一、使用avro-maven插件為avsc檔案生成對應的java類:
在項目的pom.xml中增加依賴及插件如下:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.1</version>
</dependency>
...
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.1</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> 執行mvn的install指令後,提示:
[INFO] Final Memory: 16M/217M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.avro:avro-maven-plugin:1.8.1:schema (default) on project study: neither sourceDirectory: D:\fvp-workspace\study\src\main\avro or testSourceDirectory: D:\fvp-workspace\study\src\test\avro are directories -> [Help 1]
[ERROR] 需要注意下,需要手動在${project.basedir}/src/main和${project.basedir}/src/test下建立avro檔案夾。avro檔案夾就是後面存放Avro的schema檔案了(*.avsc)。
1.1、定義schema
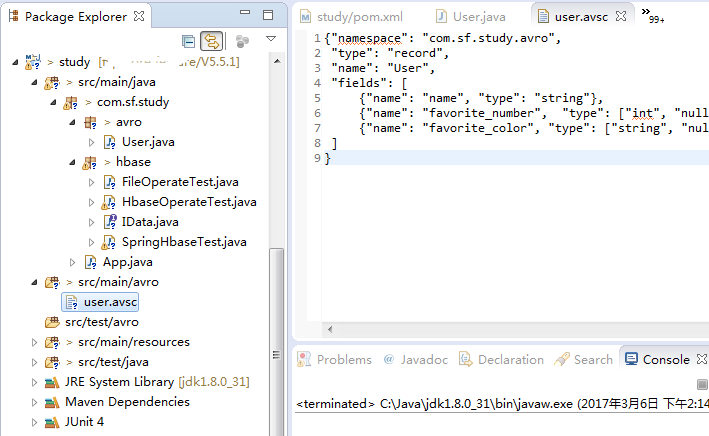
使用JSON為Avro定義schema。schema由基本類型(null,boolean, int, long, float, double, bytes 和string)和複雜類型(record, enum, array, map, union, 和fixed)組成。例如,以下定義一個user的schema,在main目錄下建立一個avro目錄,然後在avro目錄下建立檔案 user.avsc :
{"namespace": "com.sf.study.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
} 如IDE的截圖所示:
1.2、用schema生成類檔案
在這裡,因為使用avro插件,是以,直接輸入以下指令,maven插件會自動幫我們生成類檔案:
mvn clean install 然後在剛才配置的目錄下就會生成相應的類,如下:

如果不使用插件,也可以使用avro-tools來生成:
java -jar /path/to/avro-tools-1.8.1.jar compile schema <schema file> <destination> 1.3、使用前面生成的類
在前面,類檔案已經建立好了,接下來,可以使用剛才自動生成的類來建立使用者了:
package com.sf.study.avro;
public class CreateUserTest {
public static void main(String[] args) {
User user1 = new User();
user1.setName("zhangsan");
user1.setFavoriteNumber(256);
// Leave favorite color null
// Alternate constructor
User user2 = new User("lisi", 7, "red");
// Construct via builder
User user3 = User.newBuilder()
.setName("wangwu")
.setFavoriteColor("blue")
.setFavoriteNumber(null)
.build();
}
} 1.4、序列化
把前面建立的使用者序列化并存儲到磁盤檔案:
// Serialize user1, user2 and user3 to disk
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
try {
dataFileWriter.create(user1.getSchema(), new File("users.avro"));
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} 這裡,我們是序列化user到檔案users.avro
1.5、反序列化
public static void unserialize() {
try {
// Deserialize Users from disk
DatumReader<User> userDatumReader = new SpecificDatumReader<User>(User.class);
DataFileReader<User> dataFileReader;
dataFileReader = new DataFileReader<User>(new File("users.avro"), userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} {"name": "Alyssa", "favorite_number": 256, "favorite_color": null}
{"name": "Ben", "favorite_number": 7, "favorite_color": "red"}
{"name": "Charlie", "favorite_number": null, "favorite_color": "blue"}