| 這個作業屬于哪個課程 | 2021春軟體工程實踐|S班 |
|---|---|
| 這個作業要求在哪裡 | 軟工實踐寒假作業(2/2) |
| 這個作業的目标 | 1.閱讀《建構之法》提問 2.WordCount程式設計 |
| 其他參考文獻 | CSDN相關部落格以及部落格園相關部落格 |
目錄
- 任務一 重新閱讀《建構之法》并提問
- 1. 問題一
- 2. 問題二
- 3. 問題三
- 4. 問題四
- 5. 問題五
- 任務二 WordCount程式設計
- 1. Github項目位址:
- 2. PSP表格:
- 3. 代碼規範制定連結
- 4. 設計與實作過程
- 5. 性能改進
- 6. 單元測試
- 7. 異常處理說明
- 8. 心路曆程與收獲
4.5 結對程式設計 中 "結對程式設計讓兩個人所寫的代碼不斷地處于“複審”的過程,程式員們能夠不斷地稽核,提高設計和編碼品質,可以及時發現并解決問題,避免把問題拖到後面的階段去。 "
在本次個人作業中,我與同學也曾為了實作一個功能連着麥修改了一下午的代碼,我想這也算是結對程式設計吧,但是在這個過程中我發現如果有一方主導意識較強,就容易将問題帶入一個死結。且在這個過程中我們還産生了分歧,那麼這個時候是否應該結束結對程式設計,各自實作自己的想法呢?還是兩人應當按順序,一起先嘗試其中一個人的想法,再一起嘗試另一個思路,然後對比取更優呢?
3.2 軟體工程師的職業發展 "邁克康奈爾把工程師分為8個級别(8—15),一個工程師要從一個級别升到另一個級别,
需要在各方面達到一定的要求。例如,要達到12級,工程師必須在三個知識領域
達到“帶頭人”水準。例如要到達“工程管理(知識領域)的熟練(能力)”水準,工程師必須要做到以下幾點。閱讀: 4—6個經典文獻的深入分析和閱讀工作經驗: 要參與并完成6個具體的項目課程: 要參加3個專門的課程有些級别"
到目前為止我看過的關于程式設計的書屈指可數,在學習新技術的時候我偏向于在網絡上學習,畢竟網絡上的技術文章是最新的,那麼,閱讀經典文獻的必要性在哪呢?
5.2.1 主治醫生模式 "在一些學校裡,軟體工程的團隊模式往往從這一模式退化為“一個學生幹活,其餘學生跟着打醬油”"
這種情況的确很常見,但是如果在其他學生的水準都較低,對于那個水準高的學生來說,自己完成比教會他們再與他們合作效率不是高多了嗎? 但這種模式也是合理的吧,特别是對于高年級學生來說,如果參加競賽,對于隊伍中的新生,不就應該帶他們嗎?
11.5.1 閉門造車 "小飛:我今天真失敗!在辦公室裡坐了10個小時,但是真正能花在開發工作上的
時間可能隻有3個
小時,然後我的工作進展大概隻有兩個小時!
阿超:那你的時間都花到哪裡去了?"
對于這個問題我深有體會,在完成個人項目的過程中,我常常一坐就是一整天,對着一個bug能改一個下午,但其實隻是一個很小的錯誤,就很容易陷入這樣的迷惑中,不獨處呢,很難進入狀态工作,一個人呢,又會發散了思維,那我以後去公司裡工作該怎麼辦呢
16.1 創新的迷思 "最近幾年,我們整個社會似乎對創新很感興趣,媒體上充斥了創新型的人才、創新型的學校、創新型的公司、創新型的城市、創新型的社會,等等名詞。有些城市還把“創新”當作城市的精神之一,還有城市要批量生産上千名頂級創新人才。"
一直有聽說前輩創業的事迹,但在進入專業學習了三年,我發現創新并不是那麼容易的,你想實作的功能早就有人實作了并且已經失敗了,甚至找不到創新的方向,那些自稱創新型的事物,是否誇大其詞了。還有就是對于那些熱門的新技術方向,真正接觸了發現你能夠聽到的新技術,其實已經有許多先行者了。
項目位址
| Personal Software Process Stages | 預估耗時(分鐘) | 實際耗時(分鐘) |
|---|---|---|
| 計劃 | ||
| 預估這個任務需要多少時間 | 20 | 30 |
| 開發 | ||
| 需求分析(包括學習新技術) | 240 | 200 |
| 生成設計文檔 | 30min | 20min |
| 設計複審 | 15min | |
| 代碼規範 | 40min | |
| 具體設計 | 60min | |
| 具體編碼 | 1000min | 1200min |
| 代碼複審 | 120min | 600min |
| 測試 | ||
| 測試報告 | ||
| 計算工作量 | ||
| 事後總結,并提出過程改進計劃 | 10min | |
| 總和 | 1665min | 2215min |
codestyle
- 第一階段:複習git,複習java文法,編寫了我的代碼規範
這一階段的任務由于在寒假就有複習,是以進行的比較快。同時還根據《碼出高效_阿裡巴巴Java開發手冊》結合我本人習慣,編寫我的代碼規範。由于之前未使用過GithubDesktop,在這個階段也安裝下載下傳,并學習了如何使用。
- 第二階段:
- 程式需求分析:
- 擷取檔案輸入
- 統計檔案ascii碼字元數
- 統計符合規則的單詞數
- 統計檔案的有效行數
- 統計出現次數最多的單詞及出現次數(輸出前十)
- 輸出結果到檔案
- 程式需求分析:
- 我的類結構:
- WordCount
- main
- Lib
- readTxt
- outputToTxt
- countChar
- countLine
- sortHashMap
- findLegal
- countWordNum
- WordCount
- 解題思路:
- 檔案輸入
