消息中間件,說是一個通信元件也沒有錯,因為它的本職工作是做消息的傳遞。然而要做到高效的消息傳遞,很重要的一點是資料結構,資料結構設計的好壞,一定程度上決定了該消息元件的性能以及能力上限。
1. 消息中間件的實作方式概述
消息中間件實作起來自然是很難的,但我們可以從某些角度,簡單了說說實作思路。
它的最基本的兩個功能接口為:接收消息的發送(produce), 消息的消費(consume). 就像一個郵差一樣,經過它與不經過它實質性的東西沒有變化,它隻是一個中介(其他功能效應,咱們抛卻不說)。
為了實作這兩個基本的接口,我們就得實作兩個最基本的能力:消息的存儲和查詢。存儲即是接收發送過來的消息,查詢則包括業務查詢與系統自行查詢推送。
我們先來看第一個點:消息的存儲。
直接基于記憶體的消息元件,可以做到非常高效的傳遞,基本上此時的消息中間件就是由幾個記憶體隊列組成,隻要保證這幾個隊列的安全性和實時性,就可以工作得很好了。然而基于記憶體則必然意味着能力有限或者成本相當高,是以這樣的設計适用範圍得結合業務現狀做下比對。
另一個就是基于磁盤的消息元件,磁盤往往意味着更大的存儲空間,或者某種程度上意味着無限的存儲空間,因為畢竟所有的大資料都是存放在磁盤上的,前提是系統需要協調好各磁盤間的資料關系。然而,磁盤也意味着性能的下降,資料存放起來更麻煩。但rocketmq借助于作業系統的pagecache和mmap以及順序寫機制,在讀寫性能方面已經非常優化。是以,更重要的是如何設計好磁盤的資料據結構。
然後是第二個點:消息的查詢。
具體如何查詢,則必然依賴于如何存儲,與上面的原理類似,不必細說。但一般會有兩種消費模型:推送消息模型和拉取消費模型。即是消息中間件主動向消費者推送消息,或者是消費者主動查詢消息中間件。二者也各有優劣,推送模型一般可以展現出更強的實時性以及保持比較小的server端存儲空間占用,但是也帶來了非常大的複雜度,它需要處理各種消費異常、重試、負載均衡、上下線,這不是件小事。而拉取模型則會對消息中間件減輕許多工作,主要是省去了異常、重試、負載均衡類的工作,将這些工作轉嫁到消費者用戶端上。但與此同時,也會對消息中間件提出更多要求,即要求能夠保留足夠長時間的資料,以便所有合法的消費者都可以進行消費。而對于用戶端,則也需要中間件提供相應的便利,以便可以實作用戶端的基本訴求,比如消費組管理,上下線管理以及最基本的高效查詢能力。
2. rocketmq存儲模型設計概述
很明顯,rocketmq的初衷就是要應對大資料的消息傳遞,是以其必然是基于磁盤的存儲。而其性能如上節所述,其利用作業系統的pagecache和mmap機制,讀寫性能非常好,另外他使用順序寫機制,使普通磁盤也能展現出非常高的性能。
但是,以上幾項,隻是為高性能提供了必要的前提。但具體如何利用,還需要從重設計。畢竟,快不是目的,實作需求才是意義。
rocketmq中主要有四種存儲檔案:commitlog 資料檔案, consumequeue 消費隊列檔案, index 索引檔案, 中繼資料資訊檔案。最後一個中繼資料資訊檔案比較簡單,因其資料量小,友善操作。但針對前三個檔案,都會涉及大量的資料問題,是以必然好詳細設計其結構。
從總體上來說,rocketmq都遵從定長資料結構存儲,定長的最大好處就在于可以快速定位位置,這是其高性能的出發點。定長模型。
從核心上來說,commitlog檔案儲存了所有原始資料,所有資料想要擷取,都能從或也隻能從commitlog檔案中擷取,由于commitlog檔案保持了順序寫的特性,是以其性能非常高。而因資料隻有一份,是以也就從根本上保證了資料一緻性。
而根據各業務場景,衍生出了consumequeue和index檔案,即 consumequeue 檔案是為了消費者能夠快速擷取到相應消息而設計,而index檔案則為了能夠快速搜尋到消息而設計。從功能上說,consumequeue和index檔案都是索引檔案,隻是索引的次元不同。consumequeue 是以topic和queueId次元進行劃分的索引,而index 則是以時間和key作為劃分的索引。有了這兩個索引之後,就可以為各自的業務場景,提供高性能的服務了。具體其如何實作索引,我們稍後再講!
