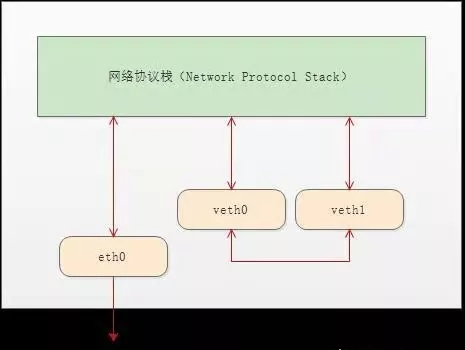
# 建立 namespace
ip netns a ns1
ip netns a ns2
# 建立一對 veth-pair veth0 veth1
ip l a veth0 type veth peer name veth1
# 将 veth0 veth1 分别加入兩個 ns
ip l s veth0 netns ns1
ip l s veth1 netns ns2
# 給兩個 veth0 veth1 配上 IP 并啟用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# 從 veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.073 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.068 ms
--- 10.1.1.3 ping statistics ---
15 packets transmitted, 15 received, 0% packet loss, time 14000ms
rtt min/avg/max/mdev = 0.068/0.084/0.201/0.032 ms
3.2 通過 Bridge 相連
Linux Bridge 相當于一台交換機,可以中轉兩個 namespace 的流量,我們看看 veth-pair 在其中扮演什麼角色。
如下圖,兩對 veth-pair 分别将兩個 namespace 連到 Bridge 上。
Linux 虛拟網絡裝置 veth-pair 詳解,看這一篇就夠了
同樣給 veth-pair 配置 IP,測試其連通性:
# 首先建立 bridge br0
ip l a br0 type bridge
ip l s br0 up
# 然後建立兩對 veth-pair
ip l a veth0 type veth peer name br-veth0
ip l a veth1 type veth peer name br-veth1
# 分别将兩對 veth-pair 加入兩個 ns 和 br0
ip l s veth0 netns ns1
ip l s br-veth0 master br0
ip l s br-veth0 up
ip l s veth1 netns ns2
ip l s br-veth1 master br0
ip l s br-veth1 up
# 給兩個 ns 中的 veth 配置 IP 并啟用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.060 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.105 ms
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.060/0.082/0.105/0.024 ms
3.3 通過 OVS 相連
OVS 是第三方開源的 Bridge,功能比 Linux Bridge 要更強大,對于同樣的實驗,我們用 OVS 來看看是什麼效果。
如下圖所示:
Linux 虛拟網絡裝置 veth-pair 詳解,看這一篇就夠了
同樣測試兩個 namespace 之間的連通性:
# 用 ovs 提供的指令建立一個 ovs bridge
ovs-vsctl add-br ovs-br
# 建立兩對 veth-pair
ip l a veth0 type veth peer name ovs-veth0
ip l a veth1 type veth peer name ovs-veth1
# 将 veth-pair 兩端分别加入到 ns 和 ovs bridge 中
ip l s veth0 netns ns1
ovs-vsctl add-port ovs-br ovs-veth0
ip l s ovs-veth0 up
ip l s veth1 netns ns2
ovs-vsctl add-port ovs-br ovs-veth1
ip l s ovs-veth1 up
# 給 ns 中的 veth 配置 IP 并啟用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.311 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.087 ms
^C
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.087/0.199/0.311/0.112 ms