=============================================================================
涉及到的知識點有:編碼風格、c語言的資料類型、常量、計算機裡面的進制、原碼反碼補碼、int類型、整數的溢出、大端對齊與小端對齊、char類型(字元類型)、
浮點類型float \ double \ long double、類型限定、字元串格式化輸出與輸入、基本運算符、運算符的優先級、類型轉換等。
gcc -o a1.s -S a1.c gcc把c語言代碼轉換為彙編代碼
-----------------------------------------------------------------------------
關于編碼風格的說明:
int dog_name; linux編碼風格
int dog_age;
int iDogName; 微軟編碼風格
int iDogAge;
編碼一定要工整,這是初學者容易忽略的。
C語言的資料類型:
1、常量:在此程式運作中不可變化的量(注意常量也是有類型的哦!)
第一種定義常量的方法:
#define MAX 100 這種定義常量的方法一般叫宏常量,是以有時也叫定義了一個宏,宏常量的常量名一般是大寫字母。
第二種定義常量的方法:
const int max = 0; const常量,
一般差別:c語言裡面用宏常量比較多,c++用const比較多。
"你好" 字元串常量
500 500本身是整數常量
比如:
int a = 500;
500 = 0; //這句是錯誤的
計算機裡面的進制:
十進制 二進制 八進制 十六進制
0 0 0 0
1 1 1 1
2 10 2 2
3 11 3 3
4 100 4 4
5 101 5 5
6 110 6 6
7 111 7 7
8 1000 10 8
9 1001 11 9
10 1010 12 a
11 1011 13 b
12 1100 14 c
13 1101 15 d
14 1110 16 e
15 1111 17 f
16 10000 20 10
17 10001 21 11
一個二進制的位就是一個bit(比特)
8個bit是一個BYTE(位元組)
2個BYTE是一個WORD(字)
2個WORD是一個DWORD(雙字)
1024個BYTE 是1KBYTE
1024K 是1M
1024M 是1G
1024G 是1T
1024T 是1P
1024P 是1E
1024E 是1Z
1024Z 是1Y
512GB 硬碟(機關是位元組)
12Mb 網絡帶寬(機關是比特)
200MB 檔案的大小(機關是位元組)
100Mb 網卡(機關是比特)
進制之間的轉換:
10101010111111010101011
把一個二進制數轉化為10進制是很困難的,但是計算機使用的就是二進制。
從右到左起,每3個一組,不夠的補零。
010 101 010 111 111 010 101 011 轉化為8進制
2 5 2 7 7 2 5 3
從右到左起,每4個一組,不夠的補零。
0101 0101 0111 1110 1010 1011 轉化為16進制
5 5 7 e a b
二進制其實和8進制、16進制是一一對應的,在計算機語言中一般不直接用二進制,c語言更多的用8進制或者16進制
把十進制的56轉化為2進制
先把這個數轉化為8進制,然後把8進制直接對應為2進制
用56除以8,分别取餘數和商數
8 56
7 0
0 7
70 轉化為8進制的結果
111 000 轉化為2進制的結果
16 100
6 4
0 6
64 轉化為8進制的結果
0110 0100 轉化為2進制的結果
2 100
50 0
25 0
12 1
6 0
3 0
1 1
0 1
1100100 直接轉化為2進制的結果
=============================================================================
這些數對于計算機來講,他們是怎麼放的呢??