commitlog vs consumequeue 的存儲模型如下:
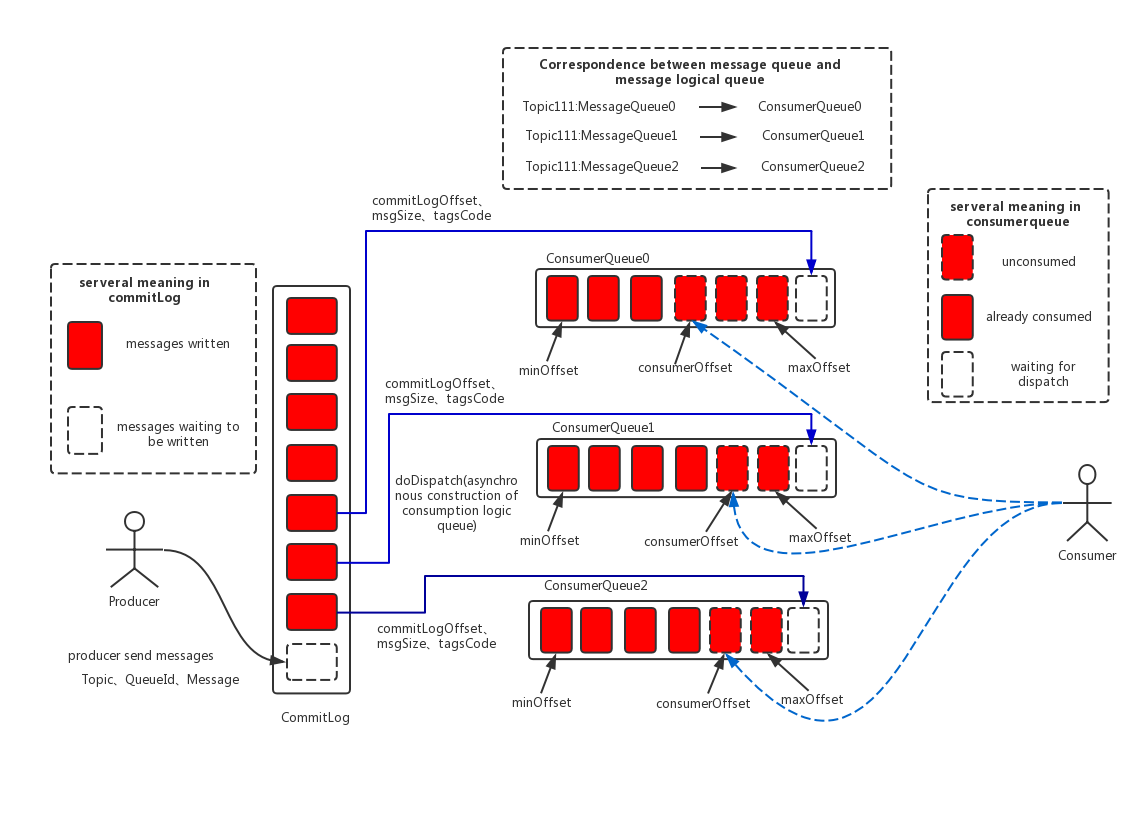
3. commitlog檔案的存儲結構
直接順序寫的形式存儲,每個檔案設定固定大小,預設是1G即: 1073741824 bytes. 寫滿一個檔案後,新開一個檔案寫入。檔案名就是其存儲的起始消息偏移量。
官方描述如下:
CommitLog:消息主體以及中繼資料的存儲主體,存儲Producer端寫入的消息主體内容,消息内容不是定長的。單個檔案大小預設1G ,檔案名長度為20位,左邊補零,剩餘為起始偏移量,比如00000000000000000000代表了第一個檔案,起始偏移量為0,檔案大小為1G=1073741824;當第一個檔案寫滿了,第二個檔案為00000000001073741824,起始偏移量為1073741824,以此類推。消息主要是順序寫入日志檔案,當檔案滿了,寫入下一個檔案;
當給定一個偏移量,要查找某條消息時,隻需在所有的commitlog檔案中,根據其名字即可知道偏移的資料資訊是否存在其中,即相當于可基于檔案實作一個二分查找,實際上rocketmq實作得更簡潔,直接一次性查找即可定位:
// org.apache.rocketmq.store.CommitLog#getData
public SelectMappedBufferResult getData(final long offset, final boolean returnFirstOnNotFound) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMappedFileSizeCommitLog();
// 1. 先在所有commitlog檔案中查找到對應所在的 commitlog 分片檔案
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset, returnFirstOnNotFound);
if (mappedFile != null) {
// 再從該分片檔案中,移動餘數的大小偏移,即可定位到要查找的消息記錄了
int pos = (int) (offset % mappedFileSize);
SelectMappedBufferResult result = mappedFile.selectMappedBuffer(pos);
return result;
}
return null;
}
// 查找偏移所在commitlog檔案的實作方式:
// org.apache.rocketmq.store.MappedFileQueue#findMappedFileByOffset(long, boolean)
// firstMappedFile.getFileFromOffset() / this.mappedFileSize 代表了第一條記錄所處的檔案位置編号
// offset / this.mappedFileSize 代表目前offset所處的檔案編号
// 那麼,兩個編号相減就是目前offset對應的檔案編号,因為第一個檔案編号的相對位置是0
// 但有個前提:就是每個檔案存儲的大小必須是真實的對應的 offset 大小之差,而實際上consumeQueue根本無法确定它存了多少offset
// 也就是說,隻要檔案定長,offset用于定位 commitlog檔案就是合理的
int index = (int) ((offset / this.mappedFileSize) - (firstMappedFile.getFileFromOffset() / this.mappedFileSize));
MappedFile targetFile = null;
try {
// 是以,此處可以找到 commitlog 檔案對應的 mappedFile
targetFile = this.mappedFiles.get(index);
} catch (Exception ignored) {
}
if (targetFile != null && offset >= targetFile.getFileFromOffset()
&& offset < targetFile.getFileFromOffset() + this.mappedFileSize) {
return targetFile;
}
// 如果快速查找失敗,則退回到周遊方式, 使用O(n)的複雜度再查找一次
for (MappedFile tmpMappedFile : this.mappedFiles) {
if (offset >= tmpMappedFile.getFileFromOffset()
&& offset < tmpMappedFile.getFileFromOffset() + this.mappedFileSize) {
return tmpMappedFile;
}
} 定位到具體的消息記錄位置後,如何知道要讀多少資料呢?這實際上在commitlog的資料第1個位元組中标明,隻需讀出即可知道。
具體commitlog的存儲實作如下:
// org.apache.rocketmq.store.CommitLog.DefaultAppendMessageCallback#doAppend
...
// Initialization of storage space
