運維開發這個崗位與普通的業務開發不同,與日常的運維工作也不同。要求兼顧開發與運維兩種能力。既要掌握不弱于業務開發的開發技術;又要負責SRE同學日常的運維能力;上線之前,還要像QA同學一樣,對自己的服務進行測試和分級變更。
多種能力的交叉,造就不一樣的視角:這群人給自己起了一個很簡約的名字:DevOps。
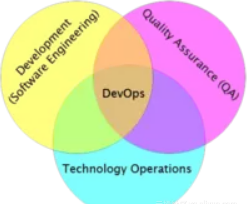
DevOps
按百度百科解釋:DevOps是開發、技術營運和品質保障三者的交集。在我看來,DevOps其實隻是一種方法論,從這種綜合的視角出發,包含一些基本原則和實踐方法,僅此而已。
DevOps從架構、開發、測試、釋出、運維、變更整個流程來考量,從這種綜合的視角出發,能将部門之間的溝通隔閡消滅于無形,會給我們公司和項目注入新的活力。
DevOps這個概念,本文暫不做讨論,本文内容隻針對運維領域自動化平台開發的工作進行探讨。
一、前言
運維開發的工作,所需能力的複雜,工作性質的交叉,自然會導緻很多同學在其中會有些困擾。
很多剛畢業的小同學,接到運維開發的offer的時候,很可能是一頭霧水:“運維?開發?到底是運維還是開發?”
有很多從業多年的同學,拼命的追求技術與對底層的探索,卻忽略了産品層面的思考。
還有很多整天忙忙碌碌的同學,在業務方各種零碎的需求中修修改改,消耗了大多數的時間,最終平台卻變得千瘡百孔。
本文,我将自己關于這些問題的思考分享給大家。
二、什麼樣的平台是好的運維平台?
既然我們是在做平台,那我們要了解的第一點就是:好的運維平台是什麼樣子的?
如果讓我們來從頭設計一個平台,我們應該如何去考量?
1、效率 & 成本的均衡
運維平台是服務于運維的。對運維來說,除了穩定性之外,最重要的無非就是效率與成本。如果我們的平台可以用更少量的時間或資源成本來提高更多的效率,那就是一個非常成功的平台了。
至于如何量化比較,就因系統而異了。
2、體驗 & 人性化
為什麼我要把體驗放在第二位?
因為有太多的運維開發工程師,在開發的過程中,過多地注重系統的穩定性和性能,完全不把體驗放在眼裡了。
我想說的是,有時候,如果不關注使用者體驗,我們做了再好的功能,沒有人用,那這個功能意義何在?使用者價值與使用者體驗在某些情況下,是會畫等号的。
3、優秀的系統架構
在業界,無論是運維系統也好,業務系統也好,優秀系統的架構都是大同小異的:
穩定性:負載均衡、多活等。
擴充性:每次增加功能,可以很小的開發成本實作,而不是每次都要重構。
伸縮性:沒有核心的單點,大部分性能瓶頸,都可以通過橫向擴充來解決。
自我保護:把可能會導緻性能瓶頸的點都拆解開,用隊列、限流等手段消除流量突增的高峰帶來的危害,保護自身。
安全性:敏感服務加入權限與認證,Web服務避免常見的漏洞如SQL注入、XSS、CSRF等。做好操作記錄友善後續審計,盡量不要出現短闆。
三、如何運維自己開發的平台?
運維開發在大多數時候,要負責運維自己開發出來的系統,俗稱吃自己的狗糧;而很多人跳槽之後,第一件事情,也是從運維别人的系統開始的。那我們如何運維好一個平台呢?