1、原碼
例如:7的二進制是多少?(即7的二進制原碼如下)
111
0000 0111 用一個BYTE(位元組)表示
0000 0000 0000 0111 用一個WORD(字)表示(即用2個位元組來表示)
0000 0000 0000 0000 0000 0000 0000 0111 用一個DWORD(雙字)表示(即用4個位元組來表示)
那麼 -7 該如何表示呢?原則是:最高位為符号位,符号位0代表正數,1代表負數
-7的二進制是多少?(即 -7 的二進制原碼如下)
1000 0111 用一個BYTE(位元組)表示
1000 0000 0000 0111 用一個WORD(字)表示(即用2個位元組來表示)
1000 0000 0000 0000 0000 0000 0000 0111 用一個DWORD(雙字)表示(即用4個位元組來表示)
2、反碼:一個數若為正值,則反碼和原碼相同;一個數若為負值,則符号位為1,其餘各位與原碼相反。
7的反碼
-7的反碼
1111 1000 用一個BYTE(位元組)表示
1111 1111 1111 1000 用一個WORD(字)表示(即用2個位元組來表示)
1111 1111 1111 1111 1111 1111 1111 1000 用一個DWORD(雙字)表示(即用4個位元組來表示)
3、補碼:一個數若為正值,則補碼和原碼相同;一個數若為負值,則符号位為1,其餘各位與原碼相反,最後對整個數 +1 。
7的補碼
-7的補碼(在計算機内部,正數和負數都是以補碼的方式存放的。又因為正數的補碼是其本身,是以簡言之:所有的負數都是以補碼的方式存放的。好處是:用補碼進行運算,得到補碼,減法可以通過加法來實作,也即不用考慮符号位了!!)
1111 1001 用一個BYTE(位元組)表示
1111 1111 1111 1001 用一個WORD(字)表示(即用2個位元組來表示)
1111 1111 1111 1111 1111 1111 1111 1001 用一個DWORD(雙字)表示(即用4個位元組來表示)
小例題:
知道補碼如何求原碼?答:符号位不變,先 -1 再取反即可;或者符号位不變,先取反,再 +1 也可以哦!
補碼
1111 1111 1111 1111 1111 1111 1111 0101 如果是負數,是負幾?
1000 0000 0000 0000 0000 0000 0000 1011
這個數是-11的補碼。
sizeof 關鍵字作用是:得到某一資料類型在記憶體中占用的大小,機關是:位元組
sizeof 不是函數,是以不需要包含任何頭檔案
其實呢,sizeof傳回值的類型是size_t,size_t類型在32位作業系統下是一個無符号的整數。
例如:
int a = 0;
int b = 0;
b = sizeof(a);//得到a在記憶體中占用的大小,機關是:位元組
0000 0000 0000 0000 0000 0000 0000 0000 int a = 0;
0000 0000 0000 0000 0000 0000 0000 1010 int a = 10;
1111 1111 1111 1111 1111 1111 1111 0110 int a = -10;
有符号數的最高位0代表正數,1代表負數;(即有正有負)
無符号數的最高位就是數的一部分,不是正負的意思(即無符号數隻有正數)
有符号數的原碼
0000 0000 0
0000 1000 8
1000 1000 -8
無符号數的原碼
0000 1000 8
1000 1000 88(16進制的88)
一個BYTE(位元組)作為有符号數,最小是多少-128,最大是多少127
-128 -127 ...... -1 0 1 2 ...... 127
一個BYTE(位元組)無符号數,最小是0,最大是255
0 1 2 ...... 254 255
有符号數才區分原碼補碼,無符号數都是原碼
c語言從來不規定資料類型的大小,具體某種資料類型多大,和系統相關。
也即:在同一個系統下,具體的一種資料類型大小是相同的。
變量:就是在程式運作中可以更改值的量
int a; //定義了一個變量
a = 0;
a = 2;
如果直接寫一個整數,預設是10進制的整數
20 表示10進制的20
020 表示8 進制的20
0x20 表示16進制的20
%d 的意思是按照十進制的有符号整數輸出
%u 的意思是按照十進制的無符号整數輸出
%o 的意思是按照八進制的有符号整數輸出
