因為生病,另外還在做牙齒的根管治療,痛不欲生,短更一篇。
年前都在梳理《大資料成神之路》的目錄還有内容,另外Flink的公開課程也在規劃大綱和目錄。不知道我在說什麼,看一下這裡《2020年要做的幾件大事》。
昨天有個同學問了我一個問題。Hive中的檔案存儲格式該選什麼?
然後在找到這個關于ORC的文章。如果你英文很好,參考這裡:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
一、ORC檔案格式
ORC的全稱是(Optimized Record Columnar),使用ORC檔案格式可以提高hive讀、寫和處理資料的能力。ORC在RCFile的基礎上進行了一定的改進,是以與RCFile相比,具有以下一些優勢:
- 1、ORC中的特定的序列化與反序列化操作可以使ORC file writer根據資料類型進行寫出。
- 2、提供了多種RCFile中沒有的indexes,這些indexes可以使ORC的reader很快的讀到需要的資料,并且跳過無用資料,這使得ORC檔案中的資料可以很快的得到通路。
- 3、由于ORC file writer可以根據資料類型進行寫出,是以ORC可以支援複雜的資料結構(比如Map等)。
- 4、除了上面三個理論上就具有的優勢之外,ORC的具體實作上還有一些其他的優勢,比如ORC的stripe預設大小更大,為ORC writer提供了一個memory manager來管理記憶體使用情況。
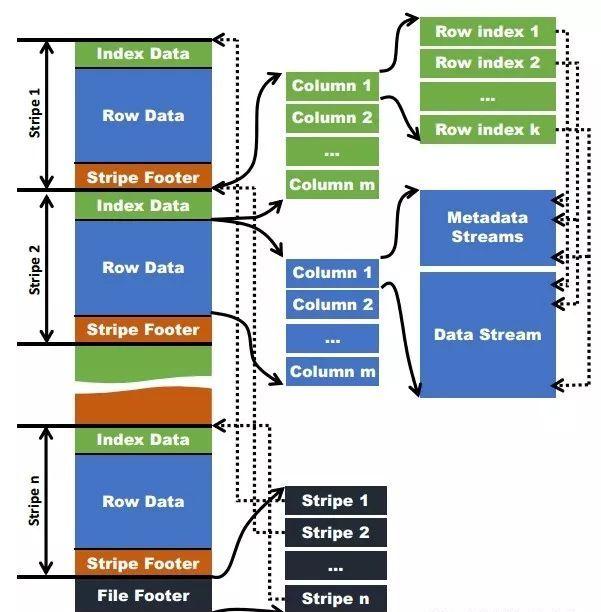
圖1-ORC檔案結構圖
二、ORC資料存儲方法
在ORC格式的hive表中,記錄首先會被橫向的切分為多個stripes,然後在每一個stripe内資料以列為機關進行存儲,所有列的内容都儲存在同一個檔案中。每個stripe的預設大小為256MB,相對于RCFile每個4MB的stripe而言,更大的stripe使ORC的資料讀取更加高效。
對于複雜資料類型,比如Map,ORC檔案會将一個複雜資料類型字段解析成多個子字段。下表中列舉了ORC檔案中對于複雜資料類型的解析
| Data type | Chile columns |
|---|---|
| Array | 一個包含所有數組元素的子字段 |
| Map | 兩個子字段,一個key字段,一個value字段 |
| Struct | 每一個屬性對應一個子字段 |
| Union |
當字段類型都被解析後,會由這些字段類型組成一個字段樹,隻有樹的葉子節點才會儲存表資料,這些葉子節點中的資料形成一個資料流,如上圖中的Data Stream。
為了使ORC檔案的reader更加高效的讀取資料,字段的metadata會儲存在Meta Stream中。在字段樹中,每一個非葉子節點記錄的就是字段的metadata,比如對一個array來說,會記錄它的長度。下圖根據表的字段類型生成了一個對應的字段樹。

在Hive-0.13中,ORC檔案格式隻支援讀取指定字段,還不支援隻讀取特殊字段類型中的指定部分。
使用ORC檔案格式時,使用者可以使用HDFS的每一個block存儲ORC檔案的一個stripe。對于一個ORC檔案來說,stripe的大小一般需要設定得比HDFS的block小,如果不這樣的話,一個stripe就會分别在HDFS的多個block上,當讀取這種資料時就會發生遠端讀資料的行為。如果設定stripe的隻儲存在一個block上的話,如果目前block上的剩餘空間不足以存儲下一個strpie,ORC的writer接下來會将資料打散儲存在block剩餘的空間上,直到這個block存滿為止。這樣,下一個stripe又會從下一個block開始存儲。
三、索引
在ORC檔案中添加索引是為了更加高效的從HDFS讀取資料。在ORC檔案中使用的是稀疏索引(sparse indexes)。在ORC檔案中主要有兩種用途的索引,一個是資料統計(Data Statistics)索引,一個是位置指針(Position Pointers)索引。
1. Data Statistics
ORC reader用這個索引來跳過讀取不必要的資料,在ORC writer生成ORC檔案時會建立這個索引檔案。這個索引中統計的資訊主要有記錄的條數,記錄的max, min, sum值,以及對text類型和binary類型字段還會記錄其長度。對于複雜資料類型,比如Array, Map, Struct, Union,它們的子字段中也會記錄這些統計資訊。
在ORC檔案中,Data Statistics有三個level。
(1)file level statistics
在ORC檔案的末尾會記錄檔案級别的統計資訊,會記錄整個檔案中columns的統計資訊。這些資訊主要用于查詢的優化,也可以為一些簡單的聚合查詢比如max, min, sum輸出結果。
(2)stripe level statistics
ORC檔案會儲存每個字段stripe級别的統計資訊,ORC reader使用這些統計資訊來确定對于一個查詢語句來說,需要讀入哪些stripe中的記錄。比如說某個stripe的字段max(a)=10,min(a)=3,那麼當where條件為a >10或者a <3時,那麼這個stripe中的所有記錄在查詢語句執行時不會被讀入。
(3)index group level statistics
為了進一步的避免讀入不必要的資料,在邏輯上将一個column的index以一個給定的值(預設為10000,可由參數配置)分割為多個index組。以10000條記錄為一個組,對資料進行統計。Hive查詢引擎會将where條件中的限制傳遞給ORC reader,這些reader根據組級别的統計資訊,過濾掉不必要的資料。如果該值設定的太小,就會儲存更多的統計資訊,使用者需要根據自己資料的特點權衡一個合理的值。