運維與開發的工作,思路其實不盡相同。雖然都是基于穩定性來考量,但可能要想的更多、更廣,任何有可能影響到我們業務的穩定性的因素,都要考慮在内。
用我的總監的一句話來講,就是:我們運維同學與開發同學,最大的不同點,就是穩定性的意識。
1、架構上的穩定性
這個其實更多的是比如多活、負載均衡、流量排程、硬體備援之類的考量:服務在執行個體挂掉的時候,如何不影響穩定性;專線斷開的時候,如何仍然正常的提供服務等等。
2、快速地發現問題
無論我們的架構多麼完善,也很難做到盡善盡美。那麼在一些需要人為介入處理的故障中,快速地發現異常,能直接降低服務的不可用時長。是以,對于一般的服務,将報警配置地更完善是我們能快速定位異常的第一步。
還有,對于監控系統,自身的故障不能通過自身的監控來發現,最好還有一套獨立的自監控。
3、應急預案&演練
在梳理一個服務的運維工作的時候,其實我們能很明确的感覺到某個地方出問題需要人力介入。而除變更之外的一般的故障,我們都是可預見的。一旦真的出現這種問題,如果我們沒有準備,即使知道如何去做,也可能會因為手忙腳亂而出錯。
是以,設定一些可能發生情況的應急預案,定時演練,是一個可以在故障時快速恢複服務的手段。
4、自我保護
一般的系統,都有上遊,如何保證上遊的資料異常對自身産生影響,也是很重要的一點。總結起來,總共有三類:
過載保護:上遊流量太大,導緻自身服務不堪負重。這種情況要根據場景不同,考慮加入消息隊列,或者限流。
髒資料保護:上遊來的資料,是否應該完全信任?是否有髒資料會來影響我内部資料的準确性?比如安全掃描的流量,很大程度上就會對很多系統産生髒資料。這種最好有過濾的規則的配置,能摘除這部分流量。
上遊變更保護:上遊的變更,需要及時知曉和跟進。如果上遊不夠規範,很可能會修改接口或者資料格式。即使上遊規範,也要跟進上遊變更容易造成的影響,人為确認沒有問題。
5、容量規劃
随着系統負載的升高,系統的服務能力并不是線性下降的。當負載到達臨界線的時候,一個逐漸變慢的系統最終會停止一切服務。是以,要在系統瓶頸到來之前,預估未來一段時間内服務的量級,在量級到來之前,做好應對措施。
筆者公司目前有一個Topic,就是全鍊路壓測。運維團隊與所有業務團隊一起建設,壓測常态化,每時每刻對系統全鍊路各個環節的瓶頸都了如指掌。其實也是在做這件事情。
6、變更管理
SRE的經驗告訴我們,大概70%的生産事故都是由某種部署的變更而觸發。是以要管理好我們的變更的機制:
- 采用分級釋出機制:先pre、再小流量、再中流量、再全量。
- 制定全面CheckList:保證變更部分所有功能都有測試可以覆寫,能快速發現問題,第一時間復原。
- 出現問題,先復原,再定位:這個不用多說,先止損,再慢慢查問題。
四、除了開發與運維,我們還要做什麼?
運維開發的定位,注定要比業務開發承擔更多的責任。因為這群人除了是自己的RD,還要自己做自己的PM、OP、QA。
是以,我們要考量的,還有産品和需求層面的東西:
1、需求管理
作為開發,尤其是沒有正經PM的開發,管理好需求可以讓我們把精力放在最重要的地方,解放我們的精力、提高産出。
流程閉環:從使用者每次提一個需求開始,一直到這個需求跟進結束,或者需求被讨論後打回,都要有一個詳細的流程管理工具,筆者公司用的是JIRA。有了這個工具,就可以很好的看到需求的狀态,便于跟進和統計,真正解放我們的筆記本。
把控好優先級:根據項目的定位,來劃分需求的優先級。比如,對于一個運維平台項目,一般來講使用者比較固定,針對的是一群高玩SRE,那優先級考量是:穩定性 > 性能 > 功能 > 體驗。
對于優先級的考量,要經常與自己的上級溝通。由于觀點和視野的不同,個人考慮的優先級會與小組或者部門的優先級有所偏離,此時與上級及時的溝通,可以将個人的目标與團隊的目标對齊,争取産出最大化。
- 産品視角 & 抽象能力:我們管理好了需求,确認好了優先級,是不是按照我們的優先級埋頭苦幹就行了呢?答案當然是否定的。視角、見解不同的使用者們提出一堆細碎的需求,如果我們從頭來實作一遍,并不能真正讓這些使用者滿意,卻隻會讓系統越來越爛。