%x 的意思是按照十六進制的有符号整數輸出(小寫)
%X 的意思是按照十六進制的有符号整數輸出(大寫)
例如:-11在記憶體中存放是以補碼的形式存放的。-11的補碼如下:
1111 1111 1111 1111 1111 1111 1111 0101
f f f f f f f 5
-11轉換成十進制就是:4294967285
signed int a; //定義了一個有符号的int(關鍵字signed一般不用寫)
unsigned int b; //定義了一個無符号的int
long int 是長整型,在32位系統下是4個位元組,在64位linux系統下是8個位元組,在64位的windows系統下是4個位元組。(大小是不穩定的)
long long int 是長長整型,在32位系統和64位系統下都是8個位元組。(大小是穩定的)
unsigned short int 無符号的短整數類型(大小為2個BYTE(位元組))
unsigned long int 無符号的長整數類型(大小是不穩定的)
unsigned long long int 無符号的長長整數類型(大小是穩定的)
100 直接這樣寫表示是一個有符号的int
100u 直接這樣寫表示是一個無符号的int
100l 直接這樣寫表示是一個有符号的long
100ul 直接這樣寫表示是一個無符号的long
100ll 直接這樣寫表示是一個有符号的long long
100ull 直接這樣寫表示是一個無符号的long long
注意:在c語言中表達一個整數的常量,如果什麼标示都不加,那麼預設類型是signed int(有符号的int)
整數的溢出:當超過一個整型能夠存放最大的範圍時,整數會溢出。
有兩種溢出:
符号位溢出:該溢出會導緻數的正負發生改變。
最高位溢出:該溢出會導緻最高位的丢失。
-----------------------------------------------------------------------------
1、符号位溢出例子:該溢出會導緻數的正負發生改變。
int a = 0x7fffffff;
a = a + 3;
printf("%d\n",a);
int(預設為有符号的int)
0111 1111 1111 1111 1111 1111 1111 1111
7 f f f f f f f
+1得到:
1000 0000 0000 0000 0000 0000 0000 0000
+2得到:
1000 0000 0000 0000 0000 0000 0000 0001
+3得到:(+3後該數變為負數了,而在計算機中,負數都是以補碼的方式存放的,即該負數就是補碼啦,那麼知道補碼求原碼)
1000 0000 0000 0000 0000 0000 0000 0010
因為printf("%d\n",a);%d的意思是按照十進制的有符号整數輸出的,即輸出的是有符号的原碼,
是以知道補碼如何求原碼?答:符号位不變,先取反,再 +1 即得;或者 符号位不變,先 -1 再取反也可以哦!
求得原碼是:
1111 1111 1111 1111 1111 1111 1111 1110
7 f f f f f f e
則輸出的結果是:-2147483646
2、最高位溢出例子:該溢出會導緻最高位的丢失。
int 6 = 0xffffffff;
b = b + 3;
printf("%u\n",b);
unsigned int(無符号的int)
1111 1111 1111 1111 1111 1111 1111 1111
1 0000 0000 0000 0000 0000 0000 0000 0000
1 0000 0000 0000 0000 0000 0000 0000 0001
1 0000 0000 0000 0000 0000 0000 0000 0010
因為printf("%u\n",b);%u的意思是按照十進制的無符号整數輸出的,即輸出的是無符号的原碼,
原碼是:
0000 0000 0000 0000 0000 0000 0000 0010 (把高位1丢掉了)
則輸出的結果是:2
大端對齊與小端對齊
計算機的記憶體最小機關是什麼?是BYTE,是位元組。
一個大于BYTE的資料類型在記憶體中存放的時候要有先後順序。
高記憶體位址放整數的高位,低記憶體位址放整數的低位,這種方式叫倒着放,術語叫小端對齊。電腦X86和手機ARM都是小端對齊的。
高記憶體位址放整數的低位,低記憶體位址放整數的高位,這種方式叫正着放,術語叫大端對齊。很多Unix伺服器的cpu都是大端對齊的。