最開始我打算用BufferedReader去處理檔案輸入,通過readLine()方法一次讀取一行,然後将讀取的字元串用換行符"\n"拼接起來。但在測試中發現,讀出的文本的ASCII碼比預期的少,又回去仔細閱讀了題目,發現文本中的換行并不是簡單的"\n",還有"\r"、"\r\n"這種情況,是以如果用readLine()可能會使得文本字元變少。通過百度查找資料後,我決定采用BufferedInputStream的read()函數來讀取,一次緩沖10m的文本。關鍵代碼如下:
byte[] bytes = new byte[BUFF_SIZE]; int len; while((len=bufferedInputStream.read(bytes)) != -1){ stringBuffer.append(new String(bytes, 0,len,StandardCharsets.UTF_8)); } ... } catch (IOException e){ ... } return stringBuffer.toString(); - 統計檔案ASCII碼字元數
一開始沒認真審題,将問題複雜化了,通過正則比對去統計。
後來發現由于題目說明給定的文本都是ASCII字元,是以隻需傳回讀取檔案的字元串的長度即可。String regex = "\\p{ASCII}"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(text); while (matcher.find()){ num++; } -
- 單詞的規則:至少以4個英文字母開頭,跟上字母數字元号,不區分大小寫
- 我想到的辦法是先将文本用split方法分隔開,分隔用的正規表達式為:
[^ A-Za-z0-9_]|\\s+
,得到一個不含分隔符的字元串數組。再用一次循環用正則'[1]{4,}.*'去判斷是否為合法單詞。
将文本分割:
public static String[] splitWord(String text){ String[] words; String regexForSplit = "[^ A-Za-z0-9_]|\\s+"; words = text.split(regexForSplit); return words; }- 判斷是否合法單詞
public static List<String> splitLegalWord(String[] words){ List<String> legalWords = new ArrayList<String>(); String regexForMatch = "^[a-zA-Z]{4,}.*"; for(int i=0 ; i<words.length; i++){ if(words[i].matches(regexForMatch)){ legalWords.add(words[i].toLowerCase()); } } return legalWords; } -
用正規表達式去比對空白字元(三種),然後用split将文本分割,就得到了每個字元串為一行的字元串數組,然後再周遊過程中判斷是否空行,這裡用trim是為了防止含有空格或tab制表符的無效行被視作有效行算入行數中。
String[] lines = text.split("\r\n|\r|\n"); for(int i=0; i<lines.length; i++){ if (!lines[i].trim().isEmpty()){ num++; } }
将存放單詞和單詞出現次數的hashMap轉換為list,然後對list進行排序,重寫compare方法使得排序依據:從大到小排序,頻率相同的單詞,優先輸出字典序靠前的單詞,選取前十條記錄。public static List<Map.Entry<String, Integer>> sortHashMap(HashMap<String, Integer> hashMap){ Set<Map.Entry<String, Integer>> entry = hashMap.entrySet(); List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(entry); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if(o1.getValue().equals(o2.getValue())){ return o1.getKey().compareTo(o2.getKey()); } return o2.getValue()-o1.getValue(); } }); //最多隻取10條 if(list.size()>10) { return list.subList(0,10); } else{ return list; } }
簡單地用BufferedWriteer按行寫入到檔案中。bufferedWriter.write("characters:"+num1+"\r\n"); bufferedWriter.write("words:"+num2+"\r\n"); bufferedWriter.write("lines:"+line+"\r\n"); for(int i=0; i<list.size()&&i<10; i++){ String key = list.get(i).getKey(); Integer value = list.get(i).getValue(); bufferedWriter.write(key+":"+value+"\r\n"); }
