作者:閑魚技術-吉豐
基于設計師産出的 Sketch,甚至是一張 PNG,就能自動生成高可維護可擴充的 UI 代碼,品質堪比一位資深前端工程師, 一定是一件讓整個大前端領域都為之尖叫的事情。
出于這樣一個讓人興奮的命題,閑魚團隊打造了 ui-automation 工具 。
背景
如何讓前端,用戶端的 UI 開發更有效率,一直是一個大前端領域熱門話題。
從純手寫 UI 代碼,到編寫 XML 表達 UI,到所見即所得的 UI 編輯器。每一步都在極大提升着大前端領域的生産效率。
當下,随着計算機視覺技術,深度學習技術在工程側的大量使用,閑魚團隊的同學們認為,基于目前的技術,是完全能夠完成接近甚至超越資深前端工程師編寫的理想的 UI 表達。
問題
類比基于傳統的掃描算法和最新的 pix2code 的深度學習技術。它們确實在有些場景下,生成了渲染完全一緻的 UI 代碼,但是往往可維護性可擴充性差,除了在簡單的靜态頁面中能有所應用,在大部分需要動态能力的場景,無能為力。
核心的生成的 UI 代碼品質問題,是之前的這些工具無法跨越的鴻溝。
而閑魚的 ui-automation 最核心的是要解決代碼品質問題,使得生成的 UI 表達是最理想的,真正解放開發同學。
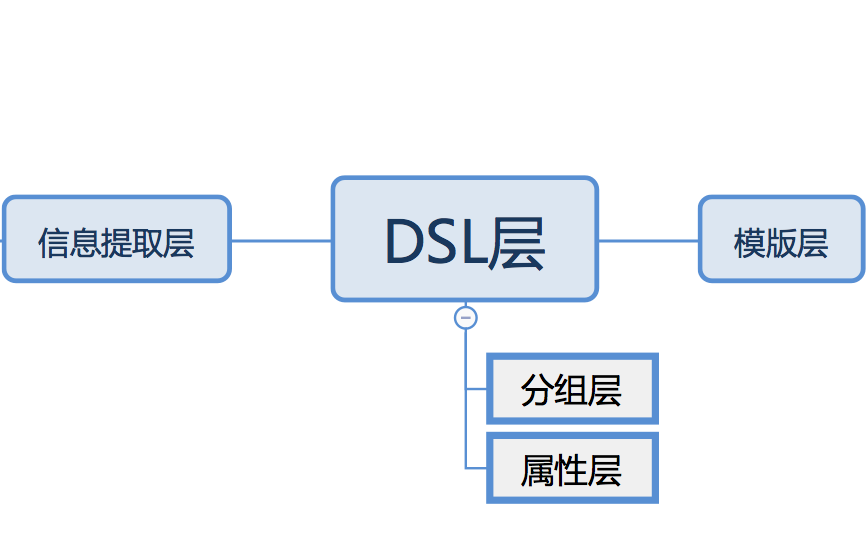
ui-automation 流程
- 資訊提取 => 2. DSL 推導 => 3. 目标平台代碼
相比于渲染流程
- ui 代碼 => 2. gpu 渲染 => 3. 畫面
是一個逆向的流程。
資訊提取層
- 基于 Skecth 資訊的提取和預處理
資訊全,精确,但是有備援,幹擾資訊。 - 基于圖檔資訊的提取
資訊幹淨,沒有備援資訊。
DSL 層
将扁平化的上遊資訊,樹形化,同時補充了完整的布局限制的資訊。
模版層
根據上遊的 DSL 資訊, 生成不同平台的目标代碼,如 flutter,weex 等。
本文重點闡述中間層 DSL 的定義和推導過程
基礎 UI 元素
我們定義了 3 中最基礎的 UI 元素
Shape,Text, Image。
結構上一個基礎 UI 元素有一下幾部分構成:
- 内容
- 渲染樣式
- 布局樣式
布局樣式沿用了經典 flexbox 的模型。
DSL 層的輸入
輸入中包含了上述 3 類基本的 UI 元素, 包含它們的内容,它們的渲染樣式,以及相對螢幕的絕對坐标和大小,其中層級結構和布局屬性在算法的推導中給出。
DSL 層的輸出
輸出是一個類似 dom 樹的結構,有完整的布局屬性,除了上述三類基礎元素外,還有基礎容器元件,CI 元件,BI 元件。
DSL 分層處理
在 DSL 的推導過程中, 分兩大層
分組層
關注于宏觀資訊的處理。目标是完成一棵最佳的 ViewTree,以及掃描出足夠的輔助資訊給下一層屬性推導使用。
(1)二進制切分
對一組元素進行劃分的時候
任何元素之間可能存在如下兩種關系 1. 父子關系 2. 兄弟關系
根據兩種關系的特點,我們使用了兩個不同的模型來對數組切割(一分為二)。 1. 父子關系使用重合模型來劃分。
重合模型會突出明顯的若幹個 background|foreground 圖層 在 x,y 兩個方向上都重合了剩下的所有元素。 2. 兄弟關系使用投影模型來劃分。
投影模型,通過往一個方向上投影,兄弟關系的元素間 會存在明顯的獨立且連續分布的規律。兩個方向都可投影的情況下, 優先水準方向。
在對重合模型和投影模型做适度優化後,第一次分組的容錯性,穩定性,準确性得到了極大的提升。
一個簡單的遞歸僞代碼
Group(...children:View[]){}
type slice = ( views:View[] ) => View[][] //sliceByOverlaps(views) || sliceByProjection(views)
const regroup = ( views:View[] ) => views.length === 1 ? views[0] : new Group(...slice(views).map(regroup)) 經過上步驟切分後, 得到的是一棵标準意義上的二叉樹。

例一:
注:7 号元素是簡化的處理,實際包含了 3 個基礎元素。
輸入:
[3, 2, 1, 4, 5, 6, 7] 輸出:
[
3,
[
[2, 1],
[
4,
[
[5, 6],
7
]
]
]
] 這樣的一棵二叉樹。
(2) 歸并
标準意義上的二叉樹, 并不符合我們的需求,是以需要做一次扁平化的歸并,将同方向的父子節點歸并為一個數組, 降低樹的深度。
const flattenOnDirection = (view:View, parentDir: FlexDirection) => {
return view.isContainer ?