筆者之前就經手維護過這樣的系統,勤勞的工程師兢兢業業,滿足了一個又一個的需求,各種各樣的進階功能。後來,卻由于系統過于複雜,導緻最基本、最常用的功能都要找半天。最終不得不重構。
是以,去深度思考使用者真正需要的是什麼東西,而不是被業務推着走。将使用者細碎的需求,真正抽象成平台要建設的一個一個的功能。
- 經常思考一下:使用者雖然提了這個需求,但是他真正的痛點在哪裡;多個類似需求之間會不會有什麼共通點;是否可以抽象出一個公用的模型,用一個功能來滿足多個需求。
2、量化
If You Can’t Measure It,You Can’t Improve It。量化是優化的前提。
量化有很多方面,比如說量級、延遲、成本,都可以量化。把所有的點量化完之後,我們做事情就不會蒙着頭亂撞,所做的事情、所維護的服務,也不再是一個黑盒。我們可以對它的上下遊關系、自身的穩定性作出宏觀、統籌的分析。進一步的壓測及SLA均要依賴量化。
3、制定SLA
簡言之,SLA就是在一定的限制條件下我們服務可以保證的品質;是服務的維護者完全的了解了自己的系統,對系統的瓶頸有了深刻的了解之後,所給出的服務品質的保證;同時也是我們服務自身能力的一種說明。
一個系統性能再好,也總會有瓶頸。而把瓶頸和風險讓使用者知曉,是我們的義務。對服務的維護者來說,在提供服務之時,約定好服務的SLA,既能從一定程度上規範使用者的行為,也能在出現問題的時候保護自己。
五、除了做這些,我們還要思考什麼?
1、制定規範,并讓規範在平台落地
規範的制定是一個比較宏觀的事情,一般情況是由穩定性負責部門向全公司整體給出的建議。限制的可能是全公司的變更的規則、以及平台的使用方式等。
規範的落地,不能僅僅依靠各方業務的自覺性,也要在平台做好限制與引導。
我們做平台,最終産出的仍然應該是業務的價值:比如效率的提高、成本的降低、穩定性的提高等。規則在平台的落地,可以産生直接的業務價值。
具體的實施方式可以考慮限制和引導兩種手段:
限制:上線視窗的規範,非上線視窗必須走緊急流程由部門一級管理者審批;監控單台機器上報名額數的quota,都是使用的限制的手段。
引導:通過一些方式,讓使用者自覺的依照我們的規則來執行。可以使用獎勵、通報的一些方式。比如筆者公司的變更信用分、監控健康分都是此類手段。
2、協調開發與答疑
運維開發的同學們,除了要做自己的PM和QA之外,有趣的是,還要擔任自己的客服。
日常工作中,經典的答疑主要分為兩類:使用方式、對平台的質疑。
使用方式的日常咨詢,首先可以完善使用者手冊,把所有的使用方式和常見Q&A都寫好。其次可以考慮機器人答疑,目前筆者負責的系統都接入了機器人自動答疑,把一些常見的問題以及文檔都加入到知識庫裡,基本問題都可以解答出來。
除了日常使用的答疑之外,也會有很多的“高玩”來Challenge我們的系統。這些人基本分為兩類:
- 一類是對運維平台有深度思考的人,Chanllenge的同時會帶來很多建設性的意見和建議;
- 另一類就是單純的小白使用者,對系統思考不太深入,喜歡無腦Chanllenge。
我們也要同時思考如何與這類使用者說明,提高小白使用者的體驗。
是以,給出服務的SLA、做好服務的自監控、将所有内部狀态通過自監控暴露給開發者,而不讓自己的服務變成一個黑盒,是我們作為DevOps的基本素質。
六、後記
時光荏苒,倏忽之間,我已從一個小小的實習生,成長到現在勉強可以獨當一面的樣子。這些年來,我一直在自動化運維平台開發領域耕耘。從剛開始重構服務樹、權限系統模型、堡壘機登入;到後來的流量排程、監控系統報警與存儲的深度建設,有很多個人的感悟與成長,梳理了一下,分享給大家。
最後附上筆者思考本文時的腦圖:

原文釋出時間為:2018-05-8本文作者:高家升本文來自雲栖社群合作夥伴“
中生代技術”,了解相關資訊可以關注“
”。