this.resetByteBuffer(msgStoreItemMemory, msgLen);
// 1 TOTALSIZE, 首先将消息大小寫入
this.msgStoreItemMemory.putInt(msgLen);
// 2 MAGICCODE
this.msgStoreItemMemory.putInt(CommitLog.MESSAGE_MAGIC_CODE);
// 3 BODYCRC
this.msgStoreItemMemory.putInt(msgInner.getBodyCRC());
// 4 QUEUEID
this.msgStoreItemMemory.putInt(msgInner.getQueueId());
// 5 FLAG
this.msgStoreItemMemory.putInt(msgInner.getFlag());
// 6 QUEUEOFFSET
this.msgStoreItemMemory.putLong(queueOffset);
// 7 PHYSICALOFFSET
this.msgStoreItemMemory.putLong(fileFromOffset + byteBuffer.position());
// 8 SYSFLAG
this.msgStoreItemMemory.putInt(msgInner.getSysFlag());
// 9 BORNTIMESTAMP
this.msgStoreItemMemory.putLong(msgInner.getBornTimestamp());
// 10 BORNHOST
this.resetByteBuffer(bornHostHolder, bornHostLength);
this.msgStoreItemMemory.put(msgInner.getBornHostBytes(bornHostHolder));
// 11 STORETIMESTAMP
this.msgStoreItemMemory.putLong(msgInner.getStoreTimestamp());
// 12 STOREHOSTADDRESS
this.resetByteBuffer(storeHostHolder, storeHostLength);
this.msgStoreItemMemory.put(msgInner.getStoreHostBytes(storeHostHolder));
// 13 RECONSUMETIMES
this.msgStoreItemMemory.putInt(msgInner.getReconsumeTimes());
// 14 Prepared Transaction Offset
this.msgStoreItemMemory.putLong(msgInner.getPreparedTransactionOffset());
// 15 BODY
this.msgStoreItemMemory.putInt(bodyLength);
if (bodyLength > 0)
this.msgStoreItemMemory.put(msgInner.getBody());
// 16 TOPIC
this.msgStoreItemMemory.put((byte) topicLength);
this.msgStoreItemMemory.put(topicData);
// 17 PROPERTIES
this.msgStoreItemMemory.putShort((short) propertiesLength);
if (propertiesLength > 0)
this.msgStoreItemMemory.put(propertiesData);
final long beginTimeMills = CommitLog.this.defaultMessageStore.now();
// Write messages to the queue buffer
byteBuffer.put(this.msgStoreItemMemory.array(), 0, msgLen);
... 可以看出,commitlog的存儲還是比較簡單的,因為其主要就是負責将接收到的所有消息,依次寫入同一檔案中。因為專一是以專業。
4. consumequeue檔案的存儲結構
consumequeue作為消費者的重要依據,同樣起着非常重要的作用。消費者在進行消費時,會使用一些偏移量作為依據(拉取模型實作)。而這些個偏移量,實際上就是指的consumequeue的偏移量(注意不是commitlog的偏移量)。這樣做有什麼好處呢?首先,consumequeue作為索引檔案,它被要求要有非常高的查詢性能,是以越簡單越好。最好是能夠一次性定位到資料!
如果想一次性定位資料,那麼唯一的辦法是直接使用commitlog的offset。但這會帶來一個最大的問題,就是當我目前消息消費拉取完成後,下一條消息在哪裡呢?如果單靠commitlog檔案,那麼,它必然需要将下一條消息讀入,然後再根據topic判定是不是需要的資料。如此一來,就必然存在大量的commitlog檔案的io問題了。是以,這看起來是非常快速的一個解決方案,最終又變成了非常費力的方案了。