如下圖例子:(有個圖檔)
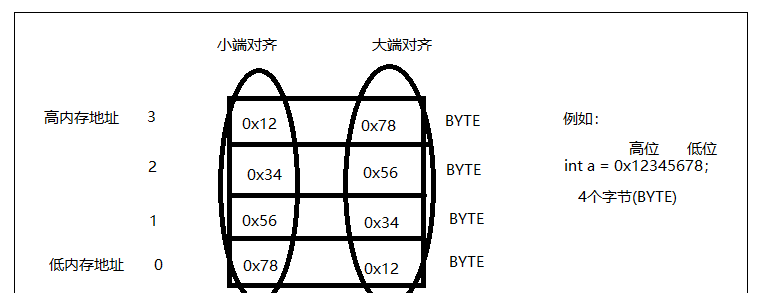
char類型(字元類型)
單引号引起來的字元就是char常量
'a' 是一個字元類型的常量a,'a'其實指的是字元a的ASCII碼,即所有的英文字元都是一個BYTE的整數,這個整數就是ASCII碼。
"a" 是一個字元串類型的常量
'2' 這個是字元型的2,而不是數字2
char a; //定義了一個字元類型的變量,名字叫a。
char a = 'a'; //等号左邊是一個變量,名字叫a;右邊是一個字元常量,就是字母a。
本質問題,至關重要:
char的本質其實是一個整數,大小是一個BYTE(位元組),在c語言中沒有BYTE這種資料類型,用char替代。
1 #include <stdio.h>
2
3 int main()
4 {
5 char a = 'a'; //等号左邊是一個變量,名字叫a;右邊是一個字元常量,就是字母a。
6 int i = sizeof(a);
7 printf("%d\n", i); //輸出1
8 a = 4; //此時char是一個有符号的char,也即有符号的int(隻是該int的大小為1個位元組)
9 a = a + 5;
10 printf("%d\n", a); //輸出9
11 a = 0x7f;
12 a += 3;
13 printf("%d\n", a); //輸出-126
14 unsigned char b = 0xff; //此時char是一個無符号的char,也即無符号的int(隻是該int的大小為1個位元組)
15 b = b +2;
16 printf("%u\n", b); //輸出1
17 a = 'B'; //把字元B的ASCII碼指派給了a。
18 printf("%d\n", a); //輸出66
19 a = 'b'; //把字元b的ASCII碼指派給了a。
20 printf("%d\n", a); //輸出98
21 a = 99;
22 printf("%c\n", a); //輸出c c% 輸出一個char類型的常量或者變量
23 return 0;
24 }
符号位溢出:該溢出會導緻數的正負發生改變。
//此時char是一個有符号的char,也即有符号的int(隻是該int的大小為1個位元組)
7 f
0111 1111
先加1得:
1000 0000
再加1得:
1000 0001
1000 0010 得到的就是負數了,而負數就是補碼,就是知補碼,求原碼?
求原碼得:
1111 1101 +1 得 1111 1110 輸出的是:-126
最高位溢出:該溢出會導緻最高位的丢失。
//此時char是一個無符号的char,也即無符号的int(隻是該int的大小為1個位元組)
f f
1111 1111
1 0000 0000
1 0000 0001 得到1;因為一個char最大能放8個比特(bit),從左往右
signed char min:-128 ~ max:127
unsigned char min: 0 ~ max:255
鍵盤的ASCII很多,有些ASCII沒法輸入,比如倒退效果(Backspace)怎麼輸入呢?用轉義字元 \ 例如:
char a = 'a'; //等号左邊是一個變量,名字叫a;右邊是一個字元常量,就是字母a。
printf("hello world");
a = '\b'; //'\b'表示一個倒退的ASCII
printf("%c",a); //輸出結果為:hello worl
printf("%c%c",a,a); //輸出結果為:hello wor
不可列印的字元(char)如下:
\a 警報
\b 倒退
\n 換行
\r 回車
\t 制表符
\\ 斜杠
\' 單引号
\" 雙引号
\? 問号
浮點類型:float、double、long double
char、short、int、long、long long這些類型都是存放整型,但這些類型無法處理小數
浮點類型 Linux系統下大小 windows系統下大小
float 4個位元組 4個位元組
double 8個位元組 8個位元組
long double 16個位元組 12個位元組
long 8個位元組 4個位元組
%f %lf 用來輸出一個浮點數,不能用輸出整型的轉移符來輸出一個浮點數
小練習:
一個浮點數變量,小數點後面有一位
3.5
