沒有100%,但也已經比較可觀了!!
它支援多種語言,隻需要把language變量改成以下這些就可以實作不同語言的轉換:
ar-AR 阿根廷語
en-UK 英式英語
en-US 美式英語
es-ES 西班牙語
fr-FR 法語
ja-JP 日語
pt-BR 巴西葡萄牙語
zh-CN 中文
每個免費賬戶每個月可使用100分鐘,30天不活躍服務将删除。
6行代碼輕松音頻轉文字,你學會了嘛?
原文釋出時間為:2018-07-18
本文作者:莉莉安的向日葵
本文來自雲栖社群合作夥伴“
Python愛好者社群”,了解相關資訊可以關注“
”