-
初次性能測試:
用于測試的文本大小為:95.3mb(100,000,000 位元組,用來測試的檔案由該檔案[GenerateText][]随機生成) 需要的運作時間為:54834ms 這個數字着實吓了我一跳,因為其他人的運作時間是遠遠低于我的。 使用了緩沖區後 改進時間為50212ms。
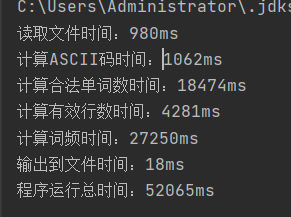
軟工實踐寒假作業 (2/2) -
算法優化
在對執行各個子產品的時間分析後,我發現耗時最高的是計算單詞數以及統計詞頻,由于算法不當以及一開始對各個方法獨立性的錯誤追求,在拆分單詞處進行了重複計算,在和洋藝同學交流後發現其實計算單詞的時候就可以用hashMap記錄詞頻的
- 改進前:先用split方法提取出獨立的字元串,存放在字元串數組中,然後再用 "[2]{4,}.*" 去比對每一個字元串,用List 存放合法的單詞。用的是matches方法。據星源同學所說這兩個方法效率極低,否則我也沒意識到在這個地方有什麼可以改進的地方,非常感謝他555。
- 改進後:直接對文本字元串進行比對,通過Matcher的find方法取出符合規則的單詞,并且統計單詞的出現次數,存放到HashMap<String, Integer>裡。不過這樣的正規表達式比較複雜,而且需要在文本字元串開頭添加一個空白字元。正規表達式:"([^ a-z0-9])([a-z]{4}[a-z0-9]*)"。關鍵代碼:
Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(text); HashMap<String, Integer> legalWords = new HashMap<String, Integer>(); //直接把單詞和出現頻率一起做了,放到hashMap裡 while(matcher.find()){ wordNum++; String tmp = matcher.group(2).trim(); if(!legalWords.containsKey(tmp)){ legalWords.put(tmp,1); } else{ legalWords.put(tmp, legalWords.get(tmp)+1); } } return legalWords; }- 對CountLine進行了優化,畢竟用split方法實在是太耗時且占用記憶體了,我用大小為476 MB (500,000,000 位元組)的文本去跑,程式直接崩潰了,原因是堆溢出。在經過百度以及和鄒洋藝同學探讨過後,決定采用正則比對來計算行數。
public static int countLine(String text){ int num=0; String regex = "(.*)(\\s)"; Matcher matcher = regexUtils(regex, text); while (matcher.find()){ String tmp = matcher.group(1); if(!tmp.trim().isEmpty()){ num++; } } return num; }
- 對CountLine進行了優化,畢竟用split方法實在是太耗時且占用記憶體了,我用大小為476 MB (500,000,000 位元組)的文本去跑,程式直接崩潰了,原因是堆溢出。在經過百度以及和鄒洋藝同學探讨過後,決定采用正則比對來計算行數。
-
多線程執行:
發現統計單詞詞頻和計算行數這兩個工作并不重複,而且耗時也都比較長,是以想到是否可以通過多線程來執行這兩個任務。由于兩個方法都需要傳回值,是以實作的是Callabel接口
Callable callable1 = new Callable() { HashMap<String, Integer> legalWords; @Override public HashMap<String, Integer> call() { long startTime1 = System.currentTimeMillis(); try { Thread.sleep(5); }catch (Exception e){ e.printStackTrace(); } this.legalWords = SplitWord.findLegal(content); countDownLatch.countDown(); long endTime1 = System.currentTimeMillis(); System.out.println("線程1運作時間:"+(endTime1-startTime1)+"ms"); return legalWords; } }; futureTask1 = new FutureTask<HashMap<String, Integer>>(callable1); new Thread(futureTask1).start(); //執行線程