3.7
2.8
1.1
核心代碼:
double a = 4.5
int b = a + 0.5;
a = b;
printf("%lf\n", a); //輸出的時候要四舍五入,例如4.5輸出5.000000
類型限定:
const 是定義一個常量,不可以被改變的
volatile 代表定義一個變量,這個變量可能在cpu指令之外被改變
volatile int a; //定義了一個volatile類型的int變量,通過volatile定義的變量,編譯器不會自作聰明的去優化這個變量相關的代碼。
register int a; //定義了一個變量,是寄存器變量。建議把一個變量放入cpu的寄存器可以提升程式的運作效率。
//register是建議型指令,而不是指令型指令,如果cpu有空閑寄存器,那麼register就生效,如果沒有空閑寄存器,那麼register無效。
例如: int b = 0; register b = 0;
b = b + 1; b = b + 1;
mov b, 0 mov eax, 0
mov eax, b add eax, 1
add eax 1
mov b, eax
字元串格式化輸出和輸入:
字元串在計算機内部的存儲方式:字元串是記憶體中一段連續的char空間,以 \0 結尾。
'a' 在記憶體裡就是一個字元a
"a" 在記憶體裡是兩個連續的字元,第一個是'a',第二個是'\0'
"hello world" 相當于 'h' 'e' ....... 'd' '\0'
1、字元串格式化輸出:
putchar 一次隻能輸出一個char
例如:
putchar(100); //輸出的是ASCII d
putchar('a'); //輸出的是 a
putchar(\n'); //輸出的是 換行
printf 一次隻能輸出一個字元串
printf("hello world\n"); //輸出的是 hello world
int a = 100;
printf(a); //這樣是錯誤的,應該如下:
int a = 100;
printf("%d\n", a);
printf的格式:
對應的資料類型: 含義:
%d int 輸出一個十進制的有符号的整數
%hd short int 輸出有符号的短整數
%hu unsigned short int 輸出無符号的短整數
%o unsigned int 輸出無符号的8進制整數
%u unsigned int 輸出無符号的10進制整數
%x unsigned int 輸出無符号的16進制整數(abcdef)
%X unsigned int 輸出無符号的16進制整數(ABCDEF)
%f float或者double 輸出單精度浮點數/雙精度浮點數
%e/E double 輸出科學計數法表示的數
%c char 可以把輸入的數字按照ASCII相應轉換為對應的字元
%s char * 輸出字元串中的字元直至字元串中的空字元(字元串以'\0'結尾,這個'\0'即是空字元)
%S wchar t *
%p void * 以16進制形式輸出指針
%% % 輸出一個百分号
例如: printf("%p\n", &a); //&a 的意思是:取變量a在記憶體中的位址(輸出位址用 %p)
printf的附加格式:
%l ld、lu、lo、lx 表示長整數
%m 表示輸出資料的最小寬度,預設為右對齊
%- 左對齊
%0 将輸出的前面補上0,直到占滿指定列寬為止(不可以搭配使用 - 哦)
long int 用%ld
long long int 用%lld
printf("(%6d)\n", a); //輸出的是:( 100)
printf("(%-6d)\n", a); //輸出的是:(100 )
printf("(%06d)\n", a); //輸出的是:(000100)
2、字元串格式化輸入:
getchar 函數:是從标準輸入裝置讀取到一個char。需要包含頭檔案stdio.h,傳回值是一個int,不需要傳入參數。
scanf 函數:通過%d轉義的方式可以得到使用者通過标準輸入裝置輸入的整數。
int a = getchar();
printf("%d\n", a); //輸出對應的一個字元的ASCII,假如鍵盤輸入a,則輸出97
int a;
scanf("%d", &a); //特别注意:第二個參數是變量的位址,而不是變量本身
printf("%d\n", a); //假如鍵盤輸入300,則輸出300
VS2013的C4996錯誤解決方法?
