/proc/sys/net/ipv4:
- ip_local_port_range:限制了作為TCP或UDP對目标發起連接配接所選擇的本地端口範圍,其定義受核心版本影響。具體可以參見net.ipv4.ip_local_port_range 的值究竟影響了啥
- ip_forward:允許本機路由轉發。特别在容器環境下需要開啟該功能。
- tcp_window_scaling:表示是否啟用TCP視窗因子。視窗因子隻能位于TCP SYN/SYN_ACK封包選項中。window size在TCP首部隻占16位元組,最大為2^16=65536,相對于現代系統來說太小了,使用視窗因子可以增加TCP接收視窗(rwnd,即tcpdump顯示的win)大小,視窗因子最大值為14(RFC1323),計算邏輯為:window_size*(2^tcp_window_scaling),是以接收視窗最大為2^16*2^14=1GB。TCP 建鍊封包中的視窗因子計算方式如下,如sysctl_tcp_rmem[2]=6291456時,視窗因子為7
1 if (wscale_ok) {
2 /* Set window scaling on max possible window
3 * See RFC1323 for an explanation of the limit to 14
4 */
5 space = max_t(u32, sysctl_tcp_rmem[2], sysctl_rmem_max);
6 space = min_t(u32, space, *window_clamp);
7 while (space > 65535 && (*rcv_wscale) < 14) {
8 space >>= 1;
9 (*rcv_wscale)++;
10 }
11 } 對于TCP的初始接收視窗大小,linux和centos的實作是不一樣的,如linux核心3.10版本的初始接收視窗定義為10mss,但centos 3.10核心中的初始視窗大小定義為TCP_INIT_CWND * 2,即20*MSS大小。(看着linux源碼在centos7.4系統上測試,糾結了好久。。)
net/ipv4/tcp_output.c
u32 tcp_default_init_rwnd(u32 mss)
{
/* Initial receive window should be twice of TCP_INIT_CWND to
* enable proper sending of new unsent data during fast recovery
* (RFC 3517, Section 4, NextSeg() rule (2)). Further place a
* limit when mss is larger than 1460.
*/
u32 init_rwnd = TCP_INIT_CWND * 2;
if (mss > 1460)
init_rwnd = max((1460 * init_rwnd) / mss, 2U);
return init_rwnd;
}
/* TCP initial congestion window as per draft-hkchu-tcpm-initcwnd-01 */ /* TCP initial congestion window as per draft-hkchu-tcpm-initcwnd-01 */
#define TCP_INIT_CWND 10 ps:cwnd為擁塞視窗大小,表示一個RTT時間内可以發送的封包的個數,2.6.32核心之後的初始值設定為TCP_INIT_CWND,可以使用ss -it檢視實時狀态。
- tcp_rmem:調節(tcp_moderate_rcvbuf)并限制TCP接收緩存區。包含3個值,第一個值是為每個socket接收緩沖區配置設定的最少位元組數;第二個值是預設值(該值會覆寫net.core.rmem_default。較大的預設值會浪費記憶體,影響性能),緩沖區在系統負載不重的情況下可以增長到這個值;第三個值是接收緩沖區空間的最大位元組數。通過檢視源碼發現TCP socket接收緩存區的最大值僅在通過SO_RCVBUF設定的時候才會受net.core.rmem_max限制。tcp_rmem影響TCP建鍊時的視窗因子以及socket接收緩存大小。
- tcp_adv_win_scale:用于劃分網絡緩存區和應用緩存區的比例。核心将 socket 接收緩沖區會劃分為網絡緩沖區和應用緩沖區,網絡緩沖區及通常所提到的資料,而應用緩沖區為 skb 頭部一類的資料。具體劃分比率主要依賴 sysctl 中設定的 tcp_select_initial_window,tcp_adv_win_scale 大于 0 時,網絡緩沖區(即socket最大接收視窗)的計算邏輯為 space - (space >> tcp_adv_win_scale);否則計算邏輯為 space>>(-tcp_adv_win_scale) (本段描述來自這裡)。
static inline int tcp_win_from_space(int space)
{
return sysctl_tcp_adv_win_scale<=0 ?
