簡介
最近在upstream上, Johannes Weiner發了一個memdelay的patch, 主要是衡量系統記憶體的健康程度, 在對它進行分析和優化之後, 做了一個簡單的總結
memdelay是衡量一個系統(memcg)中記憶體的健康程度的一個監控系統, 可以用來評價一個memcg的limit是否設定得合理
主要功能
- 監控每個task因為記憶體短缺導緻的延遲
- 監控每個memcg因為記憶體短缺導緻的延遲
- 監控每個memcg因為記憶體短缺産生了多大的性能影響
為什麼需要它
在一個系統中, 能跑多少應用, 跑少了, 浪費記憶體, 跑多了, 性能下降, 多少是個合理的值, 是個比較難捉摸的事情, memdelay就是為此來做一個簡單的評估
一個很簡單的模型, 應用一共需要1g的記憶體, 如果提供了1g的記憶體給他, 那麼就什麼問題都沒有了, 但是實際情況中, 很多記憶體都是read_once, 是以為了提高使用率, 給他900m也是能跑的, 隻不過這些記憶體都分時複用了, 一般情況下, 給個800m, 也能跑, 700m也能跑, 分時複用得越厲害, 性能就會越差. 那麼臨界點是多少, 讓memdelay來告訴你
原理介紹
memdelay的思想很簡單, 就是在一個memcg中, 因為記憶體短缺引起的延遲除以任務實際運作時間的百分比. 如果系統記憶體很富裕的話, 這個時間基本上為0. 在記憶體很緊張的情況中, 這個百分比可以達到50%, 可以說系統一半時間在幹活, 一半時間在做記憶體這件事情上白忙.
主要設計結構
這個簡單介紹一下設計概要, 把cpu的運作狀态分3個種類
- MDS_NONE, 表示沒有任何記憶體造成的延遲
- MDS_SOME, 表示既有記憶體延遲, 又有其他延遲, 比如IO
- MDS_FULL, 隻有記憶體延遲
接口設計
memdelay的接口是memcg目錄下的檔案memory.memdelay,
cat memory.memdelay
18359583 17087353 1272230 (總的記憶體延遲 前台延遲 背景延遲)
0.46 0.11 0.03 (MDS_SOME狀态1分鐘, 5分鐘, 15分鐘, 百分比)
3.97 2.09 0.85 (MDS_FULL狀态1分鐘, 5分鐘, 15分鐘, 百分比) 百分比越高, 說明越多的時間花在了記憶體複用上, 對性能的影響比較大
那如何把cpu區分出這3種狀态, 那就是根據這個cpu上不同性質的task的數量來定
把每個task根據記憶體的狀況, 分别記成sleep, iowait, runnable, delayed, delayed_active, 分别表示的含義是
- sleep, task睡眠, 不在runqueue上
- iowait, 在等io
- runnable, 處于runqueue上
- delayed, 因為記憶體短缺, 目前沒在運作, 比如進入direct reclaim之後, 被排程出去了
- delayed_active, 因為記憶體短缺, 正在運作, 比如正在做direct reclaim
那麼如何判斷一個task是處于sleep, iowait, runnable, delayed, delayed_active中的哪種狀态呢, 這就需要在系統中, 記錄任務狀态的變化過程, 從代碼的實作角度簡單得來說, 就是在排程對task進行處理的時候插樁
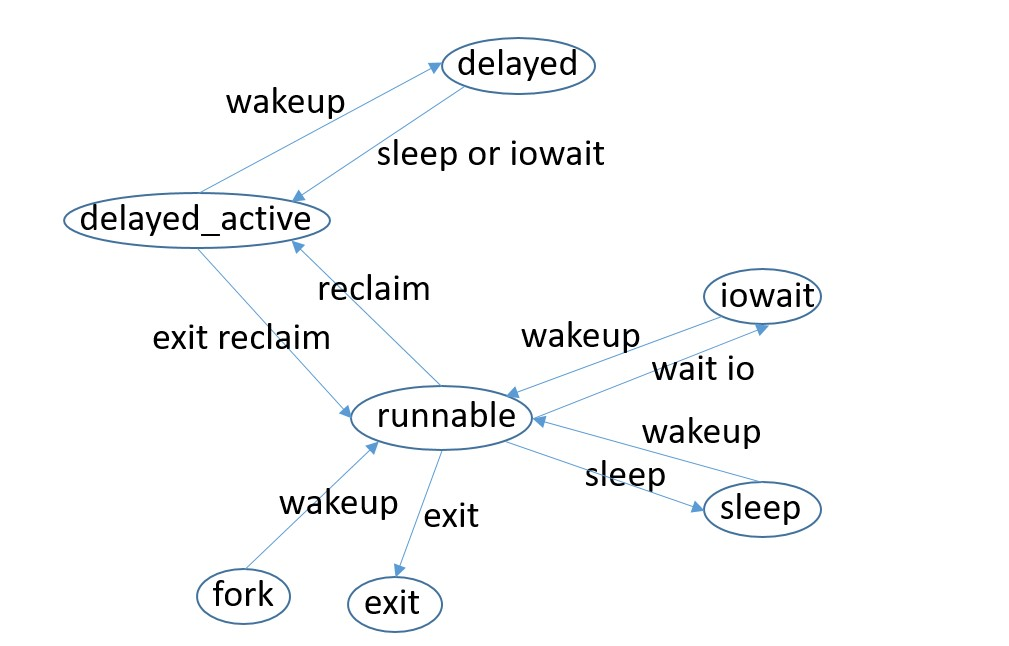
根據上面所訴的根據記憶體的使用情況來對task的狀态分類, 進而來确定cpu的狀态, 判斷規則如下
- 有delayed_active的任務下, 有iowait為MDS_SOME, 否則就是MDS_FULL
- 有delayed的任務下, 有runable或者iowait為MDS_SOME, 否則就是MDS_FULL
- 其他情況就是MDS_NONE
memcg記憶體延遲統計
每個memcg建立一個per cpu的資料結構memdelay_domain_cpu, 記錄cpu的這3種狀态, 每5s統計一次, 就可以計算出一個memcg裡面所有cpu, MDS_NONE占多少百分比, MDS_SOME占多少百分比, MDS_FULL占多少百分比, 就可以看出記憶體影響了多少的性能
測試檢驗
以下是從測試的角度來檢驗以下memdelay的功能
/sdk目錄下有17G的檔案, 用來準備做buffer io
time sh -c 'vmtouch -e /sdk/*; vmtouch -t /sdk/*' 在沒有memcg的限制的情況下, time結果, (memdelay的結果肯定全是0, 因為沒有前台延遲)
real 0m32.044s
user 0m1.192s
sys 0m9.052s 在把memcg限制到1G的情況下, time結果
real 0m36.561s
user 0m0.961s
sys 0m16.177s memdelay的結果
4191438 4191438 0
0.00 0.00 0.00
4.52 1.04 0.34 從上面的結果可以看出, memcg限制為1g的時候, 前台回收總共延遲了4s, 剛好是上面的32s到36s的差距, 4s/36s等于1/9, 也就是0.11, 在百分比的那一欄, 第一列是1分鐘的滑動平均, 因為隻跑了30s, 是以隻有一半, 4.52%也很好得展現了記憶體前台延遲對應用拖慢了多少性能
![測試基礎第一課[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)