而使用commitlog檔案的offset,則好了許多。因為consumequeue的檔案存儲格式是一條消息占20位元組,即定長。根據這20位元組,你可以找到commitlog的offset. 而因為consumequeue本身就是按照topic/queueId進行劃分的,是以,本次消費完成後,下一次消費的資料必定就在consumequeue的下一位置。如此簡單快速搞得定了。具體consume的存儲格式,如官方描述:
ConsumeQueue:消息消費隊列,引入的目的主要是提高消息消費的性能,由于RocketMQ是基于主題topic的訂閱模式,消息消費是針對主題進行的,如果要周遊commitlog檔案中根據topic檢索消息是非常低效的。Consumer即可根據ConsumeQueue來查找待消費的消息。其中,ConsumeQueue(邏輯消費隊列)作為消費消息的索引,儲存了指定Topic下的隊列消息在CommitLog中的起始實體偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue檔案可以看成是基于topic的commitlog索引檔案,故consumequeue檔案夾的組織方式如下:topic/queue/file三層組織結構,具體存儲路徑為:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同樣consumequeue檔案采取定長設計,每一個條目共20個位元組,分别為8位元組的commitlog實體偏移量、4位元組的消息長度、8位元組tag hashcode,單個檔案由30W個條目組成,可以像數組一樣随機通路每一個條目,每個ConsumeQueue檔案大小約5.72M;
其中fileName也是以偏移量作為命名依據,因為這樣才能根據offset快速查找到資料所在的分片檔案。
其存儲實作如下:
// org.apache.rocketmq.store.ConsumeQueue#putMessagePositionInfo
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
if (offset + size <= this.maxPhysicOffset) {
log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);
return true;
}
// 依次寫入 offset + size + tagsCode
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
final long expectLogicOffset = cqOffset * CQ_STORE_UNIT_SIZE;
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(expectLogicOffset);
if (mappedFile != null) {
if (mappedFile.isFirstCreateInQueue() && cqOffset != 0 && mappedFile.getWrotePosition() == 0) {
this.minLogicOffset = expectLogicOffset;
this.mappedFileQueue.setFlushedWhere(expectLogicOffset);
this.mappedFileQueue.setCommittedWhere(expectLogicOffset);
this.fillPreBlank(mappedFile, expectLogicOffset);
log.info("fill pre blank space " + mappedFile.getFileName() + " " + expectLogicOffset + " "
+ mappedFile.getWrotePosition());
}
if (cqOffset != 0) {
long currentLogicOffset = mappedFile.getWrotePosition() + mappedFile.getFileFromOffset();
if (expectLogicOffset < currentLogicOffset) {
log.warn("Build consume queue repeatedly, expectLogicOffset: {} currentLogicOffset: {} Topic: {} QID: {} Diff: {}",
expectLogicOffset, currentLogicOffset, this.topic, this.queueId, expectLogicOffset - currentLogicOffset);
return true;
}
if (expectLogicOffset != currentLogicOffset) {
LOG_ERROR.warn(
"[BUG]logic queue order maybe wrong, expectLogicOffset: {} currentLogicOffset: {} Topic: {} QID: {} Diff: {}",
expectLogicOffset,
currentLogicOffset,
this.topic,
this.queueId,
expectLogicOffset - currentLogicOffset