(space>>(-sysctl_tcp_adv_win_scale)) :
space - (space>>sysctl_tcp_adv_win_scale);
}
/* Note: caller must be prepared to deal with negative returns */
static inline int tcp_space(const struct sock *sk)
{
return tcp_win_from_space(sk->sk_rcvbuf -
atomic_read(&sk->sk_rmem_alloc));
} - tcp_app_win:tcp_adv_win_scale劃分出來的應用緩存區保留的位元組數,參見Linux網絡相關參數
- tcp_wmem:限制TCP發送緩存區大小,包含3個值。第一個值是為每個socket發送緩沖區配置設定的最少位元組數;第二個值是預設值(該值會覆寫wmem_default),緩沖區在系統負載不重的情況下可以增長到這個值;第三個值是發送緩沖區空間的最大位元組數。不建議修改。
- tcp_mem:限制總的TCP緩存區的大小。包含3個以頁(4k位元組)為機關的值,意義與上面類似。不建議修改
- tcp_moderate_rcvbuf:預設開啟,用于自動調節發送/接收緩存區大小,初始值為tcp_rmem和tcp_wmem的預設值。不能大于tcp_rmem[2]
- tcp_keepalive_time:TCP保活時間,預設2小時
- tcp_keepalive_intvl:保活封包發送周期,預設90秒
- tcp_keepalive_probes:保活封包發送次數。keepalive routine每2小時(7200秒)啟動一次,發送第一個probe(探測包),如果在75秒内沒有收到對方應答則重發probe,當連續9個probe沒有被應答時,認為連接配接已斷
- tcp_max_syn_backlog:TCP半連接配接隊列大小,隊列中的連接配接處理SYN-RECV狀态(即為接收到對端的ACK封包)。表示可以儲存的未完成TCP握手的連接配接的數目。下圖來自這篇部落格,建鍊完成後連接配接會轉移到LISTEN backlog中。當該隊列滿後,會直接丢棄SYN封包。
當tcp_syncookies設定為1後,當半連接配接隊列滿時,将不會丢棄SYN,而是會傳回一個帶有cookie的SYN/ACK封包。
位于syn backlog中的連接配接狀态為SYN_RECV,可以通過如 netstat -antp|grep SYN_RECV|wc -l 檢視目前處于syn backlog中的連接配接的數目。可以通過nstat -az TcpExtListenDrops檢視是否有因為syn backlog滿而丢棄的封包(如syn攻擊)。更多參見另一篇博文。
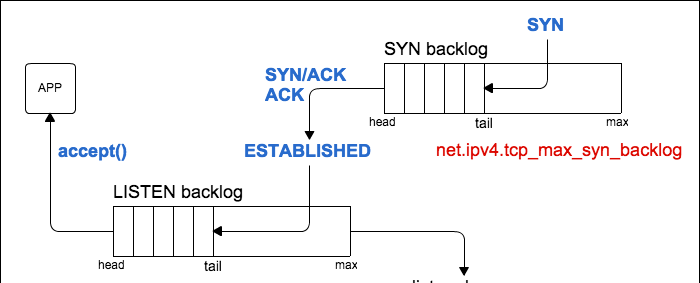
- tcp_syncookies:當啟動sync cookies功能後,當syn backlog隊列滿時,系統不會丢棄新的SYN封包,而是會發送syncookie封包來校驗是否是正常的連接配接,主要用于防止syn flood攻擊。下圖來自SYN-Cookies,可以看到syn cookies充當了類似連接配接緩存的作用。syncookie的方式修改了正常的TCP互動,可能在高負荷的伺服器下出現一些問題,如計算cookie的hash會加重CPU負擔,不支援某些TCP選項等。官方并不建議将該參數作為性能調參,而推薦使用tcp_max_syn_backlog, tcp_synack_retries, 和 tcp_abort_on_overflow。

開啟tcp_syncookies時通常需要開啟tcp_timestamps,用來将tcp選項編碼到時間戳中。如下圖可以看到視窗是以wscale編碼在時間戳中,不啟用時間戳将無法使用該選項。
- tcp_abort_on_overflow:在TCP全連接配接隊列(net.core.somaxconn)滿之後,當新的連接配接到來之後會丢棄握手階段的最後一個ack(值為0)封包;或發送rst(值為1)封包直接斷鍊。預設值為0。隻有在确認服務端長時間内無法處理新連接配接的情況下才會置為1,否則置為1會影響用戶端使用。當全連接配接隊列滿且該值為0的情況下,用戶端會根據net.ipv4.tcp_synack_retries繼續嘗試建立連接配接。
