二、安裝上手
1. Elasticsearch的安裝和簡單配置
- Elasticsearch非常容易在個人電腦上搭建環境
2. 下載下傳Elasticsearch安裝包elasticsearch.cn/download/3. Elasticsearch還有官方的Docker鏡像,我們可以在Docker中很容易的啟動它
2. Elasticsearch的檔案目錄結構
| 目錄 | 配置檔案 | 描述 |
|---|---|---|
| bin | 腳本啟動,包括啟動Elasticsearch,安裝插件。運作統計資料等 | |
| config | elasticsearch.yml | 叢集配置檔案,user,role based 相關配置 |
| JDK | Java運作環境 | |
| data | path.data | 資料檔案 |
| lib | Java類庫 | |
| logs | path.log | 日志檔案 |
| modules | 包含所有ES子產品 | |
| plugins | 包含所有已安裝插件 |
2.1 JVM配置
- 修改 config/jvm.options,7.1版本的預設設定時 1 GB
- Xmx和Xms設定成一樣
- Xmx不要超過機器記憶體的50%
- 不要超過30GB - [https://www.elastic.co/blog/a-heap-of-trouble]
3. 運作Elasticsearch
3.1 啟動出現的問題
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- 每個程序最大同時打開檔案數太小,可通過下面2個指令檢視目前數量
ulimit -Hn
ulimit -Sn複制代碼 - 修改/etc/security/limits.conf檔案,增加配置,使用者退出後重新登入生效
* soft nofile 65536
* hard nofile 65536複制代碼 max number of threads [3818] for user [es] is too low, increase to at least [4096]
- 問題同上,最大線程個數太低。修改配置檔案/etc/security/limits.conf(和問題1是一個檔案),增加配置
* soft nproc 4096
* hard nproc 4096複制代碼 - 可通過指令檢視
ulimit -Hu
ulimit -Su複制代碼 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
- 修改/etc/sysctl.conf檔案,增加配置vm.max_map_count=262144
vi /etc/sysctl.conf
sysctl -p複制代碼 - 執行指令sysctl -p生效
3.2 啟動
/opt/module/elasticsearch-7.1.0/bin/elasticsearch複制代碼 - 打開浏覽器輸入:http://192.168.37.130:9200/
4. 為Elasticsearch安裝插件(我們可以利用插件來實作一些安全政策,來保護我們存儲的資料)
4.1 檢視目前Elasticsearch已經安裝的插件
[root@hadoop101 elasticsearch-7.1.0]# bin/elasticsearch-plugin list複制代碼 4.2 安裝analysis-icu(analysis是一個國際化的分詞插件)
[root@hadoop101 elasticsearch-7.1.0]# bin/elasticsearch-plugin install analysis-icu複制代碼 4.3 頁面檢視安裝的插件
http://192.168.37.130:9200/_cat/plugins

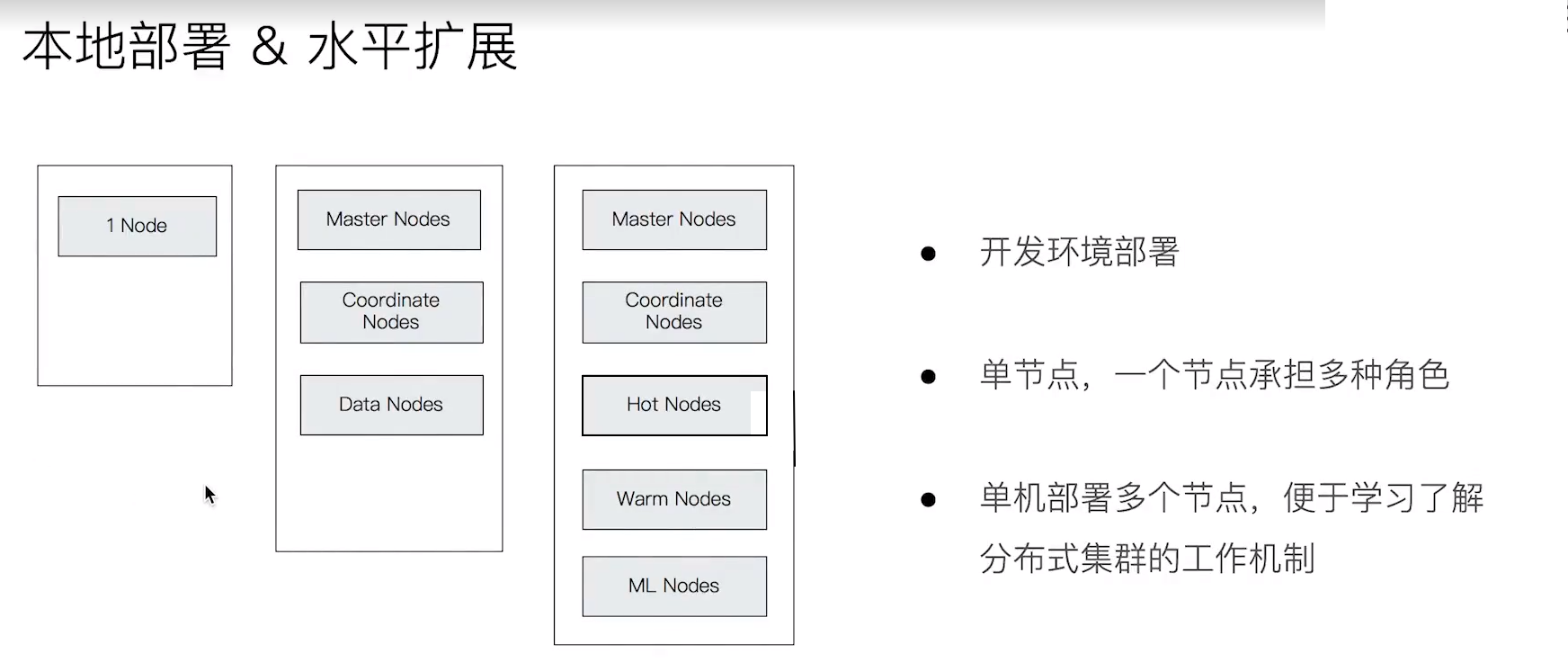
5. 在開發機上運作多個Elasticsearch執行個體
- Elasticsearch中一個很大的特色就是以分布式的方式去運作,也就是說你可以在多台機器上去運作多個Elasticsearch執行個體,這些執行個體最後組成一個大的叢集
- 我們現在要在本機以一個多執行個體的方式去運作它,來了解它的機制
5.1 修改config/elasticsearch.yml
# 叢集名稱
cluster.name: geektime
# 是否鎖住記憶體
bootstrap.memory_lock: false
# 連接配接位址
network.host: 192.168.2.101
# 候選主節點清單
discovery.seed_hosts: ["192.168.2.101:9301","192.168.2.101:9302","192.168.2.101:9303"]
# 初始化叢集主節點清單
cluster.initial_master_nodes: ["node1","node2","node3"]
# 開啟跨域通路支援,預設為false
http.cors.enabled: true
# # 跨域通路允許的域名位址,(允許所有域名)以上使用正則
http.cors.allow-origin: "*"複制代碼 5.2 修改config/jvm.options
- 因為我是在虛拟機上,記憶體不是很大,是以這裡将JVM記憶體調小一點
-Xms512M
-Xmx512M複制代碼 5.3 建立資料目錄和日志目錄
#建立資料目錄和日志目錄
cd data; mkdir data1 data2 data3
cd logs; mkdir logs1 logs2 logs3複制代碼 5.4 啟動
# 啟動(同一台機子)
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=data/data1 -E path.logs=logs/logs1 -E http.port=9201 -E transport.tcp.port=9301 -E node.master=true -E node.data=true
bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=data/data2 -E path.logs=logs/logs2 -E http.port=9202 -E transport.tcp.port=9302 -E node.master=true -E node.data=false
bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=data/data3 -E path.logs=logs/logs3 -E http.port=9203 -E transport.tcp.port=9303 -E node.master=true -E node.data=false複制代碼 - 通路:http://192.168.37.130:9201/_cat/nodes,就可以看到叢集中的節點了
6. Kibana的安裝和界面快速浏覽
6.1 下載下傳(都是國内的社群)
- elasticsearch.cn/download/
6.2 配置
- 修改config/Kibana.yml
# 用于在任何主機都可以通路
server.host: "0.0.0.0"
# es的位址,這個它預設是9200端口,我們現在啟動的是9201、9202、9203,是以這裡需要配置一下
elasticsearch.hosts: ["http://192.168.37.130:9201"]複制代碼 6.3 啟動
[els@hadoop101 kibana-7.1.0-linux-x86_64]$ bin/kibana複制代碼 6.4 設定中文
- 在kibana.yml配置檔案中添加一行配置 i18n.locale: "zh-CN"
6.4 通路及簡單介紹
- 通路:http://192.168.37.130:5601/
7. 在Docker容器中運作Elasticsearch Kibana和Cerebro
7.1 安裝Docker和Docker Compose
自行百度安裝
7.2 Docker Compose相關指令
- docker-compose up: 運作
- docker compose down
- docker compose down -v
- docker stop/rm containerID
7.3 運作Docker-comose,本地建構開發環境,直覺了解Elasticsearch分布式特性,并內建Cerebro,友善檢視叢集狀态
7.3.1 docker-compose.yaml檔案
version: '2.2'services:
cerebro:image: lmenezes/cerebro:0.8.3container_name: cerebroports: - "9000:9000"command: - -Dhosts.0.host=http://elasticsearch:9200networks: - es7net
kibana:image: docker.elastic.co/kibana/kibana:7.1.0container_name: kibana7environment: - I18N_LOCALE=zh-CN - XPACK_GRAPH_ENABLED=true - TIMELION_ENABLED=true - XPACK_MONITORING_COLLECTION_ENABLED="true"ports: - "5601:5601"networks: - es7net
elasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_01environment: - cluster.name=geektime - node.name=es7_01 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - discovery.seed_hosts=es7_01,es7_02 - cluster.initial_master_nodes=es7_01,es7_02ulimits: memlock:soft: -1hard: -1volumes: - es7data1:/usr/share/elasticsearch/dataports: - 9200:9200networks: - es7net
elasticsearch2:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_02environment: - cluster.name=geektime - node.name=es7_02 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - discovery.seed_hosts=es7_01,es7_02 - cluster.initial_master_nodes=es7_01,es7_02ulimits: memlock:soft: -1hard: -1volumes: - es7data2:/usr/share/elasticsearch/datanetworks: - es7netvolumes:
es7data1:driver: local
es7data2:driver: localnetworks:
es7net:driver: bridge複制代碼 7.3.2 啟動運作
- 進入有docker-compose.yaml檔案的目錄運作
- 我這裡的目錄在``
docker-compose up複制代碼 8. Logstash安裝與導入資料
8.1 下載下傳并安裝
- 下載下傳時,我們必須要保證我們的Logstash的版本和我們的Elasticsearch的版本一緻
8.2 下載下傳logstash資料檔案
- D:\WorkSpace\rickying-geektime-ELK-master
- 并将資料導入到Linux中的/opt/module/logstash_data
8.2 修改logstash.conf配置檔案
input {
file {
path => "/opt/module/logstash-7.1.0/bin/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}複制代碼 8.3 指定配置檔案運作logstash
./logstash -f logstash.conf複制代碼