coutDownLatch使主線程等待兩個子線程都完成後才能繼續執行。Callable callable2 = new Callable() { Integer line; @Override public Integer call() { long startTime2 = System.currentTimeMillis(); line = CountLine.countLine(content); countDownLatch.countDown(); long endTime2 = System.currentTimeMillis(); System.out.println("線程2運作時間:"+(endTime2-startTime2)+"ms"); return line; } }; futureTask2 = new FutureTask<Integer>(callable2); new Thread(futureTask2).start();
軟工實踐寒假作業 (2/2) 軟工實踐寒假作業 (2/2) 可以看到,兩個線程是并行的且主線程等兩個線程都執行完畢才繼續執行。
性能改進後,測試95.3mb(100,000,000 位元組)的檔案,所需要的時間為:7053ms,相對于優化之前的50000多ms有了相當大的改進。
-
最開始的單元測試是很笨的通過main方法,寫好方法後在main中調用,并對方法的運作時間進行記錄。後來得知可以使用JUnit插件來進行單元測試,單元測試就變得簡單友善多了,也更加有針對性。在程式設計過程中,我進行了多次的單元測試,在確定功能正常後才進行下一步。
1.字元統計
@Test public void countChar() { String content = ReadTxt.readTxt(path+"input7.txt"); long startTime1 = System.currentTimeMillis(); System.out.println(CountAsciiChar.countChar(content)); long endTime1 = System.currentTimeMillis(); System.out.println("計算ASCII時間:"+(endTime1-startTime1)+"ms"); }- 單詞計算
@org.junit.Test public void countWordNum() { num = CountWord.countWordNum(text); System.out.println(num); }- 統計頻率
@Test public void sortHashMap() { list = CountFrequency.sortHashMap(legalWords); for(int i=0; i<list.size()&&i<10; i++){ String key = list.get(i).getKey(); Integer value = list.get(i).getValue(); System.out.println(key+":"+value+"\r\n"); } } -
代碼覆寫率測試
我的覆寫率情況為:類的覆寫率為100%,方法的覆寫率為100%,代碼行覆寫率為88%。
軟工實踐寒假作業 (2/2)
程式中主要會出現的異常是檔案操作以及指令行輸入指令的錯誤。
在檔案操作的相應代碼中都添加了try catch結構來捕獲異常
- 心路曆程
早就聽聞軟體工程實踐的大名,真正上這門課的時候确實有害怕,怕自己程式設計能力太差,就和我一直對參加競賽有着莫名的恐懼一樣,害怕自己能力不足,無法在規定的時間内完成任務,特别是在規定時間内要完成新技術的學習,然後馬上投入應用。但是既然開始了,那也就隻能克服恐懼了。
本次作業是個人程式設計任務,看到題目的時候我有點欣喜又有點迷茫,欣喜是因為這和我們以前編過的程式功能沒什麼本質差別,迷茫則是作業要求裡又有許多我沒接觸過的東西,什麼 單元測試、性能改進,什麼叫單元測試?又怎麼去分析程式的性能呢?
剛開始的時候手忙腳亂的,雖然以前也用過git,但是并不熟練,隻會簡單的pull和push,于是我的commit記錄裡就多了一條送出測試hhhhh,這還導緻我最後多commit了2次來删去之前多送出的檔案。
但随着一個功能一個功能的實作我開始進入狀态了,連續好幾天都是從早上坐到晚上,有些代碼寫了改,改了删,還會有些莫名其妙的bug,記得最深刻的是BufferedStream的read函數的一個用法錯誤,導緻我讀取的文本内容産生了差錯,然後那個bug我從早上改到晚上,就是沒有改出來,最後發現是沒有指定每次從緩沖區讀取的長度,改出來的時候差點從椅子上跳起來哈哈哈哈哈,興奮又懊惱,懊惱自己怎麼會犯這麼低級的錯誤,而且效率還這麼低。 我反思了一下,是因為缺少合理的休息,一直坐在電腦前是效率底下的,coding期間必須合理地休息。
在初次實作了功能後,我以為自己的程式很可以了...直到運作了大檔案,我發現我的程式崩潰了...于是接下來就是各種百度,還有和同學交流探讨,針對計算單詞這個功能,我甚至和洋藝同學連着麥,我倆邊交流改了一下午才改出來。看見其他同學的方法效率比我的高我就忍不住想問問如何實作的,但又怕被算作抄襲,同時時間也來不及了,就沒有更深的改進。
最後完成的時候感覺心裡放下了一塊大石頭
- 收獲&不足
- 提高了自己的程式設計水準,抗壓力能力也變高了不少,畢竟這幾天頭發沒少掉,熬夜也是每天。
- 熟練使用git和gitdesktop,為以後的團隊合作打下基礎
- 效率過低,一個小bug由于思維誤區改了一下午
- 沒做好充分的準備就開始編寫代碼,導緻代碼複審和性能分析的時候發現自己的算法過于差勁。其實應該在動手編寫代碼之前先找到最佳的算法,然後再動手實作。
- a-zA-Z ↩︎