- tcp_timestamps:預設打開。enable時間戳會啟用Round Trip Time Measurement (RTTM) 和Protect Against Wrapped Sequences (PAWS)功能,前者用于計算rto;後者用于解決高帶寬下的序列号回環問題,使用時間戳作為次元來判斷資料包是否有效。啟用時間戳功能可以提高系統性能。tcp_timestamps可以用于NAT環境,并不會對連接配接造成影響,隻有tcp_timestamps與tcp_tw_recycle同時啟用時才會在NAT環境下導緻連接配接逾時。如下圖,假設server啟用了tcp_timestamps與tcp_tw_recycle,2個client通過NAT連接配接到一個server,此時對server來說,client1和client2的位址都變成了NAT後的位址。當server主動斷開與client的TCP連接配接,如果在client1鍛煉後的TCP_PAWS_MSL時間内,client2發起連接配接,但client2的SYN封包的timestamps小于先前server儲存的時間戳,會導緻該SYN封包被丢棄,而不回複任何封包,最後client2會timeout。參見stackoverflow的這篇文章。單獨timestamp功能不會導緻此問題
- tcp_timestamps必須在兩端同時開啟的情況下才會生效。
- tcp的timestamp功能是在TCP握手階段協商的。
- tcp timestamp的
- tcp_tw_recycle:預設關閉,僅在tcp_timestamps開啟條件下生效,用于server端在一個rto時間内快速回收TIME_WAIT狀态的socket。生産環境建議關閉。核心 4.12 之後已移除: remove tcp_tw_recycle。更多參考這裡
- tcp_tw_reuse:預設關閉,僅在tcp_timestamps開啟條件下生效,僅使适用于用戶端複用處于TIME-WAIT狀态(超過1s)的socket。主要用于用戶端高并發測試場景,減少socket消耗。
- tcp_fin_timeout:FIN_WAIT_2狀态的時長
- tcp_max_tw_buckets:限制了處理TIME_WAIT狀态的連接配接的數目。多餘的連接配接會直接釋放。
- tcp_syn_retries:TCP建鍊時syn封包的重傳次數,預設為6,即syn封包最多發送7次,重傳間隔為2<<(n-1)秒。
- tcp_synack_retries:設定了TCP建鍊時syn-ack封包的重傳次數,重傳間隔為2<(n-1)秒
- tcp_retries1:預設3。當TCP資料重傳超過這個值計算出的逾時時間後(見retries2),會進行重新整理底層路由的操作,防止由于網絡鍊路發生變化而導緻TCP傳輸失敗
- tcp_retries2:預設15。(如果socket設定了TCP_USER_TIMEOUT參數,則TCP資料重傳逾時由該參數決定,不受tcp_retries2控制)。總的重傳逾時時間通過如下方式計算得出,其中變量boundary對應的就是tcp_retries1或tcp_retries2的值。可以看到tcp_retries1和tcp_retries2其實計算的是最大逾時時間,而不是重傳次數。
linear_backoff_thresh用于計算使用/不使用指數退避算法的逾時時間點,ilog2(TCP_RTO_MAX / rto_base)就是求底數為2,反對數為(120000/200)的整數,值為9,即當總的重傳時間小于(2<<9-1)*200ms=204.6s時,重傳間隔時間使用指數退避方式;當總的重傳時間大于204.6時,後續重傳時間為TCP_RTO_MAX,即120s。
按照如下方式可以計算出,tcp_retries2=15時,最大逾時時間為(2<<9-1)*0.2+(15-9)*120=924.6s,即當總的重傳時間大于924.6s後,停止重傳。
重傳次數受路由rto影響,可以使用使用如下方式設定一條連接配接的rto_min,非200ms時可能會使得總的重傳次數大于或小于15。(可以使用ss -i檢視TCP連接配接上的rto大小)
ip route add src_ip/32 via dst_ip rto_min $rto //核心源碼net/ipv4/tcp_timer.c
static unsigned int tcp_model_timeout(struct sock *sk,
