雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
Kubernetes 叢集中,業務通常采用 Deployment + LoadBalancer 類型 Service 的方式對外提供服務,其典型部署架構如圖 1 所示。這種架構部署和運維都十分簡單友善,但是在應用更新或者更新時可能會存在服務中斷,引發線上問題。今天我們來詳細分析下這種架構為何在更新應用時會發生服務中斷以及如何避免服務中斷。
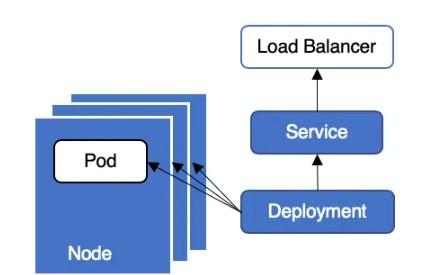
圖1 業務部署圖
為何會發生服務中斷
Deployment 滾動更新時會先建立新 pod,等待新 pod running 後再删除舊 pod。
建立 Pod

圖 2 服務中斷示意圖
中斷原因:Pod running 後被加入到 Endpoint 後端,容器服務監控到 Endpoint 變更後将 Node 加入到 SLB 後端。此時請求從 SLB 轉發到 Pod 中,但是 Pod 業務代碼還未初始化完畢,無法處理請求,導緻服務中斷,如圖 2 所示。
解決方法:為 pod 配置就緒檢測,等待業務代碼初始化完畢後後再将 node 加入到 SLB 後端。
删除 Pod
在删除舊 pod 過程中需要對多個對象(如 Endpoint、ipvs/iptables、SLB)進行狀态同步,并且這些同步操作是異步執行的,整體同步流程如圖 3 所示。
圖 3 Deployment 更新時序圖
Pod
pod 狀态變更:将 Pod 設定為 Terminating 狀态,并從所有 Service 的 Endpoints 清單中删除。此時,Pod 停止獲得新的流量,但在 Pod 中運作的容器不會受到影響;
- 執行 preStop Hook:Pod 删除時會觸發 preStop Hook,preStop Hook 支援 bash 腳本、TCP 或 HTTP 請求;
- 發送 SIGTERM 信号:向 Pod 中的容器發送 SIGTERM 信号;
- 等待指定的時間:terminationGracePeriodSeconds 字段用于控制等待時間,預設值為 30 秒。該步驟與 preStop Hook 同時執行,是以 - - terminationGracePeriodSeconds 需要大于 preStop 的時間,否則會出現 preStop 未執行完畢,pod 就被 kill 的情況;
- 發送 SIGKILL 信号:等待指定時間後,向 pod 中的容器發送 SIGKILL 信号,删除 pod。
中斷原因:上述 1、2、3、4步驟同時進行,是以有可能存在 Pod 收到 SIGTERM 信号并且停止工作後,還未從 Endpoints 中移除的情況。此時,請求從 slb 轉發到 pod 中,而 Pod 已經停止工作,是以會出現服務中斷,如圖 4 所示。
圖 4 服務中斷示意圖
解決方法:為 pod 配置 preStop Hook,使 Pod 收到 SIGTERM 時 sleep 一段時間而不是立刻停止工作,進而確定從 SLB 轉發的流量還可以繼續被 Pod 處理。
iptables/ipvs
中斷原因:當 pod 變為 termintaing 狀态時,會從所有 service 的 endpoint 中移除該 pod。kube-proxy 會清理對應的 iptables/ipvs 條目。而容器服務 watch 到 endpoint 變化後,會調用 slb openapi 移除後端,此操作會耗費幾秒。由于這兩個操作是同時進行,是以有可能存在節點上的 iptables/ipvs 條目已經被清理,但是節點還未從 slb 移除的情況。此時,流量從 slb 流入,而節點上已經沒有對應的 iptables/ipvs 規則導緻服務中斷,如圖 5 所示。
圖 5 服務中斷示意圖
解決方法:
- Cluster 模式:Cluster 模式下 kube-proxy 會把所有業務 Pod 寫入 Node 的 iptables/ipvs 中,如果目前 Node 沒有業務 pod,則該請求會被轉發給其他 Node,是以不會存在服務中斷,如 6 所示;
圖 6 Cluster 模式請求轉發示意圖
- Local 模式:Local 模式下,kube-proxy 僅會把 Node 上的 pod 寫入 iptables/ipvs。當 Node 上隻有一個 pod 且狀态變為 terminating 時,iptables/ipvs 會将該 pod 記錄移除。此時請求轉發到這個 node 時,無對應的 iptables/ipvs 記錄,導緻請求失敗。這個問題可以通過原地更新來避免,即保證更新過程中 Node 上至少有一個 Running Pod。原地更新可以保障 Node 的 iptables/ipvs 中總會有一條業務 pod 記錄,是以不會産生服務中斷,如圖 7 所示;
圖 7 Local 模式原地更新時請求轉發示意圖
- ENI 模式 Service:ENI 模式繞過 kube-proxy,将 Pod 直接挂載到 SLB 後端,是以不存在因為 iptables/ipvs 導緻的服務中斷。
圖 8 ENI 模式請求轉發示意圖
SLB
圖 9 服務中斷示意圖
中斷原因:容器服務監控到 Endpoints 變化後,會将 Node 從 slb 後端移除。當節點從 slb 後端移除後,SLB 對于繼續發往該節點的長連接配接會直接斷開,導緻服務中斷。
解決方法:為 SLB 設定長連結優雅中斷(依賴具體雲廠商)。
如何避免服務中斷
避免服務中斷可以從 Pod 和 Service 兩類資源入手,接下來将針對上述中斷原因介紹相應的配置方法。
Pod 配置
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: default
spec:
containers:
- name: nginx
image: nginx