3. Position Pointers
當讀取一個ORC檔案時,ORC reader需要有兩個位置資訊才能準确的進行資料讀取操作。
(1)metadata streams和data streams中每個group的開始位置
由于每個stripe中有多個group,ORC reader需要知道每個group的metadata streams和data streams的開始位置。圖1中右邊的虛線代表的就是這種pointer。
(2)stripes的開始位置
由于一個ORC檔案可以包含多個stripes,并且一個HDFS block也能包含多個stripes。為了快速定位指定stripe的位置,需要知道每個stripe的開始位置。這些資訊會儲存在ORC file的File Footer中。如圖1中間位置的虛線所示。
四、檔案壓縮
ORC檔案使用兩級壓縮機制,首先将一個資料流使用流式編碼器進行編碼,然後使用一個可選的壓縮器對資料流進行進一步壓縮。
一個column可能儲存在一個或多個資料流中,可以将資料流劃分為以下四種類型:
• Byte Stream
位元組流儲存一系列的位元組資料,不對資料進行編碼。
• Run Length Byte Stream
位元組長度位元組流儲存一系列的位元組資料,對于相同的位元組,儲存這個重複值以及該值在位元組流中出現的位置。
• Integer Stream
整形資料流儲存一系列整形資料。可以對資料量進行位元組長度編碼以及delta編碼。具體使用哪種編碼方式需要根據整形流中的子序列模式來确定。
• Bit Field Stream
比特流主要用來儲存boolean值組成的序列,一個位元組代表一個boolean值,在比特流的底層是用Run Length Byte Stream來實作的。
接下來會以Integer和String類型的字段舉例來說明。
(1)Integer
對于一個整形字段,會同時使用一個比特流和整形流。比特流用于辨別某個值是否為null,整形流用于儲存該整形字段非空記錄的整數值。
(2)String
對于一個String類型字段,ORC writer在開始時會檢查該字段值中不同的内容數占非空記錄總數的百分比不超過0.8的話,就使用字典編碼,字段值會儲存在一個比特流,一個位元組流及兩個整形流中。比特流也是用于辨別null值的,位元組流用于存儲字典值,一個整形流用于存儲字典中每個詞條的長度,另一個整形流用于記錄字段值。
如果不能用字典編碼,ORC writer會知道這個字段的重複值太少,用字典編碼效率不高,ORC writer會使用一個位元組流儲存String字段的值,然後用一個整形流來儲存每個字段的位元組長度。
在ORC檔案中,在各種資料流的底層,使用者可以自選ZLIB, Snappy和LZO壓縮方式對資料流進行壓縮。編碼器一般會将一個資料流壓縮成一個個小的壓縮單元,在目前的實作中,壓縮單元的預設大小是256KB。
五、記憶體管理
當ORC writer寫資料時,會将整個stripe儲存在記憶體中。由于stripe的預設值一般比較大,當有多個ORC writer同時寫資料時,可能會導緻記憶體不足。為了現在這種并發寫時的記憶體消耗,ORC檔案中引入了一個記憶體管理器。在一個Map或者Reduce任務中記憶體管理器會設定一個門檻值,這個門檻值會限制writer使用的總記憶體大小。當有新的writer需要寫出資料時,會向記憶體管理器注冊其大小(一般也就是stripe的大小),當記憶體管理器接收到的總注冊大小超過門檻值時,記憶體管理器會将stripe的實際大小按該writer注冊的記憶體大小與總注冊記憶體大小的比例進行縮小。當有writer關閉時,記憶體管理器會将其注冊的記憶體從總注冊記憶體中登出。
六、參數
| 參數名 | 預設值 | 說明 |
|---|---|---|
| hive.exec.orc.default.stripe.size | 256*1024*1024 | stripe的預設大小 |
| hive.exec.orc.default.block.size | orc檔案在檔案系統中的預設block大小,從hive-0.14開始 | |
| hive.exec.orc.dictionary.key.size.threshold | 0.8 | String類型字段使用字典編碼的門檻值 |
| hive.exec.orc.default.row.index.stride | 10000 | stripe中的分組大小 |
| hive.exec.orc.default.compress | ZLIB | ORC檔案的預設壓縮方式 |
| hive.exec.orc.skip.corrupt.data | false | 遇到錯誤資料的處理方式,false直接抛出異常,true則跳過該記錄 |
更多參數參考:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties#ConfigurationProperties-ORCFileFormat
- MORE | 更多精彩文章 -
- Flink異步之矛-鋒利的Async I/O
- 基于Flink SQL建構實時資料倉庫
- 基于SparkStreaming+Kafka+HBase實時點選流案例
- HyperLogLog函數在Spark中的進階應用
歡迎點贊+收藏+轉發朋友圈素質三連