unsigned int boundary,
unsigned int rto_base)
{
unsigned int linear_backoff_thresh, timeout;
linear_backoff_thresh = ilog2(TCP_RTO_MAX / rto_base);
if (boundary <= linear_backoff_thresh)
timeout = ((2 << boundary) - 1) * rto_base;
else
timeout = ((2 << linear_backoff_thresh) - 1) * rto_base +
(boundary - linear_backoff_thresh) * TCP_RTO_MAX;
return jiffies_to_msecs(timeout);
} - tcp_max_orphans:系統所能維護的孤兒socket(不與任何檔案描述符關聯)的最大數目(可以通過ss -s指令檢視目前tcp的orphan socket數目)。當orphan socket數目超過該值後,會通過reset來關閉連接配接。每個orphan socket會占用64Bb且不可swap的記憶體。該參數可以用于防止DDoS攻擊。可以檢視netstat的TcpExtTCPAbortOnMemory統計資訊。
- tcp_orphan_retries:規定了orphan socket的重傳次數。減小該值可以快速回收orphan socket。net.ipv4.tcp_orphan_retries的預設值為0,核心計算時會重置為8。orphan socket為調用核心tcp_close(struct sock *sk, long timeout)函數産生的。orphan socket包含FIN_WAIT1、LAST_ACK、CLOSING(同時關閉)狀态的socket(TIME_WAIT狀态不屬于orphan socket--實測驗證)。更多詳細參見這篇博文
- tcp_sack:用于提高重傳多個封包時的速率(重傳特定封包),sack的缺點可以檢視When to turn TCP SACK off?
- tcp_ecn:配合中間路由器實作感覺中間路徑的擁塞,并主動減緩TCP的發送速率,進而從早期避免擁塞而導緻的丢包,實作網絡性能的最大利用。網絡中的路由器按照1999年的ECN草案方案實作,将隻識别ECN=10的封包作為支援ECN功能,而不識别ECN=01的封包,這類路由器可能将ECN=01的封包将按照ECN=00的行為處理,最後進行RED丢包。但并不影響網絡的正常功能預設值為2(即二進制10)。參考不要亂用 TCP ECN flag
- tcp_fastopen:TCP Fast Open(TFO)是用來加速連續TCP連接配接的資料互動的TCP協定擴充,原理如下:在TCP三向交握的過程中,當使用者首次通路Server時,發送SYN包,Server根據使用者IP生成Cookie(已加密),并與SYN-ACK一同發回Client;當Client随後重連時,在SYN包攜帶TCP Cookie;如果Server校驗合法,則在使用者回複ACK前就可以直接發送資料;否則按照正常三次握手進行。其中1表示用戶端開啟,2表示服務端開啟,3表示用戶端和伺服器同時開啟。在高版本的Linux中,預設為1
- tcp_reordering:通知核心在一條TCP中需要重組的封包數目,此時不考慮封包丢失。如果大于該值,會認為有封包丢失,TCP棧會自動切換到慢啟動。預設3
- tcp_fack:基于sack的擁塞避免控制。
- tcp_challenge_ack_limit:每秒發送的挑戰封包(challenge ack用于防止Blind In-Window Attacks,分為接收到資料,RST封包,SYN封包的處理,用于避免盲資料注入和斷鍊攻擊)的數量,預設1000。參見TCP挑戰ACK封包限速
- tcp_invalid_ratelimit:用于控制響應如下無效TCP封包的重複ACK封包的最大速率(挑戰ACK受此限制),預設500ms:
- 無效的序列号
- 無效的确認号
- PAWS 校驗失敗
-
0 - Disabled
1 - Disabled by default, enabled when an ICMP black hole detected
2 - Always enabled, use initial MSS of tcp_base_mss.