# 存活檢測
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 就緒檢測
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 優雅退出
lifecycle:
preStop:
exec:
command:
- sleep
- 30
terminationGracePeriodSeconds: 60 注意:需要合理設定就緒檢測(readinessProbe)的探測頻率、延時時間、不健康門檻值等資料,部分應用啟動時間本身較長,如果設定的時間過短,會導緻 POD 反複重新開機。
- livenessProbe 為存活檢測,如果失敗次數到達門檻值(failureThreshold)後,pod 會重新開機,具體配置見官方文檔;
- readinessProbe 為就緒檢查,隻有就緒檢查通過後,pod 才會被加入到 Endpoint 中。容器服務監控到 Endpoint 變化後才會将 node 挂載到 slb 後端;
- preStop 時間建議設定為業務處理完所有剩餘請求所需的時間,terminationGracePeriodSeconds 時間建議設定為 preStop 的時間再加 30 秒以上。
Service 配置
Cluster 模式(externalTrafficPolicy: Cluster)
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
spec:
externalTrafficPolicy: Cluster
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer 容器服務會将叢集中所有節點挂載到 SLB 的後端(使用 BackendLabel 标簽配置後端的除外),是以會快速消耗 SLB quota。SLB 限制了每個 ECS 上能夠挂載的 SLB 的個數,預設值為 50,當 quota 消耗完後會導緻無法建立新的監聽及 SLB。
Cluster 模式下,如果目前節點沒有業務 pod 會将請求轉發給其他 Node。在跨節點轉發時需要做 NAT,是以會丢失源 IP。
Local 模式(externalTrafficPolicy: Local)
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
spec:
externalTrafficPolicy: Local
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
# 需要盡可能的讓每個節點在更新的過程中有至少一個的Running的Pod
# 通過修改UpdateStrategy和利用nodeAffinity盡可能的保證在原地rolling update
# * UpdateStrategy可以設定Max Unavailable為0,保證有新的Pod啟動後才停止之前的pod
# * 先對固定的幾個節點打上label用來排程
# * 使用nodeAffinity+和超過相關node數量的replicas數量保證盡可能在原地建新的Pod
# 例如:
apiVersion: apps/v1
kind: Deployment
......
strategy:
rollingUpdate:
maxSurge: 50%
maxUnavailable: 0%
type: RollingUpdate
......
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: deploy
operator: In
values:
- nginx 容器服務預設會将 Service 對應的 Pod 所在的節點加入到 SLB 後端,是以 SLB quota 消耗較慢。Local 模式下請求直接轉發到 pod 所在 node,不存在跨節點轉發,是以可以保留源 IP 位址。Local 模式下可以通過原地更新的方式避免服務中斷,yaml 檔案如上。
ENI 模式(阿裡雲特有模式)
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/backend-type: "eni"
name: nginx
spec:
ports:
- name: http
port: 30080
protocol: TCP
targetPort: 80
selector:
app: nginx
type: LoadBalancer Terway 網絡模式下,通過設定 service.beta.kubernetes.io/backend-type:"eni" annotation 可以建立 ENI 模式的 SLB。ENI 模式下,pod會直接挂載到 SLB 後端,不經過 kube-proxy,是以不存在服務中斷的問題。請求直接轉發到 pod,是以可以保留源 IP 位址。
三種 svc 模式對比如下表所示:
圖 10 Service 對比
結論
Terway 網絡模式 (推薦方式)
選用 ENI 模式的 svc + 設定 Pod 優雅終止 + 就緒檢測。
Flannel 網絡模式
- 如果叢集中 slb 數量不多且不需要保留源 ip:選用 cluster 模式 + 設定 Pod 優雅終止 + 就緒檢測;
- 如果叢集中 slb 數量較多或需要保留源 ip:選用 local 模式 + 設定 Pod 優雅終止 + 就緒檢測 + 原地更新(保證更新過程中每個節點上至少有一個 Running Pod)。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/live立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-06-03
本文作者:阿裡巴巴雲原生
本文來自:“
掘金”,了解相關資訊可以關注“掘金”