);
}
}
this.maxPhysicOffset = offset + size;
// 将buffer寫入 consumequeue 的 mappedFile 中
return mappedFile.appendMessage(this.byteBufferIndex.array());
}
return false;
}
當需要進行查找進,也就會根據offset, 定位到某個 consumequeue 檔案,然後再根據偏移餘數資訊,再找到對應記錄,取出20位元組,即是 commitlog資訊。此處實作與 commitlog 的offset查找實作如出一轍。
// 查找索引所在檔案的實作,如下:
// org.apache.rocketmq.store.ConsumeQueue#getIndexBuffer
public SelectMappedBufferResult getIndexBuffer(final long startIndex) {
int mappedFileSize = this.mappedFileSize;
// 給到用戶端的偏移量是除以 20 之後的,也就是說 如果上一次的偏移量是 1, 那麼下一次的偏移量應該是2
// 一次性消費多條記錄另算, 自行加減
long offset = startIndex * CQ_STORE_UNIT_SIZE;
if (offset >= this.getMinLogicOffset()) {
// 委托給mappedFileQueue進行查找到單個具體的consumequeue檔案
// 根據 offset 和規範的命名,可以快速定位分片檔案,如上 commitlog 的查找實作
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset);
if (mappedFile != null) {
// 再根據剩餘的偏移量,直接類似于數組下标的形式,一次性定位到具體的資料記錄
SelectMappedBufferResult result = mappedFile.selectMappedBuffer((int) (offset % mappedFileSize));
return result;
}
}
return null;
} 如果想一次性消費多條消息,則隻需要依次從查找到索引記錄開始,依次讀取多條,然後同理回查commitlog即可。即consumequeue的連續,成就了commitlog的不連續。如下消息拉取實作:
// org.apache.rocketmq.store.DefaultMessageStore#getMessage
// 其中 bufferConsumeQueue 是剛剛查找出的consumequeue的起始消費位置
// 基于此檔案疊代,完成多消息記錄消費
...
long nextPhyFileStartOffset = Long.MIN_VALUE;
long maxPhyOffsetPulling = 0;
int i = 0;
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
final boolean diskFallRecorded = this.messageStoreConfig.isDiskFallRecorded();
ConsumeQueueExt.CqExtUnit cqExtUnit = new ConsumeQueueExt.CqExtUnit();
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
// 依次取出commitlog的偏移量,資料大小,hashCode
// 一次循環即是取走一條記錄,多次循環則依次往下讀取
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
long tagsCode = bufferConsumeQueue.getByteBuffer().getLong();
maxPhyOffsetPulling = offsetPy;
if (nextPhyFileStartOffset != Long.MIN_VALUE) {
if (offsetPy < nextPhyFileStartOffset)
continue;
}
boolean isInDisk = checkInDiskByCommitOffset(offsetPy, maxOffsetPy);
if (this.isTheBatchFull(sizePy, maxMsgNums, getResult.getBufferTotalSize(), getResult.getMessageCount(),
isInDisk)) {
break;
}
boolean extRet = false, isTagsCodeLegal = true;
if (consumeQueue.isExtAddr(tagsCode)) {
extRet = consumeQueue.getExt(tagsCode, cqExtUnit);
if (extRet) {
tagsCode = cqExtUnit.getTagsCode();
} else {
// can't find ext content.Client will filter messages by tag also.