參考:
- Linux之TCPIP核心參數優化
- TCP protocol
- Tuning TCP - sysctl.conf
- 聊一聊重傳次數
- TCP timestamp
- TCP SOCKET中backlog參數的用途是什麼? ---圖解
- Coping with the TCP TIME-WAIT state on busy Linux servers
- SYN Flood攻擊及防禦方法
- TCP SYN-Cookie的原理和擴充
- TCP 接收視窗
/proc/sys/net/core:
- dev_weight:該參數确定了在一個NAPI(NAPI是中斷和輪詢的結合,資料量低時采用中斷,資料量高時采用輪詢)中斷周期内,核心可以從驅動隊列擷取的最大封包數(skbuff數),如果裝置支援LRO或GRO_HW,則會将聚合之後的封包數視為1個。調大該值可以允許在一個軟中斷周期内處理更多的封包,但同時也會占用更多的CPU。如果隊列中的封包數小于該值,則退出輪詢,啟用中斷模式。
NAPI提供了如下接口:
-
- netif_napi_add --driver告訴核心要使用napi的機制,初始化響應參數,注冊poll的回調函數
- napi_schedule --driver告訴核心開始排程napi的機制,稍後poll回調函數會被調用
- napi_complete --driver告訴核心其工作不飽滿即中斷不多,資料量不大,改變napi的狀态機,後續将采用純中斷方式響應資料
- net_rx_action --核心初始化注冊的軟中斷,注冊poll的回調函數會被其調用
- dev_weight_rx_bias:用于設定rx軟中斷周期中核心可以從驅動隊列擷取的最大封包數,為(dev_weight * dev_weight_rx_bias)。主要用于調節網絡棧和CPU在rx上的不對稱。
- dev_weight_tx_bias:與dev_weight_rx_bias類似,用于tx路徑。調節這兩個數值時需要注意對CPU的影響。
- netdev_budget_usecs:NAPI輪詢的最大周期。當輪詢周期達到netdev_budget_usecs或處理的封包數達到netdev_budget時會退出NAPI的輪詢處理。
- default_qdisc:預設的qdisc,可以使用ip link指令檢視
- netdev_max_backlog:當接口接收封包的速率大于核心處理的速率時,輸入側隊列可以儲存的最大封包數目。
- flow_limit_cpu_bitmap和flow_limit_table_len:二者用于在RPS中實作流控。前者用于指定啟用流控的CPU位圖,後者指定哈希表的大小(預設4096),哈希表中的每個bucket對應一條流,用于計算哈希到該bucket的流的封包速率。
- rps_sock_flow_entries和/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt:用于配置RFS。前者為socket流表,表中的每個bucket包含哈希到該bucket的流期望的CPU清單,如果清單為空,則使用RPS功能。後者為每條流的表大小,推薦值為:rps_sock_flow_entries/N,N表示隊列的數目。參見RFS: Receive Flow Steering
- netdev_rss_key:啟用RSS的驅動程式使用的40位元組的主機密鑰。也可以通過ethtool -x <dev>檢視
- xsomaxconn:TCP LISTEN backlog 隊列大小,預設128。表示挂起的(未被accept處理的)請求的最大數目。可以通過listen函數的第二個參數指定int listen(int sockfd, int backlog) ,如果設定的backlog值大于net.core.somaxconn值,将被置為net.core.somaxconn值大小。可以使用ss -ntl 檢視目前LISTEN backlog隊列長度以及隊列中待處理的連接配接長度。如下面表示LISTEN backlog長度為128,目前有1個連接配接待(accept)處理。LISTEN backlog隊列滿之後的動作與net.ipv4.tcp_abort_on_overflow相關。
# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 1 128 :::19090 :::* - rmem_default:設定了TCP/UDP/Unix等socket的接收緩存區預設值,由核心自動調整,不建議修改。TCP下設定為net.ipv4.tcp_rmem的預設值
- wmem_default:設定了TCP/UDP/Unix等socket的發送緩存區預設值,由核心自動調整,不建議修改。TCP下設定為net.ipv4.tcp_wmem的預設值
- rmem_max:設定了TCP/UDP/Unix等socket的接收緩存區的上限值。rmem_max的作用如下:
- 限制通過socket選項SO_RCVBUF設定(sock_setsockopt)的接受緩存區的大小
- 用于計算TCP建鍊的視窗是以(參見本文tcp_window_scaling描述)
更多參見TCP receiving window size higher than net.core.rmem_max
- wmem_max:設定了TCP/UDP/Unix等socket的發送緩存區的上限值
- 關于TCP 半連接配接隊列和全連接配接隊列
- Socket緩存是如何影響TCP性能的?
