Memcache工作原理總結
一 <!--[if !supportLists]-->1. <!--[endif]-->分片原理
咱們廢話話不多說了,直接看Memcache的原理。
首先memcache解決的最大的一個問題:《就是記憶體多次讀取的記憶體碎片問題》。記憶體碎片分為記憶體内部碎片和記憶體外部碎片。一般是指在外部碎片中出現了不連續的細小記憶體片段,不能夠被程序利用。因為不連續,不能組合成大而的連續空間,導緻這部分空間很可惜的浪費了。記憶體碎片是因為在配置設定一個記憶體塊後,使之空閑,但不将空閑記憶體歸還給最大記憶體塊而産生的。
那麼memcache啟動程序的時候就按照預先設定好的大小(預設是64mb)相記憶體開辟出一段連續的記憶體空間,之後再将這段記憶體空間分成不同的片段。
相信下面的圖大家都見過了
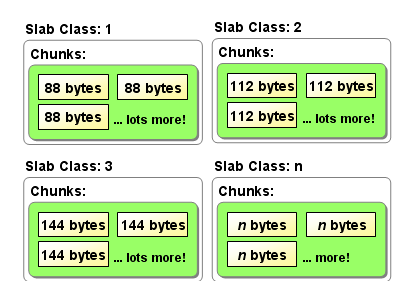
Memcache單程序最大可開的記憶體是2GB,如果想緩存更多的資料,建議還是開辟更多的memcache程序(不同端口)或者使用分布式memcache進行緩存,将資料緩存到不同的實體機或者虛拟機上。
Memcache程序啟動,在記憶體開辟了連續的區域。咱們用上面的圖形來舉例,這段連續的區域就好像上面的slab1+slab2+slab3+……+slab(n).配置設定區域相同的構成了slab(分片組)。
Slab下面可不直接就是存儲區域片(就是圖中的chunks)了。而是page,如果一個新的緩存資料要被存放,memcached首先選擇一個合适的slab,然後檢視該slab是否還有空閑的chunk,如果有則直接存放進去;如果沒有則要進行申請。slab申請記憶體時以page為機關,是以在放入第一個資料,無論大小為多少,都會有1M大小的page被配置設定給該slab。申請到page後,slab會将這個page的記憶體按chunk的大小進行切分,這樣就變成了一個chunk的數組,在從這個chunk數組中選擇一個用于存儲資料。
。在Page中才是 一個個小存儲單元——chunks,一個page預設1mb,那麼可以放多少個88位元組機關的chunks呢?1024*1024/88約等于11915個。如果放入記錄是一個100位元組的資料,那麼在88位元組的chunks和112位元組的chunks中如何調配呢。答案當然是緊着大的用,不可能将請求過來的資料再做個分解、分離存儲、合并讀取吧。這樣也就帶來了一個小問題,還是有空間浪費掉了。112-100=12位元組,這12位元組就浪費了。
在緩存的清除方面,memcache是不釋放已配置設定記憶體。當已配置設定的記憶體所在的記錄失效後,這段以往的記憶體空間,memcache自然會重複利用起來。至于過期的方式,也是采取get到此段記憶體資料的時候采取查詢時間戳,看是否已經逾時失效。基本不會有其他線程幹預資料的生命周期。至于清空的政策等同于ehcache的預設政策——最近很少使用清空政策——也就是英文常用的LRU——Least Recently Used。
而memcache鑒定記憶體不足是在什麼情況下呢:無法從slab裡面擷取新的存儲單元了。這個對記憶體十分貪婪的東東。基本伺服器都得是2~4GB以上方能吃得消(非時效性,或者說時效性較低的資料)。
Memcache借助了作業系統的libevent工具做高效的讀寫。libevent是個程式庫,它将Linux的epoll、BSD類作業系統的kqueue等事件處理功能封裝成統一的接口。即使對伺服器的連接配接數增加,也能發揮高性能。memcached使用這個libevent庫,是以能在Linux、BSD、Solaris等作業系統上發揮其高性能。Memcache号稱可以接受任意數量的連接配接請求。事實真的是這樣嗎?
二 <!--[if !supportLists]-->1. <!--[endif]-->存儲過程分析
假設我們現在往memcache中存儲一個緩存記錄,首先在使用memcache用戶端程式的時候要制定一個初始化的服務機器路由表,比如Java的用戶端程式
cachedClient = new MemCachedClient();
//擷取連接配接池執行個體
SockIOPool pool = SockIOPool.getInstance();
//設定緩存伺服器位址,可以設定多個實作分布式緩存
pool.setServers(new String[]{"127.0.0.1:11211","192.176.17.90:11211"}); 那麼在做存儲的時候memcache用戶端程式會hash出一個碼,之後再根據路由表去将請求轉發給memcache服務端,也就是說memcache的用戶端程式相當于做了一個類似負載均衡的功能。下面這個圖也是大家以前看過的

而memcache在server上面的程序僅僅負責監聽服務和接受請求、存儲資料的作用。分發不歸他管。是以這麼看的話,散列到每台memcache服務機器,讓每台機器分布存儲得均勻是用戶端代碼實作的一個難點。這個時侯Hash雜湊演算法就顯得格外重要了吧。
<!--[if !supportLists]-->1. <!--[endif]-->讀取過程分析
了解了memcache的存儲就不難了解memcache的讀取緩存的過程了。在讀取的時候也是根據key算出一個hash,之後在算出指定的路由實體機位置,再将請求分發到服務機上。
memcache分布式讀寫的存儲方式有利有弊。如果node2當機了,那麼node2的緩存資料就沒了,那麼還得先從資料庫load出來資料,重新根據路由表(此時隻有node1和node3),重新請求到一個緩存實體機上,在寫到重定向的緩存機器中。災難恢複已經實作得較為完備。弊端就是維護這麼一個高可用緩存,成本有點兒大了。為了存儲更多的資料,這樣做是否利大于弊,還是得看具體的應用場景再定。
<!--[if !supportLists]-->1. <!--[endif]-->與ehcache的争論
Ehcache的争論之前就說過了,總是在性能上來說這兩個的性能如何。還有大家在網上常見的一個清單進行了比較。筆者覺得,這兩個最大的差異是原理的差異決定了應用場景的差異。比如做單點應用緩存的時候,就可以使用ehcache直接向本地記憶體進行緩存的讀寫。而做叢集緩存的時候一般是借由一個集中式管理server來做緩存,既然是集中式server就少不了網絡傳輸了,這個時侯memcache較為适合。不是說ehcache不能做叢集式的緩存,而是做了叢集的緩存的代價(RMI、JMS、JGroups)、網絡資源的占用确實比memcache高一些。至于記憶體的讀寫操作效率,這個不太好說。Ehcache用java的随機讀寫類操作二進制的buffer。Memcache底層是基于libevent程式庫的C服務。這個相信效率都差不多。關鍵的消耗還是在網絡IO資源上。