log.error("[BUG] can't find consume queue extend file content!addr={}, offsetPy={}, sizePy={}, topic={}, group={}",
tagsCode, offsetPy, sizePy, topic, group);
isTagsCodeLegal = false;
}
}
if (messageFilter != null
&& !messageFilter.isMatchedByConsumeQueue(isTagsCodeLegal ? tagsCode : null, extRet ? cqExtUnit : null)) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
continue;
}
SelectMappedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy);
if (null == selectResult) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.MESSAGE_WAS_REMOVING;
}
nextPhyFileStartOffset = this.commitLog.rollNextFile(offsetPy);
continue;
}
if (messageFilter != null
&& !messageFilter.isMatchedByCommitLog(selectResult.getByteBuffer().slice(), null)) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
// release...
selectResult.release();
continue;
}
this.storeStatsService.getGetMessageTransferedMsgCount().incrementAndGet();
getResult.addMessage(selectResult);
status = GetMessageStatus.FOUND;
nextPhyFileStartOffset = Long.MIN_VALUE;
}
if (diskFallRecorded) {
long fallBehind = maxOffsetPy - maxPhyOffsetPulling;
brokerStatsManager.recordDiskFallBehindSize(group, topic, queueId, fallBehind);
}
// 配置設定下一次讀取的offset偏移資訊,同樣要除以單條索引大小
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
long diff = maxOffsetPy - maxPhyOffsetPulling;
long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE
* (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
getResult.setSuggestPullingFromSlave(diff > memory);
... 以上即理論的實作,無須多言。
5. index檔案的存儲結構
index檔案是為搜尋場景而生的,如果沒有搜尋業務需求,則這個實作是意義不大的。一般這種搜尋,主要用于背景查詢驗證類使用,或者有其他同的有妙用,不得而知。總之,一切為搜尋。它更多的需要借助于時間限定,以key或者id進行查詢。
IndexFile(索引檔案)提供了一種可以通過key或時間區間來查詢消息的方法。Index檔案的存儲位置是:$HOME \store\index\${fileName},檔案名fileName是以建立時的時間戳命名的,固定的單個IndexFile檔案大小約為400M,一個IndexFile可以儲存 2000W個索引,IndexFile的底層存儲設計為在檔案系統中實作HashMap結構,故rocketmq的索引檔案其底層實作為hash索引。
IndexFile索引檔案為使用者提供通過“按照Message Key查詢消息”的消息索引查詢服務,IndexFile檔案的存儲位置是:$HOME\store\index\${fileName},檔案名fileName是以建立時的時間戳命名的,檔案大小是固定的,等于40+500W\*4+2000W\*20= 420000040個位元組大小。如果消息的properties中設定了UNIQ_KEY這個屬性,就用 topic + “#” + UNIQ_KEY的value作為 key 來做寫入操作。如果消息設定了KEYS屬性(多個KEY以空格分隔),也會用 topic + “#” + KEY 來做索引。
其中的索引資料包含了Key Hash/CommitLog Offset/Timestamp/NextIndex offset 這四個字段,一共20 Byte。NextIndex offset 即前面讀出來的 slotValue,如果有 hash沖突,就可以用這個字段将所有沖突的索引用連結清單的方式串起來了。Timestamp記錄的是消息storeTimestamp之間的差,并不是一個絕對的時間。整個Index File的結構如圖,40 Byte 的Header用于儲存一些總的統計資訊,4\*500W的 Slot Table并不儲存真正的索引資料,而是儲存每個槽位對應的單向連結清單的頭。20\*2000W 是真正的索引資料,即一個 Index File 可以儲存 2000W個索引。
具體結構圖如下:

那麼,如果要查找一個key, 應當如何查找呢?rocketmq會根據時間段找到一個index索引分版,然後再根據key做hash得到一個值,然後定位到 slotValue . 然後再從slotValue去取出索引資料的位址,找到索引資料,然後再回查 commitlog 檔案。進而得到具體的消息資料。也就是,相當于搜尋經曆了四級查詢: 索引分片檔案查詢 -> slotValue 查詢 -> 索引資料查詢 -> commitlog 查詢 。
具體查找實作如下:
// org.apache.rocketmq.broker.processor.QueryMessageProcessor#queryMessage
public RemotingCommand queryMessage(ChannelHandlerContext ctx, RemotingCommand request)
throws RemotingCommandException {
final RemotingCommand response =
RemotingCommand.createResponseCommand(QueryMessageResponseHeader.class);
final QueryMessageResponseHeader responseHeader =
(QueryMessageResponseHeader) response.readCustomHeader();