/proc/sys/net/netfilter:
- nf_conntrack_acct:enable該值後會在/proc/net/nf_conntrack的條目中增加連接配接互動的總package count和總package bytes參數。參見What does nf_conntrack.acct really do?
- nf_conntrack_timestamp:enable該值後會在/proc/net/nf_conntrack的條目中增加連接配接存活累計時間(機關s)參數delta-time。
- nf_conntrack_buckets:隻讀檔案,表示HASHSIZE。系統啟動後無法修改,但可以通過如下方式修改。
echo 16384 > /sys/module/nf_conntrack/parameters/hashsize - nf_conntrack_max:設定連接配接跟蹤數的最大值,當系統達的連接配接跟蹤數達到該值後,再建立連接配接跟蹤時會報“nf_conntrack: table full, dropping packet”錯誤。由于連接配接跟蹤數比較占記憶體,是以不能盲目增加該值大小。nf_conntrack_max=HASHSIZE*(bucket size),(bucket size)預設為4。bucket size不能直接修改,隻能通過修改nf_conntrack_max/nf_conntrack_buckets的比值來間接修改。
/proc/net/nf_conntrack中的兩個特殊字段含義如下:
-
-
[ASSURED]
-
[UNREPLIED]
-
- nf_conntrack_count:目前使用的連接配接跟蹤數目,隻讀。
- sysctl -a | grep conntrack | grep timeout可以看出與各個協定狀态相關的timeout時間。以TCP為例,如下參數描述了TCP各個狀态的nf_conntrack的生存時間,如nf_conntrack_tcp_timeout_established的值為432000s(5days),表示處于建鍊狀态的TCP的最大生存時間為5天,逾時後會移除該連接配接跟蹤數。在NAT場景下,移除連接配接跟蹤将會導緻連接配接中斷(但不會通知兩端)。非NAT場景下,其連接配接跟蹤僅僅用于記錄目前連接配接情況,移除這種情況下的連接配接跟蹤不會對鍊路造成影響。設定如下參數時最好将設定值大于等于系統或協定規定的參數大小,否則可能導緻鍊路異常。
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300 參考
- Linux 執行個體常用核心網絡參數介紹與常見問題處理
- Iptables之nf_conntrack子產品
/proc/sys/vm:
- vfs_cache_pressure:控制核心回收directory和inode的回收速率,當降低該值會使得核心保留dentry和inode caches,當vfs_cache_pressure=0時,核心不會回收dentry和inode caches,這種情況下可能會導緻記憶體洩漏。增加該值可能會影響系統性能,但會加快回收dentry和inode caches,可以通過slabtop指令檢視dentry/inode caches的數值。參見記一次記憶體使用率過高的報警
- dirty_background_ratio:預設10,以比例規定記憶體髒資料最大值,dirty_background_ratio和dirty_background_bytes隻能選擇一種,即一個為非0,則另一個為0。當對資料的一緻性要求比并發處理更高時,可以将該值調低
- dirty_background_bytes:預設0,以具體數值規定記憶體髒資料最大值
- dirty_writeback_centisecs:預設500,即5s,記憶體髒資料寫回周期,系統以該周期定時啟動pdflush/flush/kdmflush線程來将髒資料寫會到磁盤。如果IO繁忙時,可能會啟動多個flush線程。需要注意的是,flush對應的髒資料不一定會從記憶體中釋放(見下)。
- dirty_expire_centisecs:預設3000,即30s,髒資料在記憶體中停留的最長時間,當超過該時間後,髒資料會在下一次寫回到磁盤。
- 髒資料在記憶體停留條件為:
- a:dirty_expire_centisecs時間以内