由于微軟在VS2013中不建議再使用c的傳統庫函數scanf,strcpy,sprintf等,
是以直接使用這些庫函數會提示C4996錯誤,在源檔案中添加以下指令就可以避免這個錯誤提示:
法一:
#define _CRT_SECURE_NO_WARNINGS
把這個宏定義一定要放到.c檔案的第一行
法二:
在主函數任意一行加上
#pragma warning(disable:4996)
如下圖所示:

基本運算符
% 取餘運算
int a = 7 % 2;
printf("%d\n", a); //輸出的是:1
a += 3; //相當于 a = a + 3;
a -= 3; //相當于 a = a - 3;
a *= 3; //相當于 a = a * 3;
a /= 3; //相當于 a = a / 3;
a++; //相當于a += 1;或者a = a + 1;
a--; //相當于a -= 1;或者a = a - 1;
b = a++; //先計算表達式的值,即先把a指派給了b;然後a再自加1。
b = ++a; //先a自加1後;然後把a自加後得到的指派給b。
小結:誰在前面先計算誰!!!
int a = 3;
int b = a++; //先計算表達式的值,即先把a的指派給了b(b = a = 3);然後a再自加1(a = a + 1)。
printf("%d. %d\n",a, b); //輸出的是:4,3
int b = ++a; //先a自加1得a = 4(a = a + 1),再把a的指派給了b(b = a = 4)
printf("%d. %d\n",a, b); //輸出的是:4,4
不同廠家的編譯器會有不同的結果:
在gcc的編譯下:
int b = ++a + a++; //輸出的是:5,9
int b = a++ + ++a; //輸出的是:5,8
printf("%d. %d\n",a, b);
在VS2013的編譯下:
int b = ++a + a++; //輸出的是:5,8
逗号運算符:先計算逗号左邊的值,再計算逗号右邊的值,但整個語句的值是逗号右邊的值。
(為什麼呢?要注意先計算逗号左邊的值是否對計算逗号右邊的值有影響)
int a = 2;
int b = 3;
int c = 4;
int d = 5;
int i = (a = b, c + d); //得到i的值為:9
int i = (a = b, a + d); //得到i的值為:8
運算符的優先級
優先級編号 運算符 優先級一樣時:
1(優先級高) []數組下标、()圓括号、()調用函數、{}語句塊 從左到右運算
2 ++、--、+字首、-字首、!字首、~字首、sizeof、
*取指針值、&取位址值、(type)類型轉換 從右到左運算(注意)
3 *、/、%取餘 從左到右運算
4 +、- 從左到右運算
5 <<、>> 從左到右運算
6 <、>、<=、>= 從左到右運算
7 ==、!= 從左到右運算
8 & 從左到右運算
9 ^ 從左到右運算
10 | 從左到右運算
11 && 從左到右運算
12 || 從左到右運算
13 ? 從右到左運算(注意)
14 =、*=、%=、+=、-=、<<=、>>=、&=、|=、^= 從右到左運算(注意)
15(優先級低) ,逗号運算符 從左到右運算
注意:如果不能确定優先級,或者要改變預設的優先級,用()小括号。
類型轉換
double f = (double)5/2; //強制轉換,把int的5強轉為double類型的5.000000,輸出是:2.500000
double f = (double)(5/2); //強制轉換,把int的5/int的2的結果強轉為double類型,輸出是:2.000000
c語言約定:
1、兩個整數計算的結果也是一個整數
2、浮點數與整數計算的結果是浮點數,浮點數和浮點數計算的結果還是浮點數
我的GitHub位址:
https://github.com/heizemingjun我的部落格園位址:
http://www.cnblogs.com/chenmingjun我的螞蟻筆記部落格位址:
http://blog.leanote.com/chenmingjunCopyright ©2018 黑澤明軍
【轉載文章務必保留出處和署名,謝謝!】