final QueryMessageRequestHeader requestHeader =
(QueryMessageRequestHeader) request
.decodeCommandCustomHeader(QueryMessageRequestHeader.class);
response.setOpaque(request.getOpaque());
String isUniqueKey = request.getExtFields().get(MixAll.UNIQUE_MSG_QUERY_FLAG);
if (isUniqueKey != null && isUniqueKey.equals("true")) {
requestHeader.setMaxNum(this.brokerController.getMessageStoreConfig().getDefaultQueryMaxNum());
}
// 從索引檔案中查詢消息
final QueryMessageResult queryMessageResult =
this.brokerController.getMessageStore().queryMessage(requestHeader.getTopic(),
requestHeader.getKey(), requestHeader.getMaxNum(), requestHeader.getBeginTimestamp(),
requestHeader.getEndTimestamp());
assert queryMessageResult != null;
responseHeader.setIndexLastUpdatePhyoffset(queryMessageResult.getIndexLastUpdatePhyoffset());
responseHeader.setIndexLastUpdateTimestamp(queryMessageResult.getIndexLastUpdateTimestamp());
if (queryMessageResult.getBufferTotalSize() > 0) {
response.setCode(ResponseCode.SUCCESS);
response.setRemark(null);
try {
FileRegion fileRegion =
new QueryMessageTransfer(response.encodeHeader(queryMessageResult
.getBufferTotalSize()), queryMessageResult);
ctx.channel().writeAndFlush(fileRegion).addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
queryMessageResult.release();
if (!future.isSuccess()) {
log.error("transfer query message by page cache failed, ", future.cause());
}
}
});
} catch (Throwable e) {
log.error("", e);
queryMessageResult.release();
}
return null;
}
response.setCode(ResponseCode.QUERY_NOT_FOUND);
response.setRemark("can not find message, maybe time range not correct");
return response;
}
// org.apache.rocketmq.store.DefaultMessageStore#queryMessage
@Override
public QueryMessageResult queryMessage(String topic, String key, int maxNum, long begin, long end) {
QueryMessageResult queryMessageResult = new QueryMessageResult();
long lastQueryMsgTime = end;
for (int i = 0; i < 3; i++) {
// 委托給 indexService 搜尋記錄, 時間是必備參數
QueryOffsetResult queryOffsetResult = this.indexService.queryOffset(topic, key, maxNum, begin, lastQueryMsgTime);
if (queryOffsetResult.getPhyOffsets().isEmpty()) {
break;
}
Collections.sort(queryOffsetResult.getPhyOffsets());
queryMessageResult.setIndexLastUpdatePhyoffset(queryOffsetResult.getIndexLastUpdatePhyoffset());
queryMessageResult.setIndexLastUpdateTimestamp(queryOffsetResult.getIndexLastUpdateTimestamp());
for (int m = 0; m < queryOffsetResult.getPhyOffsets().size(); m++) {
long offset = queryOffsetResult.getPhyOffsets().get(m);
try {
boolean match = true;
MessageExt msg = this.lookMessageByOffset(offset);
if (0 == m) {
lastQueryMsgTime = msg.getStoreTimestamp();
}
if (match) {
SelectMappedBufferResult result = this.commitLog.getData(offset, false);
if (result != null) {
int size = result.getByteBuffer().getInt(0);
result.getByteBuffer().limit(size);
result.setSize(size);
queryMessageResult.addMessage(result);
}
} else {
log.warn("queryMessage hash duplicate, {} {}", topic, key);
}
} catch (Exception e) {
log.error("queryMessage exception", e);
}
}
if (queryMessageResult.getBufferTotalSize() > 0) {
break;
}
if (lastQueryMsgTime < begin) {
break;
}
}