- b:髒資料沒有超過dirty_background_ratio門檻值
- dirty_ratio:預設30,記憶體中髒資料占總可用(available)記憶體的最大比例,當超過該值後系統會執行寫回操作并阻塞所有程序的IO寫操作,直到髒資料小于dirty_ratio。
- kswapd會在可用記憶體低于zone設定的low時執行記憶體回收。當可用記憶體低于zone的min時會觸發核心直接回收機制(OOM)。low值通過/proc/vm/min_free_kbytes設定。pdflush用于周期性地将髒資料寫回到磁盤,當髒資料大于dirty_background_ratio或dirty_background_bytes時會觸發IO阻塞,kswapd和pdflush在某些功能上會有一些耦合,kswapd用于緩存管理,包含記憶體的swap out和page out,page cache的回收,而pdflush僅用于回收dirty cache。具體參見kswapd和pdflush
- 髒資料在記憶體停留條件為:
參考:
- linux-pdflush.htm
- linux-kernel-sysctl-vm/
- sysctl/vm.txt
- Linux_Page_Cache_Basics
/proc/sys/net/bridge:
- bridge-nf-call-arptables:表示arptables是否可以過濾bridge接口的封包。
- bridge-nf-call-ip6tables:表示ip6tables是否可以過濾bridge接口的封包
- bridge-nf-call-iptables:表示iptables是否可以過濾二層bridge接口的封包。iptables既能處理三層封包也能處理二層封包,bridge環境下使能該選項,可能會導緻二層網絡問題。注意下圖中的"bridge check"處理節點。ps:ebtables用于對以太網幀的過濾,iptables用于對ip資料包的過濾
- What's bridge-netfilter?
- bridge-nf
- net.bridge.bridge-nf-call-iptables=1
/proc/sys/fs:
- file-max:核心可以配置設定的檔案句柄的最大值。當遇到如“VFS: file-max limit <number> reached"錯誤時,說明該值過低,可以調整上限。該值通常由核心确定,為記憶體的10%左右
- file-nr:描述了核心檔案句柄的使用情況。第一個值表示目前配置設定的檔案句柄的數目;第二個表示已經配置設定但未使用的檔案句柄的數目;第三個值表示可配置設定的檔案句柄的最大值。
- nr_open:限制了單個程序可以打開的檔案描述符的上限。關系為:ulimit -Sn <= ulimit -Hn <= cat /proc/sys/fs/nr_open
需要注意的是程序可打開的檔案描述符的最大數目并不一定等于ulimit -Sn,如程序可以通過systemd的LimitNOFILE參數來設定其soft值。可以在/proc/$pid/limits中檢視程序的ulimit值,也可以直接修改該值來修改程序的ulimit限制。
需要注意核心檔案句柄和檔案描述符的差別,檔案描述符為使用者層面的内容,可以使用lsof或在/proc/$pid/fd中檢視程式打開的檔案描述符。而核心檔案句柄的使用情況需要檢視核心參數file-nr。更多可以參考這篇文章。
核心檔案句柄可以通過如下方式申請,當共享記憶體使用結束後需要解除安裝共享内容(如mmap/munmap,shmat/shmctl($shmid, IPC_RMID, NULL)),否則會導緻核心檔案句柄洩露(核心句柄通過引用計數來判斷是否删除該檔案句柄)。
- open系統調用打開檔案(path_openat核心函數)
- 打開一個目錄(dentry_open函數)
- 共享記憶體attach (do_shmat函數)
- socket套接字(sock_alloc_file函數)
- 管道(create_pipe_files函數)
- epoll/inotify/signalfd等功能用到的匿名inode檔案系統(anon_inode_getfile函數)
- sysctl/fs.txt
- 資源限制(RLIMIT_NOFILE)的調整細節及内部實作
/proc/sys/kernal:
