Cifar
、
MNIST
等常用資料集的坑:
- 每次在一台新的機器上使用它們去訓練模型都需要重新下載下傳(國内網絡往往都不給力,需要花費大量的時間,有時還下載下傳不了);
- 即使下載下傳到本地,然而不同的模型對它們的處理方式各不相同,我們又需要花費一些時間去了解如何讀取資料。
為了解決上述的坑,我在
Bunch 轉換為 HDF5 檔案:高效存儲 Cifar 等資料集中将一些常用的資料集封裝為
HDF5
檔案。
下面的
X.h5c
可以參考
自己制作,也可以直接下載下傳使用(連結:
https://pan.baidu.com/s/1hsbMhv3MDlOES3UDDmOQiw密碼:qlb7)。
使用方法很簡單:
通路資料集
# 載入所需要的包
import tables as tb
import numpy as np xpath = 'E:/xdata/X.h5' # 檔案所在路徑
h5 = tb.open_file(xpath) 下面我們來看看此檔案中有那些資料集:
h5.root / (RootGroup) "Xinet's dataset"
children := ['cifar10' (Group), 'cifar100' (Group), 'fashion_mnist' (Group), 'mnist' (Group)]
下面我們以
Cifar
為例,來詳細說明該檔案的使用:
cifar = h5.root.cifar100 # 擷取 cifar100 為了高效使用資料集,我們使用疊代器的方式來擷取它:
class Loader:
"""
方法
========
L 為該類的執行個體
len(L)::傳回 batch 的批數
iter(L)::即為資料疊代器
Return
========
可疊代對象(numpy 對象)
"""
def __init__(self, X, Y, batch_size, shuffle):
'''
X, Y 均為類 numpy
'''
self.X = X
self.Y = Y
self.batch_size = batch_size
self.shuffle = shuffle
def __iter__(self):
n = len(self.X)
idx = np.arange(n)
if self.shuffle:
np.random.shuffle(idx)
for k in range(0, n, self.batch_size):
K = idx[k:min(k + self.batch_size, n)].tolist()
yield np.take(self.X, K, 0), np.take(self.Y, K, 0)
def __len__(self):
return round(len(self.X) / self.batch_size) 下面我們可以使用
Loader
來執行個體化我們的資料集:
batch_size = 512
train_cifar = Loader(cifar.trainX, cifar.train_fine_labels, batch_size, True)
test_cifar = Loader(cifar.testX, cifar.test_fine_labels, batch_size, False) 讀取一個 Batch 的資料:
for imgs, labels in iter(train_cifar):
break names = np.asanyarray([cifar.fine_label_names[label] for label in labels], dtype='U')
names[:7] array(['orchid', 'spider', 'rabbit', 'shark', 'shrew', 'clock', 'bed'],
dtype='<U13')
可視化
需要注意,這裡的
Cifar
是
first channel
的,即:
imgs.shape (512, 3, 32, 32)
names.shape (512,)
from pylab import plt, mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定預設字型
mpl.rcParams['axes.unicode_minus'] = False # 解決儲存圖像是負号 '-' 顯示為方塊的問題
def show_imgs(imgs, labels):
'''
展示 多張圖檔
'''
imgs = np.transpose(imgs, (0, 2, 3, 1))
n = imgs.shape[0]
h, w = 5, int(n / 5)
fig, ax = plt.subplots(h, w, figsize=(7, 7))
K = np.arange(n).reshape((h, w))
names = np.asanyarray([cifar.fine_label_names[label] for label in labels], dtype='U')
names = names.reshape((h, w))
for i in range(h):
for j in range(w):
img = imgs[K[i, j]]
ax[i][j].imshow(img)
ax[i][j].axes.get_yaxis().set_visible(False)
ax[i][j].axes.set_xlabel(names[i][j])
ax[i][j].set_xticks([])
plt.show() show_imgs(imgs[:25], labels[:25]) 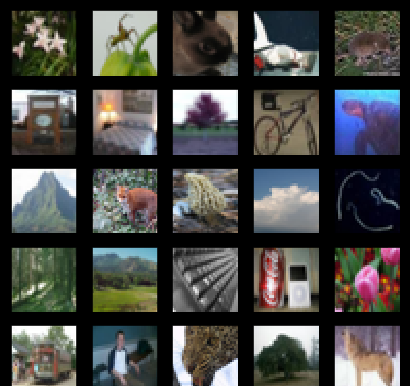
$2$ 個深度學習架構 & 資料集
因為,上面的資料集是
NumPy
的
array
形式,故而:
TensorFlow
import tensorflow as tf for imgs, labels in iter(train_cifar):
imgs = tf.constant(imgs)
labels = tf.constant(labels)
break imgs <tf.Tensor 'Const:0' shape=(512, 3, 32, 32) dtype=uint8>
labels <tf.Tensor 'Const_1:0' shape=(512,) dtype=int32>
MXNet
from mxnet import nd, cpu, gpu for imgs, labels in iter(train_cifar):
imgs = nd.array(imgs, ctx = gpu(0))
labels = nd.array(labels, ctx = cpu(0))
break imgs.context gpu(0)
labels.context cpu(0)
Matlab 讀取 HDF
參考:
h5read