return queryMessageResult;
}
public QueryOffsetResult queryOffset(String topic, String key, int maxNum, long begin, long end) {
List<Long> phyOffsets = new ArrayList<Long>(maxNum);
long indexLastUpdateTimestamp = 0;
long indexLastUpdatePhyoffset = 0;
maxNum = Math.min(maxNum, this.defaultMessageStore.getMessageStoreConfig().getMaxMsgsNumBatch());
try {
this.readWriteLock.readLock().lock();
if (!this.indexFileList.isEmpty()) {
//從最後一個索引檔案,依次搜尋
for (int i = this.indexFileList.size(); i > 0; i--) {
IndexFile f = this.indexFileList.get(i - 1);
boolean lastFile = i == this.indexFileList.size();
if (lastFile) {
indexLastUpdateTimestamp = f.getEndTimestamp();
indexLastUpdatePhyoffset = f.getEndPhyOffset();
}
// 判定該時間段是否資料是否在該索引檔案中
if (f.isTimeMatched(begin, end)) {
// 建構出 key的hash, 然後查找 slotValue, 然後得以索引資料, 然後将offset放入 phyOffsets 中
f.selectPhyOffset(phyOffsets, buildKey(topic, key), maxNum, begin, end, lastFile);
}
if (f.getBeginTimestamp() < begin) {
break;
}
if (phyOffsets.size() >= maxNum) {
break;
}
}
}
} catch (Exception e) {
log.error("queryMsg exception", e);
} finally {
this.readWriteLock.readLock().unlock();
}
return new QueryOffsetResult(phyOffsets, indexLastUpdateTimestamp, indexLastUpdatePhyoffset);
}
// org.apache.rocketmq.store.index.IndexFile#selectPhyOffset
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
if (this.mappedFile.hold()) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
// 超出搜尋範圍,不處理
} else {
for (int nextIndexToRead = slotValue; ; ) {
if (phyOffsets.size() >= maxNum) {
break;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
// 依次讀出 keyHash+offset+timeDiff+nextOffset
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
// 根據檔案名可得到索引寫入時間
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
this.mappedFile.release();
}
}
} 看起來挺費勁,但真正處理起來性能還好,雖然沒有consumequeue高效,但有mmap和pagecache的加持,效率還是扛扛的。而且,搜尋相對慢一些,使用者也是可以接受的嘛。畢竟這隻是一個附加功能,并非核心所在。
而索引檔案并沒有使用什麼高效的搜尋算法,而是簡單從最後一個檔案周遊完成,因為時間戳不一定總是有規律的,與其随意查找,還不如直接線性查找。另外,實際上對于索引重建問題,搜尋可能不一定會有效。不過,我們可以通過擴大搜尋時間範圍的方式,總是能夠找到存在的資料。而且因其使用hash索引實作,性能還是不錯的。
另外,index索引檔案與commitlog和consumequeue有一個不一樣的地方,就是它不能進行順序寫,因為hash存儲,寫一定是任意的。且其slotValue以一些統計資訊可能随時發生變化,這也給順序寫帶來了不可解決的問題。
其具體寫索引過程如下:
// org.apache.rocketmq.store.index.IndexFile#putKey
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
if (this.indexHeader.getIndexCount() < this.indexNum) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
// 先嘗試拉取slot對應的資料
// 如果為0則說明是第一次寫入, 否則為目前的索引條數
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
// 直接計算出本次存儲的索引記錄位置
// 因索引條數隻會依次增加,故索引資料将表現為順序寫樣子,主要是保證了資料不會寫沖突了
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
// 按協定寫入内容即可
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
// 寫入slotValue為目前可知的索引記錄條數
// 即每次寫入索引之後,如果存在hash沖突,那麼它會寫入自身的位置
// 而此時 slotValue 必定存在一個值,那就是上一個發生沖突的索引,進而形成自然的連結清單
// 查找資料時,隻需根據slotValue即可以找到上一個寫入的索引,這設計妙哉!
// 做了2點關鍵性保證:1. 資料自增不沖突; 2. hash沖突自重新整理; 磁盤版的hash結構已然形成
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
} rocketmq 巧妙地使用了自增結構和hash slot, 完美實作一個磁盤版的hash索引。相信這也會給我們平時的工作帶來一些提示。
6. 寫在最後
以上就是本文對rocketmq的存儲模型設計的解析了,通過這些解析,相信大家對其工作原理也會有質的了解。存儲實際上是目前我們的許多的系統中的非常核心部分,因為大部分的業務幾乎都是在存儲之前做一些簡單的計算。
很顯然業務很重要,但有了存儲的底子,還何愁業務實作難?
不要害怕今日的苦,你要相信明天,更苦!