- sched_rt_period_us:該檔案中的值指定了等同于100% CPU寬度的排程周期。取值範圍為1到INT_MAX,即1微秒到35分鐘。預設值為1000,000(1秒)
- sched_rt_runtime_us:該檔案中的值指定了實時和deadline排程的程序可以使用的"period"(sched_rt_period_us)。取值範圍為-1到INT_MAX-1,設定為-1辨別運作時間等同于周期,即沒有給非實時程序預留任何CPU。預設值為950,000(0.95秒),表示給非實時或deadline排程政策保留5%的CPU。sched_rt_period_us和sched_rt_runtime_us都與實時排程有關。
- sched_cfs_bandwidth_slice_us:設定系統層面的CPU帶寬(即可占用的CPU時間),預設5ms。程序的CPU帶寬可以通過cgroup的cpu.cfs_quota_us和cpu.cfs_period_us設定。
- sched_latency_ns:所有任務至少被排程一次所用的時長,然後将該時間平均配置設定給每個任務。注意,它隻是個初始值,當系統中可運作的任務變多時,排程器會選擇使用sched_min_granularity_ns(參見sched_min_granularity_ns的計算方式)
- sched_min_granularity_ns:保證一個任務在被搶占之前允許運作的最小時間片長度,也即單個任務可以運作的最小時間片長度。
If number of runnable tasks does not exceed sched_latency_ns/sched_min_granularity_ns
scheduler period = sched_latency_ns
else
scheduler period = number_of_running_tasks * sched_min_granularity_ns - sched_wakeup_granularity_ns:該參數限定了一個喚醒程序要搶占目前程序之前必須滿足的條件:隻有當喚醒程序的vruntime比目前程序的vruntime小,且兩者差距(vdiff)大于sched_wakeup_granularity_ns的情況下,才可以搶占,否則不可以。這個參數越大,發生喚醒搶占就越不容易。增加該值會降低喚醒操作的次數,并減少對計算密集型任務的影響(有利于計算密集型任務);降低該值會增加喚醒的延遲和吞吐量,有利于I/O密集型任務。參見該實驗
/sys/block/<dev>/queue:
- read_ahead_kb:定義了順序讀操作中,作業系統可能預讀的最大千位元組數。預讀之後,由于下一次順序讀取所需要的資訊已經存在于核心頁高速緩存中,進而提高了讀取I/O性能。預設采用128KB,将該值增大到4-8MB可能會提升應用對大型檔案順序讀取的性能。
TRANSLATE with
x
English
| Arabic | Hebrew | Polish |
| Bulgarian | Hindi | Portuguese |
| Catalan | Hmong Daw | Romanian |
| Chinese Simplified | Hungarian | Russian |
| Chinese Traditional | Indonesian | Slovak |
| Czech | Italian | Slovenian |
| Danish | Japanese | Spanish |
| Dutch | Klingon | Swedish |
| English | Korean | Thai |
| Estonian | Latvian | Turkish |
| Finnish | Lithuanian | Ukrainian |
| French | Malay | Urdu |
| German | Maltese | Vietnamese |
| Greek | Norwegian | Welsh |
| Haitian Creole | Persian |
COPY THE URL BELOW
Back
EMBED THE SNIPPET BELOW IN YOUR SITE
Enable collaborative features and customize widget: Bing Webmaster Portal