? view.dir != null && view.dir == parentDir
? flatten(view.children.map(child => flattenOnDirection(child, view.dir)))
: [flattenGroup(view)]
: [view]
}
const flattenGroup = (view: View) => {
if(view.isContainer) {
view.children = flatten(node.children.map(l => flattenOnDirection(l, dir)), true)
}
return view
} 經過這層處理上例一的樹修正為
[
3,
[
[2, 1],
4,
[5, 6],
7
]
] (3) 排序層
根據容器方向,做一輪左到右,上至下的排序。
(4) 感覺輔助線
對 ViewTree 做一次深度周遊, 掃描出輔助線的資訊,将影響後續的對齊方式的推導,但并不影響 ViewTree 結構。
如上圖, 灰色框表示基礎元素,紅色框比較容器,黃色虛線表示掃描出輔助線的資訊。因為有輔助線資訊的存在,我們才能讓第 3 行的文字,左對齊,而非右對齊。人的視覺資訊處理亦是如此。
(5) 疏密切分
根據疏密分布, 在對同一容器下的孩子節點,根據疏密分布切分。
如上圖,同在水準方向的兄弟節點,根據疏密關系,分解為左族群和右族群,一個向左對齊,一個向右對齊,中間的剩餘空間是共享的。
(6) 掃描網格分布資訊
這裡用到圖形相似度的算法,若幹水準行, 每行的元素子樹之間相似。
在垂直方向掃描得到最大不重複的組合, 打破原有層級限制重新組合。
如:
掃描後, 打破原有層級限制後, 重新組合
(7) 感覺中間線
對 ViewTree 做一次深度周遊, 掃描出有效的中間線資訊,會影響 ViewTree 結構。
(8) 合并層 1. 合并背景圖層到容器的背景屬性 2. 合并背景圖層到 Text 的背景屬性 3. 合并僅包含一個孩子節點的容器
大緻經過上述 8 個小層的處理後, 我們得到了一個理想的 ViewTree。下一步開始我們的屬性推導。
屬性推導層
關注于局部資訊的深度推演。
(1) 推導每一個容器的方向
推導方向是最獨立的,僅僅依賴于孩子節點的分布情況。
(2) 推導每一個節點是 在流裡面的,還是脫離流絕對的
這裡依賴一個重合沖突算法。大體是重合沖突率高的,就是絕對的元素,重合沖突率低的是流式元素。同時存在一定的備援能力,允許小部分的重疊(負 margin),這樣極大的提高了線性布局的動态性。
(3) 推導每一個節點的大小。
以一個盡力撐滿的貪心模型,推導出每一個元素的大小。同時盡力用屬性限制取代直接給定寬或定高的形式,來達元素大小是到跟随内容或跟随孩子節點或跟随父容器的動态性。
對于一個容器的副軸的大小的處理,會略微複雜些,
(4) 推導出一些特殊布局
- 網格
- 左右對齊布局
等
(5) 推導主軸方向對齊方式
優先居中, 其次居左, 最後居右。
(6) 推導副軸方向對齊方式
(7) 推導位置
- 流式元素 通過 margin 表示坐标。 居中通過(5)(6)推導的 JustifyContent,AlignItems,AlignSelf 等要素描述。
- 絕對元素 通過 left, top, bottom, right 等描述坐标。居中通過 transform 描述。
(8) 推導 padding
ui-automation 工具目前已經運用在閑魚内部的各個業務場景之中,伴随着大量的應用,工具本身同樣日益進化。
最後,閑魚技術團隊廣招各類方向的達人,無論你是精通移動端,前端,背景,還是機器學習,音視訊,自動化測試等,都歡迎投遞履歷加入我們,一同用技術改善生活!